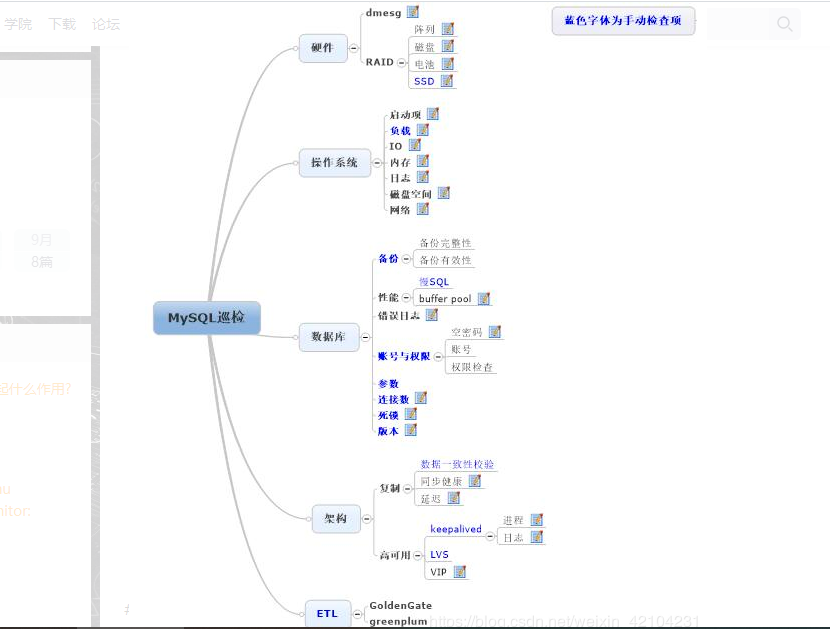
一 。操作系统巡检
如果有zabbix或者其他监控类型的工具,就方便了很多。首先看 CPU
内存 硬盘io的消耗程度。其中重点是硬盘使用率,要为十一小长假做好准备啊,避免十一期间业务写入增长,磁盘占满。每家业务不一样,所以参考标准不一样。
如果没有zabbix 建议使用 sar这个小工具,能够收集历史的信息。它的历史数据在/var/log/sa下面,通过 -f 来指定文件。举例
1.1 cpu资源监控
[root@mongodb01 data]# sar -u 10 3
Linux 2.6.32-642.el6.x86_64 (mongodb01) 09/22/2017 x86_64 (8 CPU)
10:26:44 AM CPU %user %nice %system %iowait %steal %idle
10:26:54 AM all 0.55 0.00 0.41 5.61 0.03 93.40
1.2 内存和交换空间监控
[root@mongodb01 data]# sar -r 10 3
Linux 2.6.32-642.el6.x86_64 (mongodb01) 09/22/2017 x86_64 (8 CPU)
10:28:36 AM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit
10:28:46 AM 223084 32658252 99.32 143468 16549080 18774068 37.81
1.3I/O和传送速率监控
[root@mongodb01 data]# sar -b 10 3
Linux 2.6.32-642.el6.x86_64 (mongodb01) 09/22/2017 x86_64 (8 CPU)
10:30:25 AM tps rtps wtps bread/s bwrtn/s
10:30:35 AM 67.17 61.63 5.54 16169.99 86.20```
1.4系统交换活动信息监控
[root@mongodb01 data]# sar -w 10 3
Linux 2.6.32-642.el6.x86_64 (mongodb01) 09/22/2017 x86_64
10:31:56 AM proc/s cswch/s
10:32:06 AM 0.00 2234.44`
当然还有其他的监控项目,就不一一赘述了,还需要查看当前的磁盘和内存使用情况df -h ,free -m,是否使用numa和swap 是否频繁交互 等信息。除此以外,还可以需要关注日志类信息
例如
[root@mongodb01 data]# ll /var/log/messages
[root@mongodb01 data]# ll /var/log/dmesg
MySQL error log
MySQL 慢查询日志 等信息
二。MySQL本身巡检
2.1重点参数
"innodb_buffer_pool_size"
"sync_binlog"
'binlog_format'
'innodb_flush_log_at_trx_commit':
'read_only':
'log_slave_updates'
'innodb_io_capacity'
'query_cache_type'
'query_cache_size'
'max_connections'
'max_connect_errors'
'server_id'
2.2MySQL的状态
例如每秒的tps,qps,提交了多少事物,回滚了多少事物,打开文件数,打开表数,连接数,```innodb buffer```使用率,锁等待等等
查看mysql状态
show full processlist
show global status
show engine innodb statusG
taill -f show.log
show status中的一些状态信息
wait 等待
Innodb_buffer_pool_wait_free
Innodb_log_waits
锁等待
Innodb_row_lock_current_waits
当前等待的待锁定的行数
Innodb_row_lock_waits
一行锁定必须等待的总时长
Table_locks_waited
表锁等待次数
mysql 锁监控
表级锁
Table_locks_waited
Table_locks_immediate
行级锁
Innodb_row_lock_current_waits 当前等待锁的行锁数量
Innodb_row_lock_time 请求行锁总耗时
Innodb_row_lock_time_avg 请求行锁平均耗时
Innodb_row_lock_time_max 请求行锁最久耗时
Innodb_row_lock_waits 行锁发生次数
等待事件
Innodb_buffer_pool_wait_free /Innodb_log_waits
临时表/临时文件
Created_tmp_disk_tables/Created_tmp_files
打开表/文件数
Open_files/Open_table_definitions/Open_tables
并发连接数
Threads_running /Threads_created/Threads_cached
Aborted_clients
客户端没有正确关闭连接导致客户端终止而中断的连接数
Aborted_connects
试图连接到mysql服务器而失败的连接数
Binlog
Binlog_cache_disk_use
使用临时二进制日志缓冲但超过 binlog_cache_size 值并使用临时文件
Binlog_cache_use
使用临时二进制日志缓冲的事务数量
Binlog_stmt_cache_disk_use
当非事务语句使用二进制日志缓存
Binlog_stmt_cache_use
使用二进制日志缓冲非事务语句数量
链接数
Connections
试图连接到(不管成不成功)mysql服务器的链接数
临时表
Created_tmp_disk_tables
服务器执行语句时在硬盘上自动创建的临时表的数量。是指在排序时,内存不够 用(tmp_table_size 小于需要排序的结果集),所以需要创建基于磁盘的临时表进 行排序
Created_tmp_files
服务器执行语句时自动创建的内存中的临时表的数量
索引
Handler_commit 内部交语句
Handler_rollback 内部 rollback语句数量
Handler_read_first 索引第一条记录被读的次数 如果高 它表明服务器正执行大量全索引扫描
Handler_read_key 根据索引读一行的请求数 如果较高 说明查询和表的索引正确
Handler_read_last 查询读索引最后一个索引键请求数
Handler_read_next 按照索引顺序读下一行的请求数
Handler_read_prev 按照索引顺序读前一行的请求数
Handler_read_rnd 根据固定位置读一行的请求数
如果值较高 说明可能使用了大量需要mysql扫整个表的查询或没有正确使用索引
Handler_read_rnd_next 在数据文件中读下一行的请求数
如果你正进行大量的表扫 该值会较高
innodb
Innodb_buffer_pool_wait_free
一般情况 通过后台想 innodb buffer pool 写
Innodb_log_waits
日志缓冲区太小 我们在继续前必须先等待对它的清空
Innodb_row_lock_current_waits 当前等待锁的行锁数量
Innodb_row_lock_time 请求行锁总耗时
Innodb_row_lock_time_avg 请求行锁平均耗时
Innodb_row_lock_time_max 请求行锁最久耗时
Innodb_row_lock_waits 行锁发生次数
Open_table_definitions
被缓存的.frm文件数量
Opened_tables
已经打开的表的数量 如果较大 table_open_cache 值可能太小
Open_tables
当前打开的表的数量
Queries
已经发送给服务器的查询个数
Select_full_join
没有使用索引的联接的数量 如果该值不为0 你应该仔细检查表的所有
Select_scan
对第一个表进行完全扫的联接的数量
Slow_queries
查询时间超过long_query_time秒的查询个数
Sort_merge_passes
排序算法已经执行的合并的数量
如果值较大 增加sort_buffer_size大小
线程
Threads_cached 线程缓存内的线程数量
Threads_connected 当前打开的连接数量
Threads_created 创建用来处理连接的线程数
Threads_running 激活的(非睡眠状态)线程数
2.3MySQL 是否有锁
如果有监控的话可以获取监控信息,或者其他工具,如果没有请定期收集MySQL锁信息
INFORMATION_SCHEMA.INNODB_LOCKS;
INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
2.4MySQ 自增id的使用情况
'SELECT table_schema,table_name,engine,Auto_increment FROM information_schema.tables whereINFORMATION_SCHEMA. TABLE_SCHEMA not in ("information_schema" ,"performance_schema","mysql")'
2.5 存储引擎是否为innodb
INFORMATION_SCHEMA.TABLES engine=innodb
2.6MySQL 主从检测
show slave status
2.6.1 主从状态
主从状态是否双yes
2.6.2 主从是否延迟
Master_Log_File == Relay_Master_Log_File && Read_Master_Log_Pos == Exec_Master_Log_Pos
三 高可用巡检
3.1.MHA && keepalived
观察日志看是否有频繁主从切换,如果有分析一下是什么原因进行频繁切换
3.2中间件的巡检
mycat && proxysql 这些中间价的巡检,首先参考系统巡检,在过看一下中间价本身的日志类,和状态类信息,网络延迟或丢包的检查,也是必须要做工作
总结
关于巡检来说,每个环境是不一样的,所以巡检的侧重点也是不一样的,但基本的巡检是避免不了的,如果有其他的巡检姿势也欢迎一起讨论