一.堆的概述
一个JVM实例只有一个堆内存,堆也是Java内存管理的核心区域,堆在JVM启动的时候创建,其空间大小也被创建,是JVM中最大的一块内存空间,所有线程共享Java堆,物理上不连续的逻辑上连续的内存空间,几乎所有的实例都在这里分配内存,在方法结束后,堆中的对象不会马上删除,仅仅在垃圾收集的时候被删除,堆是GC(垃圾收集器)执行垃圾回收的重点区域。
二.堆空间细分
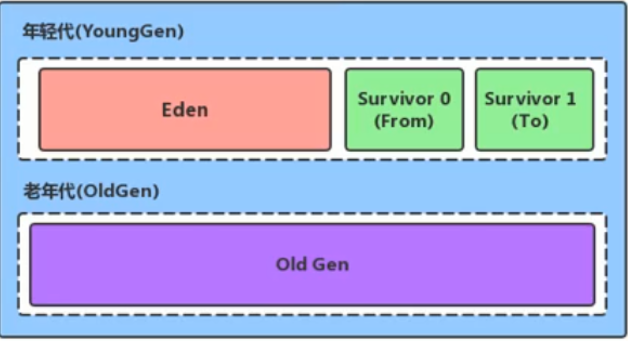
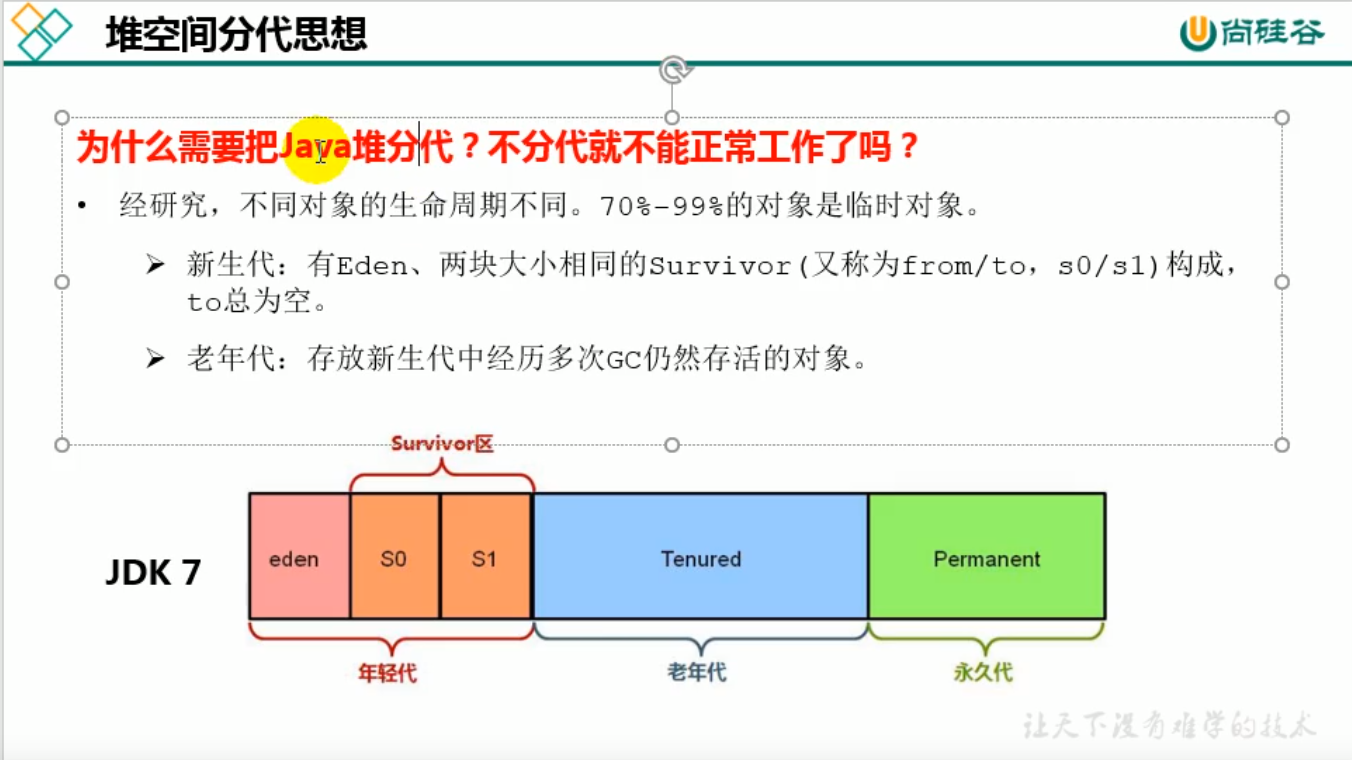
Java7及以前将堆空间逻辑上分成三部分:新生区+养老区+永久代
Java8及以后将堆内存逻辑上分为:新生区+养老区+元空间
新生代:
1.新生代使用了复制算法
2.新生代为gc的重点对象,经官方测试70%对象都生命周期都会在新生代中完结
3.新生代又分为了eden、survivor1、survivor2,对象创建先放在eden中,经过一定时间还幸存就会放在幸存者区
4.内存比例分默认为:8:1:1
5.新生代收集器:Minor GC/Young GC
eden(新生区)
当初始加载对象时会进入新生区
survivor(幸存区)
幸存区又分为from 和 to —谁为空谁为to ,始终都会有一个区域为空。
幸存区不会主动进行垃圾回收,只会eden回收时才会附带进行gc
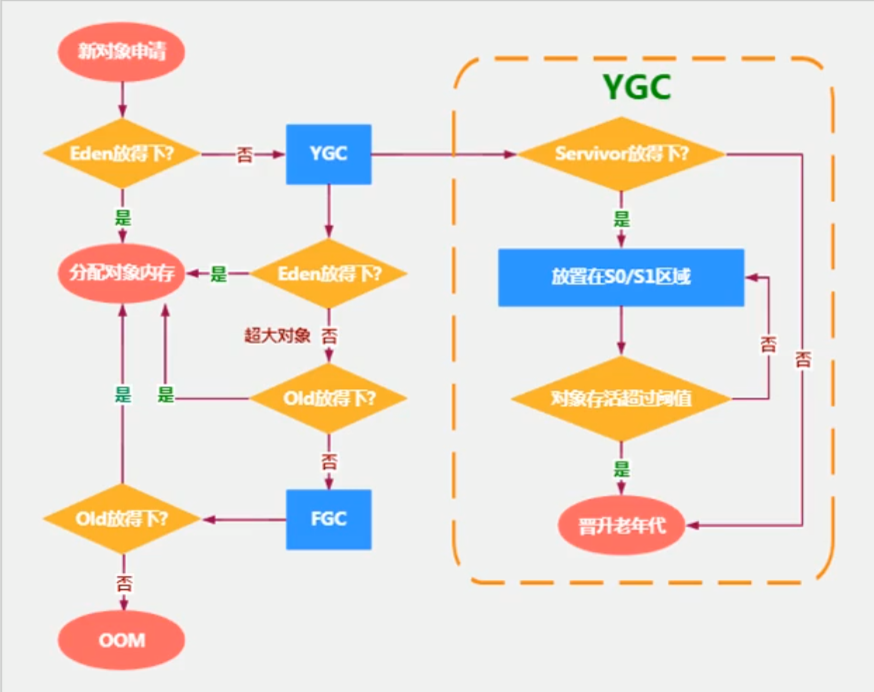
当在幸存区中的阈值达到了15后(默认15可修改)会自动进入老年代
当新生区(eden)出现了内存不足时,会进行YGC,那么会将没有指针的对象回收,还有指针引向的对象放入survivor1或者survivor2区域中,eden清空,数据放入一个survivor中。—当第二次进行gc那么会将eden数据放入另一个空的survivor中,并且将当前survivor中有效数据,放入空的survivor中,一次类推。
老年代
1.较大的对象数据会放入老年代
2.年代的数据都是相对于持久的不会频繁的gc
3.(MajorGC / Old GC) 在进行majorgc时会至少进行一次minorGc ,而且majorgc的效率是比minorGc 慢10倍的
4.老年代收集器:MajorGC / Old GC 要区分与Full GC
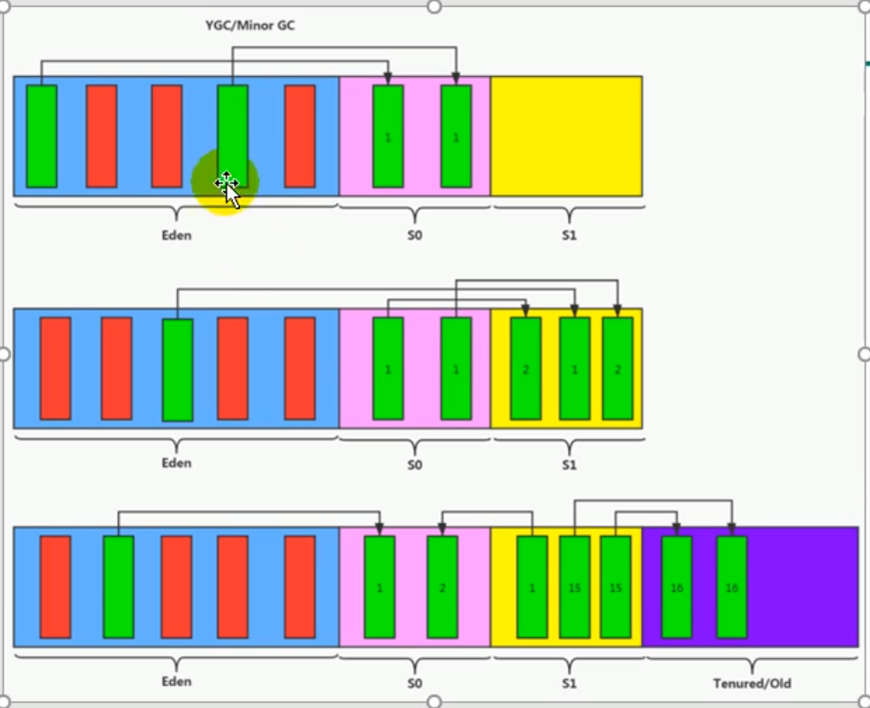
在一个对象进入内存时 会进入eden,如果满了(YGC进行回收没有引用的,如果还有引用的)会放入s1或者s0这就涉及到to from哪个为空就是to,(下次eden再次满了会将有数据的【举例s1】中 的数据放入s0,并且进行迭代版本)以此类推,当某个对象迭代阈值的次数达到默认15此后,(当然也会有特殊的优化:如当survivor区域中相同年龄的内存总和大于survivor的一半内存,会将大于等于平均年龄的对象提前放入老年代)会放入老年代 关于YGC 全程(YoungGC) 也可以为(Minor GC) s1,0是不会有单独的gc回收只会被动的依赖于eden的gc当eden进行gc时会自动回收s1,s0
yangGC只会在eden区满的时候进行,不会在survivor区满的时候进行,eden区GC时也会把survivor区进行GC,当survivor中age=15时会将数据放入老年区。
三为什么分代
四内存分配策略(或对象提升规则)
如果对象在EDEN出生并且经过一次MinnorGC后依然存活,并且能被Survivor容纳的话,将会被放在幸存者区,并将对象年龄设为1,每熬过一次MinnorGC,age增加一岁,当age增加到15时,会被放入老年代
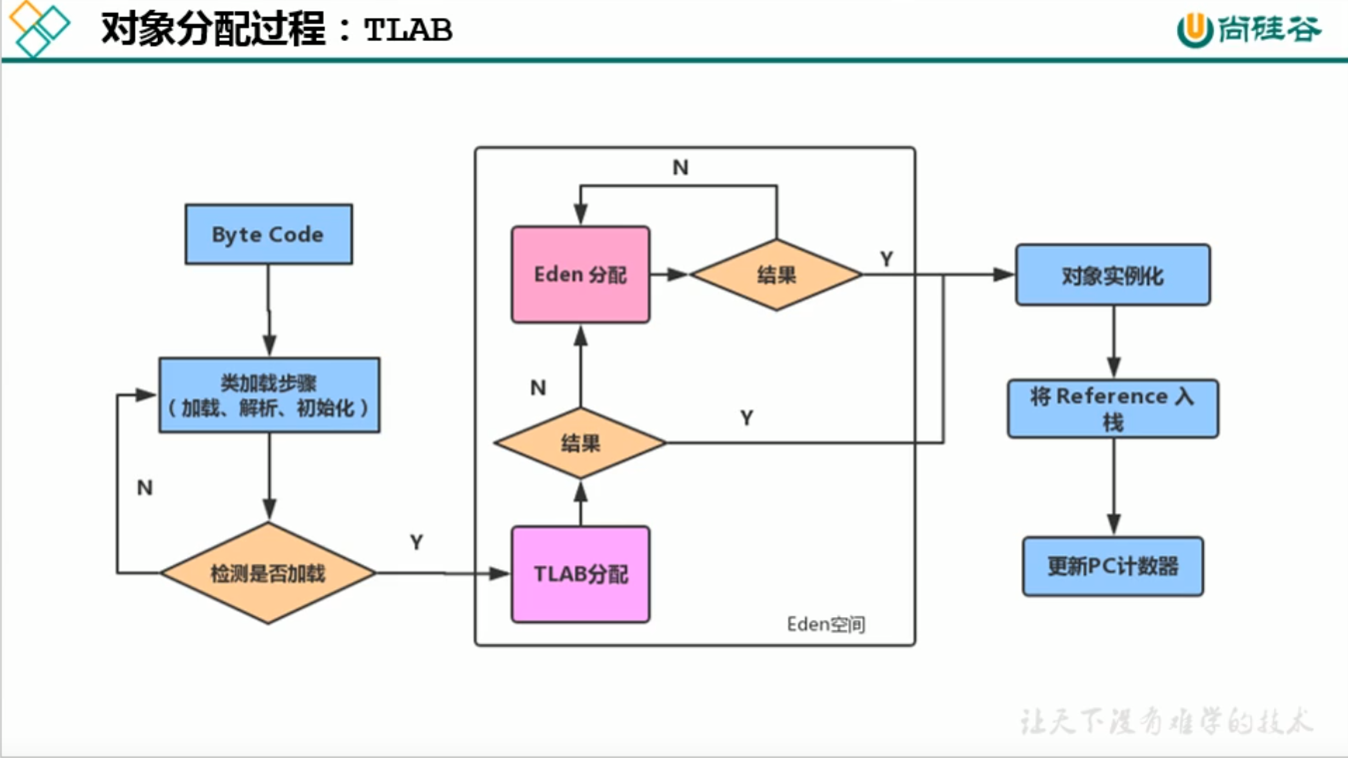
五.TLAB




六逃逸分析
什么是逃逸?
也就是如果在方法内创建对象,并且return进行传出,或者赋值到外部的变量,那么就进行了逃逸。
-XX:+DoEscapeAnalysis (JDK1.8之后默认开启)
-XX:+DoEscapeAnalysis(关闭)
逃逸分析包括以下
栈上分配
也就是将对象直接分配到栈上,跟随栈的消亡而消亡,减少了gc(栈中没有gc),提高了性能、速度。
同步省略
因为是每个栈独有的,一个栈也就是一个线程所以不存在同步安全的问题。
分离对象或者标量替换
扩充:一个类代表一个:聚合量,标量是无法分析的最小数据,聚合量可以分析为标量,也就是分析属性
也就是当加载一个pojo类时,不会创建对象而是,标量替换进行分析成一个个小的属性,减少了内存,提高了性能。
但是基于hotSpot 虚拟机这项技术并不成熟,因为还需要进行判断是否 属于逃逸,如果没有逃逸,可能会浪费了判断的时间等一些问题。
但是最后标量替换还是引用到了hotSpot虚拟机中
所以问题—所有的对象都是存储在堆空间中么?
回答:是的
总结
1.争对幸存者S0和S1区的总结:复制之后有交换,谁跟谁是to
2.关于垃圾回收:频繁在新生代中收集,很少在养老区收集,几乎不在永久代/元空间中收集
3.对象的执行流程