1.利用darknet53或者其他网络生成三个尺度的特征图,每个特征图都有(4+1+num_classes)个通道。
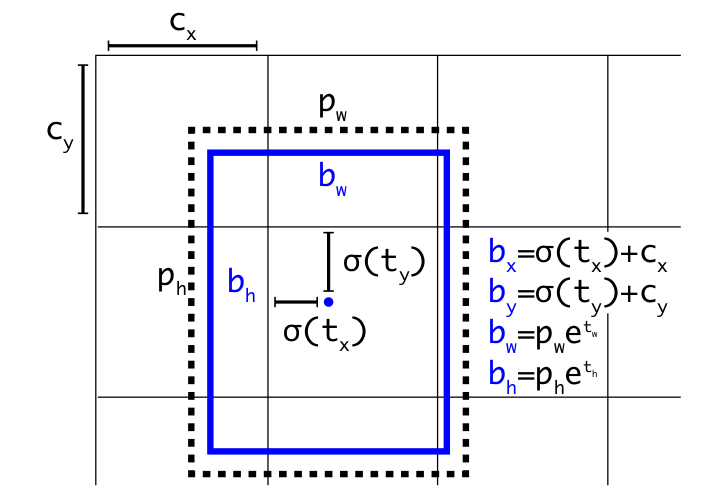
2.根据3种尺度的特征图进行预测框(预测框也分3个尺度进行),根据公式,激活函数sigmoid,t为卷积的结果,c为网格左上角坐标,b为预测的框。
3.损失主要分为3部分:
(1)giou_loss:
#增加了小目标的权重input_size为输入图片大小,label_xywh为真实框的大小,举例,假如框很小,bbox_loss_scale趋向于2,那么就增大了小框loss的权重。
giou = tf.expand_dims(self.bbox_giou(pred_xywh, label_xywh), axis=-1)
bbox_loss_scale = 2.0 - 1.0 * label_xywh[:, :, :, :, 2:3] * label_xywh[:, :, :, :, 3:4] / (input_size ** 2)
giou_loss = respond_bbox * bbox_loss_scale * (1- giou)
(2)置信度损失:就是确定预测框是背景还是前景框的
为了解决 one-stage 目标检测器在训练过程中出现的极端前景背景类不均衡的问题,引入Focal Loss。Focal Loss, 通过修改标准的交叉熵损失函数,降低对能够很好分类样本的权重(down-weights the loss assigned to well-classified examples),解决类别不均衡问题.
iou = self.bbox_iou(pred_xywh[:, :, :, :, np.newaxis, :], bboxes[:, np.newaxis, np.newaxis, np.newaxis, :, :])
# 找出与真实框 iou 值最大的预测框
max_iou = tf.expand_dims(tf.reduce_max(iou, axis=-1), axis=-1)
# 如果最大的 iou 小于阈值,那么认为该预测框不包含物体,则为背景框
respond_bgd = (1.0 - respond_bbox) * tf.cast( max_iou < self.iou_loss_thresh, tf.float32 )
conf_focal = self.focal(respond_bbox, pred_conf)
# 计算置信度的损失(我们希望假如该网格中包含物体,那么网络输出的预测框置信度为 1,无物体时则为 0)
conf_loss = conf_focal * (
respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox, logits=conv_raw_conf)
+
respond_bgd * tf.nn.sigmoid_cross_entropy_with_logits(labels=respond_bbox, logits=conv_raw_conf)
)
(3)类别损失:这里分类损失采用的是二分类的交叉熵,即把所有类别的分类问题归结为是否属于这个类别,这样就把多分类看做是二分类问题。
prob_loss = respond_bbox * tf.nn.sigmoid_cross_entropy_with_logits(labels=label_prob, logits=conv_raw_prob)