六.聚集函数
使用聚集函数,可以方便的分析数据,主要有以下几种应用场景:
1.确定表的行数 (统计)
2.对某一列值进行求和
3.找出表的列 最大值,最小值 或平均值
特点: 使用聚集函数,返回的结果 是单行单列
用处:一般用于子查询 或 与分组搭配使用. 更多的是搭配分组使用
以下函数 distinct 为可选值
6.1 AVG([DISTINCT] expr) #求某一列平均值 会自动去除 内容为null 的列
例如:select avg(age) from student # 求 学生的平均年龄
6.2 COUNT([DISTINCT] expr) #统计某一列出现的行数 会自动去除 内容为null 的列
例如: select * from student # 统计共有多少条学生记录
6.3 MAX([DISTINCT] expr) #求出某一列的最大值
例如: select max(age) from student # 计算学生中最大的年龄是
6.4 MIN([DISTINCT] expr) #求出某一列的最小值
例如: select min(age) from student # 计算学生中最小的年龄是
max 与 min 通常用来查找 数值或日期的最 大/小 值
6.5 SUM([DISTINCT] expr) # 对某一列的所有值进行求和
例如: select sum(age) from student # 统计学生年龄的总和
六-2.数据分组
一般聚集函数都是与分组搭配使用,分组是按照某一特点 把表中的数据分成多个组,分组后分别再进行聚集操作
6.1 关键字 : group by cloum
select sex,count(*) as 总人数 from student group by sex #统计不同性别的人数
特点:先分组 再聚集
需注意:
1.虽然没有明确要求, 但是一般 用于分组的列 , 都要在 select 语句中查询出
2.关键字优先级: group by 必需在 where 语句之后 , order by 之前
3.group by 后不可跟聚集函数, 不可跟别名
4.如果分组中存在null值, 会将null单独作为一个分组. 如果有多个null ,可将多个null作为一个分组
6.2 过滤分组数据 HAVING
where 与 having 的区别
where 是对原始数据的每行数据进行过滤, 不存在分组的概念,
having 是对分组后的每组数的每一行进行的过滤
HAVING支持所有的 where子句中的操作符,语法完全一致 .
举个例子 :从学生表中分别统计男生,女生中 ,年龄在20岁以上的 人数,并且人数在5个以上
select sex,count(*) from student where age > 20 group by sex having count(*) > 5
having 后的表达式,必须是 select 后面出现的非别名的有效表达式,
6.3 分组后排序 按照人数进行排序 (各个关键字的顺序不可以错)
#having 后 可以使用 select 语句中的别名
例如:显示每个地区的总人口数和总面积.仅显示那些面积超过1000000的地区。
SELECT region, SUM(population), SUM(area)
FROM bbc
GROUP BY region
HAVING SUM(area)>1000000
6.4 关键字的顺序
从前至后: select , from , where , group by , having , order by ,limit
七 .子查询
从1个查询中,查询出的结果 ,被其他查询利用;
1.where 子句中的 子查询
假设现在有两个表 ,学生表 student (sid,sname...) 与 成绩表 score(id,sid,degree...)
成绩表中列出了每个学生的成绩,但是成绩表中只存储了 学生的id,并没有存储学生的姓名
先有一个需求,查询出任意一门成绩在90分以上的学生的sid 与 姓名
分析: 现在两张表中,没有一张表能同时包含,成绩 与 学生姓名,此时需要先从成绩表中查询出 大于90分的学生id集合
再从学生表中,查询出 id在上述查询结果集中的 学生的姓名即可
select sid,name from student where sid in ( select sid from score where score > 90)
如果要查询 90分以下的,则只需要再 in 前面加上 not 即表示否定
select sid,name from student where sid not in ( select sid from score where score > 90)
注意:
1.如需使用子查询,则要将子查询 用() 引起来
2.子查询可以嵌套多层, 凡涉及到的子查询 最好每个都要格式化显示, 便于阅读,上述SQL语句改造如下(虽然还是不好看.格式化语句在复杂的SQL语句时,显得格外重要)
select sid,name from student
where sid in (
select sid from score where score > 90)
3.sql的执行 总是从内向外执行
2.子查询作为计算字段
假设有两张表 , 客户表(customers)与订单表(orders) ,客户表 存放客户的相关信息, 主键为c_id ,
订单表存放客户c_id 与 客户所下的订单号
现有需求,需要显示每位客户的id, name ,与他们的订单总量
select c_id ,name, (
select count(*) from orders
where orders.c_id = customers.c_id ) AS order_count
from customers
如上所示, 将从订单表中查询的统计的数量作为计算字段, 进行展示
注意:
1.select子句作为计算字段, 必需要保证 子查询的行数与 外层 的行数保持一致 即没一行,都对应计算字段的一个值 ,不然会报错
2.因为from的优先级最高,因此可以在子句中访问到 customers的c_id ,但是两张表中都有c_id 这个字段,进行条件关联时,需要指明是哪个表下的(表明.列名)即完全限定名,否则会出现歧义
八.联结表
此章节后,所有的表均采用 <<sql必知必会 >> 书籍中所用的表与数据 , 构建表,去插入数据的脚本,请前往以下网址自行下载:http://www.forta.com/books/0672327120/

表之间的关联如下所示,即通过外键
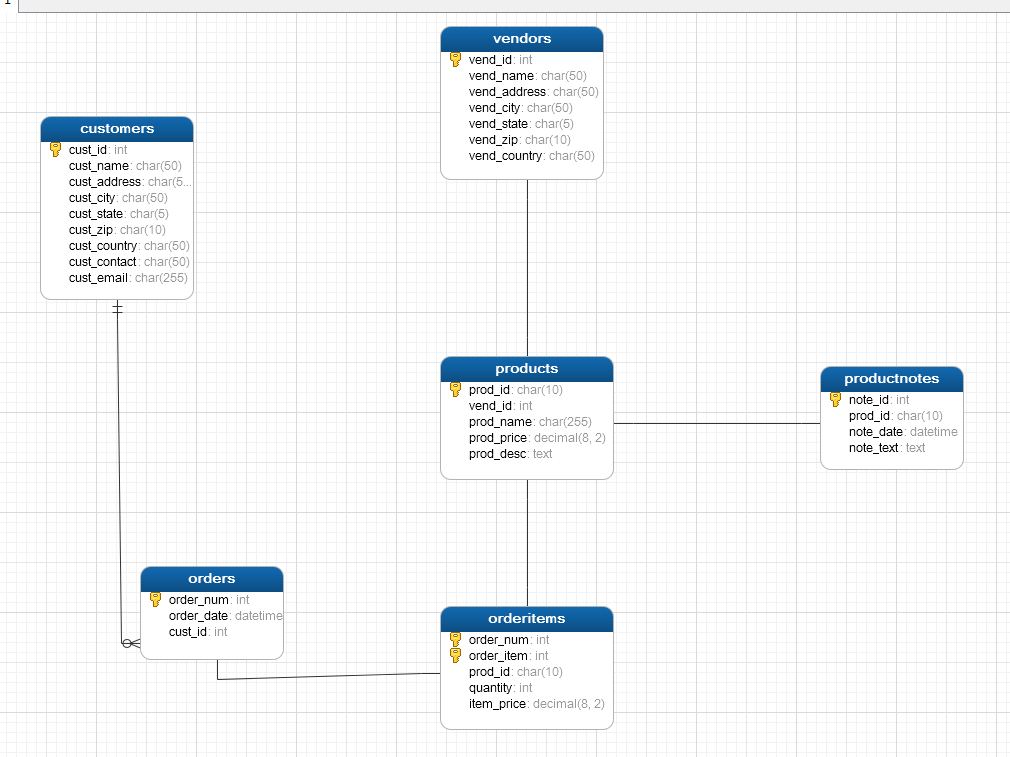
正如上面所提到的例子, 订单表,与客户表 ,往往两个关联的表之间都是 一个表中只保存着另一个表中的主键即可(即外键)
优势:
1.当表中更新了内容后, 不需要更改关联表,便于表的维护
2.减少了字段的冗余
3.表的专一性更强, 只保存某些信息
8.1.使用where 子句进行联结
例:查询产品名称,价格,供应商名称 关联条件 即 供应商id
select products.prod_name,products.prod_price,vendors.vend_name
from vendors, products
where vendors.vend_id = products.vend_id
只会筛选出 符合where 条件的记录
8.2 笛卡尔积
select * from vendors,products 如果么有建立where条件 , 这时查询出来的结果数 = vendors行数 * products 行数, 进行组合 这种现象叫做笛卡尔积
去除笛卡尔积就需要使用 where 条件进行表的联结
8.3 内部联结
使用where子句进行联结 为 等值联结. 可以更换为内联, 同样也是只匹配出 满足联结条件的数据 结果与 where条件联结 完全一致
其中inner 可以省略, 使用join 默认就是内联
关键字: table1 inner join table2 on 条件
select * from vendors inner join products on vendors.vend_id = products.vend_id
8.4 支持联结多张表
例如 : 订单明细表中会存储商品的ID ,此时可以 将 供应商, 商品,订单 三张表关联
select * from orderitems
inner join products on orderitems.prod_id = products.prod_id
inner join vendors on products.vend_id = vendors .vend_id
联结表时是非常消耗性能的,应当减少不必要的联结
8.5 联结时,也可以使用表的别名,优势:
1.缩短SQL
2.通过别名,允许在单句SQL中多次使用 相同的一张表
select * from vendors as v
inner join products as p
on v.v_id = p.v_id
8.6 自联结
即用一张表,关联自己
需求: prod_id 为 DTNTR 的产品存在质量问题,想知道该产品的供应商下的其他产品是否也存在质量问题
分析: 可以通过 prod_id = 'DTNTR ' 查询出 vend_id (供应商id) ,再根据 查询得到的 vend_id 得到所有的产品,因此可以使用子查询完成
select * from products
where vend_id = (
select vend_id from products where prod_id = 'DTNTR'
)
除了子查询外,还可以通过表的自联结来查询出 该供应商下的所有产品,
注意:因为要查询供应商下所有商品, 因此关联条件应该是供应商的id
select p1.* from products as p1 , products as p2
where p1.vend_id = p2.vend_id and p1.prod_id = 'DTNTR'
上述:p1.* 表示结果集中只显示 p1下的所有列, p2中的不予显示 ,这样就避免相同的列重复出现多次
8.7 外链接
外链接分为左外联 与 右外联
左联结:
需求:查看每位顾客的订单记录
由于存在顾客没有下过订单, 如果仍然使用内联接 ,就会导致检索出的顾客 不是全部顾客,也就是未能满足需求,此时需要用到外联结
方式1:使用左联结
select * from customers
left outer join orders
on customers.cust_id = orders.cust_id
方式2:使用右联结
select * from customers
right outer join orders
on customers.cust_id = orders.cust_id
特点:
1.左与右是相对概念 ,是针对 表在 outer join 语句的左右位置来判定的
2.其中left outer join 与 right outer join 中的 outer可以省略
3.要显示左边全部记录,则使用 left outer join 即可 ,同理要显示 右边表全部记录,则使用right outer join 即可
一张自制图表示inner join ,left outer join,right outer join
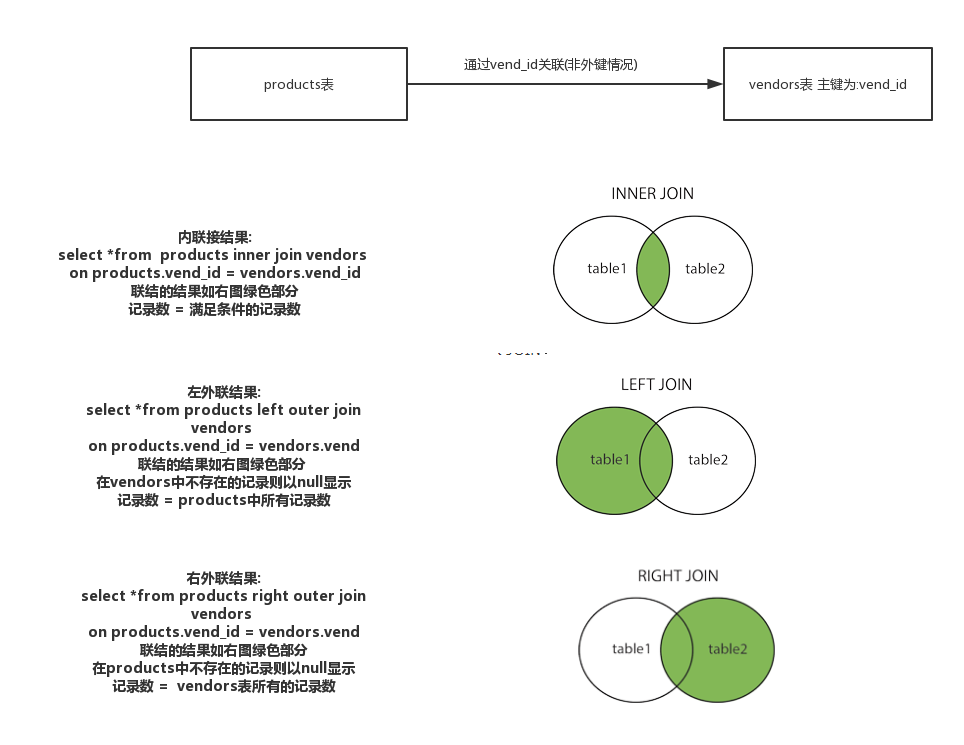
8.8 联结 后 使用聚集函数
需求: 查询出所有客户所下的订单数
所有客户即要检索出客户表中所有记录
select customers.cust_id,cust_name , COUNT(orders.order_num) as order_counts
from customers
left outer join orders
on customers.cust_id = orders.cust_id
GROUP BY customers.cust_id
小结:
1.平时需求中,更多的是使用内部联结,外部联结需要分清方向
2.联结时为了消除笛卡尔积 ,所有的连接都应使用 联结条件
3.联结条件要使用正确, 否则会出现很多错误的结果
九.组合查询
9.1 关键字: union
作用:将两个SQL语句执行的结果 ,组合在一起 进行返回,作用如下图所示

举个栗子:假如需要查询出价格小于等于5的所有物品的一个列表 ,同时包含供应商1001 和 1002 生产的所有产品(没有价格限制)
该需求可以使用where 条件句 使用 or 连接两个条件 来实现,如下所示:
select * from products
where prod_price <= 5 or
vend_id in (1001,1002)
order by vend_id
同样也可以使用 union 来完成,代码如下:
select * from products where prod_price <= 5
UNION
select * from products where vend_id in (1001,1002)
order by vend_id
union规则:
1.必需是两条或两条以上的select 子句之间使用union ,3个select语句 则 需要使用两次union
2.union 连接的两个select 结果集必需拥有相同数量的列,表达式,或聚集函数
3.结果集中 对应的列 ,必需保证数据可以兼容
9.2 union 与 union all
union 会自动去除重复的行,而 union all 则不会,因此union all的效率 要高于 union
如果需要显示所有的行,则应该使用union all
9.3 union 与 order by
如果要对 union后的结果进行排序 ,则只能在最后一个select 语句 末尾 加上 order by ,其他的 select语句则不能加!
union 可以使复杂的 sql 语句 阅读起来更加清晰,直观 , 必须要时应当使用 union 代替复杂的 where子句
十.全文本检索
10.理解全文本检索
并不是所有数据库存储引擎都支持全文本检索, mysql中最常用的搜索引擎为MyISAM和 InnoDB ,前者 MyISAM 引擎支持全文本检索,而mysql5.6版本之前,InnoDB不支持
在mysql5.6之后的版本innodb 引擎也开始支持
第八章给出的样例表中 :productnotes 的存储引擎为:MyISAM
之前的模糊匹配 like 关键字 利用 % 与 _ 匹配文本 , 如果满足不了需求,还可以使用 关键则 regexp 使用正则进行匹配更加复杂的值
但是使用like 与 regexp 都存在几个重要限制:
1.性能问题 : 通配符 与 正则表达式 ,通常会要求匹配表中所有的行(通常情况,检索的列基本都没有建立索引),随着数据不断的累积,行数不断的增加,耗时也会越来越久
2.明确控制: 使用通配 与 正则,很难控制同时 a.满足匹配关键字的条件 b.满足 排除关键字的条件
例如:我想要筛选 包含 Comment, 但是内容不包含vendor的行 虽然like 和 正则 可以轻松满足行中包含 comment关键字的要求,但是并不容易过滤掉包含vendor的内容
3.智能化结果 : 1个匹配 通常只会匹配到 满足关键字的行, 他不会关心,这个关键字出现了一次或是多次 .换言之如果一个关键字重复出现多次,可能匹配程度就越高,但是like 正则 只会默认的对结果进行展示,并不关心匹配的优先级
如果我的需求是 想要查询包含指定关键字的行, 同时 关键字出现在内容前端的 或者 关键字出现 多次的 会在结果集展示中排在靠前的位置 这种需求不是 like 与 regexp 能满足的
此时这种需求 可以使用全文本检索来实现 , 此时MySQL不需要分别查看每个行,不需要分别分析和处理每个词.MySQL可以快速有效地决定哪些词匹配
哪些词不匹配,他们的匹配频率等等...
10.2 使用全文本检索
两个关键字 match(希望检索的列名) , against(search_content)
在productnotes表中, 搜索出包含 rabbit 的行,此时语法为:
select note_text from productnotes
where match(note_text) against('rabbit')
结果如下:

同样也可以使用 like 进行查找
select note_text from productnotes where note_text like '%rabbit%'
结果如下:

乍一看,都能正确按照需求检索出满足条件的行, 仅仅是排序不一致而已;但是仔细看一下,就是这个排序有很大的关系
怎么说呢? like 查找出的结果集中, 第一行的尾部 包含 rabbit 关键字 , 第二行 是第四个单词就包含了 rabbit 关键字;
通常情况下,越靠前的那个更加是你想要找的那个结果,因此此时 全文检索相对 like 提供了排序的功能.并且在数据量越来越大的时候,能更明显的缩短检索所需的时间
此时变化一下我们的sql语句,将 match() against() 作为计算字段,如下:
select note_text ,match(note_text) against('rabbit') as rank from productnotes
得出的结果集为:
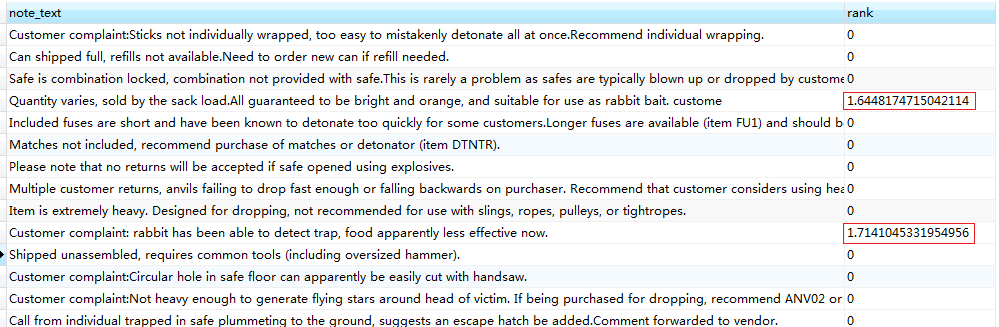
从结果可以看到, 不匹配的等级 rank 都为 0 ,匹配到两条记录rank值 都有1个大于0的值,而这个值 就表示了匹配的等级 ,等级值越大就表示该结果更可能是你想要的行,这一点是like所做不到的;
10.3 全文检索 之 查询扩展
查询拓展的目的是,设法放宽全文本检索搜索的结果范围
假如: 我想找到note_text 列中包含 anvils的内容, 但是只有一行内容包含 anvils ,但是我还想找出 与 这一行 内容非常相似的行 ,那我该怎么办呢?
此时就需要使用到 查询拓展, 他会帮你开启脑洞模式, 查询拓展会对 查询内容 与 索引 扫描两次 ,来完成这次检索:
首先:正儿八级的找出满足条件的所有行 (在这个例子中,满足条件的只有一行)
其次:MySQL 会检索出第一步筛选出来的行,找出这些行中 有用的词(有用的词这个标准由mysql自行判断)
最后:mysql 会根据 输入的关键字 和 第二步 得到的有用的词 ,再进行一遍检索, 将此次检索的结果集作为最终结果返回;
使用查询拓展的语法为: against(select_content WITH QUERY EXPANSION)
不使用查询拓展的结果如下:
select note_text from productnotes where MATCH(note_text) AGAINST('anvils')

使用查询扩展的结果如下:
select note_text from productnotes
where MATCH(note_text) AGAINST('anvils' WITH QUERY EXPANSION)

分析查询的结果:这次返回了7行. 第一行是包含我们要检索的内容 等级自然最高 ,第二行 虽然与anvils无关,但是他包含了第一行当中的两个单词 customer 与 recommend 所以也被检索了出来
同理第三行也包含了这两个相同的词.虽然mysql很智能的帮你筛选出来了一些与 你想查询结果 非常相近的结果,但是同时也极大的增多了返回的行数,更多的可能是你不想要的
所以视情况决定要不要使用查询拓展
10.4 全文检索 之 布尔文本搜索
格式 match(列名) against(search_content IN BOOLEAN MODE)
功能:
1.要匹配的词
2.要排斥的词
3.排列提示
4.表达式分组
5.另外一些内容
注意:
1.布尔文本搜索没有fulltext也可以使用,但是执行效率会降低
2.在正常的检索中默认会将结果集按照等级值降序排列,但布尔文本表达式中,不会对查询的结果按照等级值降序排列.
布尔操作符
+ 表示该词必需存在
- 排除,表示该词必须不能出现
> 包含,且出现该词增加等级值
< 包含,且出现该词降低等级值
() 多个操作符嵌套作用一个 或 一组词语
~ 取消一个词的排序值
* 词尾通配符,匹配任意个数的任意字符
"" 定义一个短语, 匹配与 包含 必需 是针对这个短语整体的操作
需求:查询productnotes中note_text 中 包含heavy 但不包含任意以 rope开头的单词
首先查询出所有包含 note_text 的记录
select note_text from productnotes
where match(note_text) AGAINST('heavy' IN BOOLEAN MODE)
共两条记录,结果如下:

此时第1条记录虽然包含了 heavy 但是同时也包含了 ropes , 这不是我们想要的,需要使用排除符 将其排除 ,使用语法如下:
select note_text from productnotes
where match(note_text) AGAINST('heavy -rope*' IN BOOLEAN MODE)
结果如下:

成功的排除了第一行包含ropes单词的记录...
其他操作符介绍:
无操作符
需求:检索出包含 rabbit 或 bait 的记录
select note_text from productnotes
where match(note_text) AGAINST('rabbit bait' IN BOOLEAN MODE)

+ : 必需包含
需求:检索出同时包含 rabbit 与 bait 的记录
select note_text from productnotes
where match(note_text) AGAINST('+rabbit +bait' IN BOOLEAN MODE)

"":双引号内 整体匹配 或 排除
需求:检索出 包含 ''rabbit bait" 整体的 记录
select note_text from productnotes
where match(note_text) AGAINST('"rabbit bait"' IN BOOLEAN MODE)
>: 出现该词会提高等级评分
< : 出现该词会降低等级评分
需求:检索出 包含 rabbit 或 carrot的记录, 并且 包含rabbit 的等级要高. carrot的优先级要降低
select note_text from productnotes
where match(note_text) AGAINST('>rabbit <carrot' IN BOOLEAN MODE)
():多个操作符嵌套作用一个 或 一组词语
需求:检索必需同时包含safe 和 combination 的记录.并且降低出现 combination 的等级
select note_text from productnotes
where match(note_text) AGAINST('+safe +(<combination)' IN BOOLEAN MODE)

10.5 全文检索 之 中文
由于中文分隔符的原因,不能很好的支持中文(日文)的全文检索, 可以说基本不支持 .
如果需要适配,提供简单思路:
1.内容中加上合适空格 逗号 或其他分隔符,
2.同时到配置文件my.ini文件 中修改最小检索长度,
ft_min_word_len = 2(ft_min_word_len 默认是4 )
修改后,保存文件 需重启mysql服务方能生效
查看当前ft_min_word_len 的值 ,使用命令 : SHOW VARIABLES LIKE 'ft_min_word_len'
最好是使用Apache组织 开发的 Lucene 全文检索工具类.
10.6 全文检索使用说明: