二进制运算:
&的应用:清零、得到指定位的数;
|的应用:将指定位置取1;
^的应用:取反、保留原值;交换两个bian变量:A= A^B,B =A ^ B,A = A^B;(原理就是本身异或本身=0,本身异或0=本身)
<</>>:左/右移,注意负数时:负数是通过该数的绝对值进行反码再加一变成补码表示;得到负数的表示形式后再将其进行左右移操作,后减一再进行反码,再取相反数即可,因此左/右移是不会改变数本身的正负的,而无符号左右移是有可能改变正负的;
<<</>>>:无符号左/右移
java转换进制:
十进制转换为别的进制:Integer.toxxxxx(xxx);将10进制xxx转换为几进制;
别的进制转换为二进制:Integer.parseInt("xxx",yyy);将yyy进制,值为xxx的数转换为十进制;
二进制的应用,当我们跨平台且平台的底层不是同种语言编写的时候,就可以通过将数据转换为字节进行表示沟通;

数据类型转换为字节有大端法和小端法,
小端法则低位字节放到低地址端,即该值内存起始地址,高位字节放到高地址段;
大端法则低位字节放到高地址端,而高位字节放到低地址段;
IO的输入和输出
gbk编码,文字占用两个字节,字母占用一个字节;(项目默认)
utf-8编码,中文占用三个字节,字母占用一个字节;
utf-16be编码,中文和字母都是占用两个字节;
因此,如果把想把字节数组转化为字符串或数字,只有应用相应的编码转换才能进行正确转换而不会出现乱码;
我们平时在电脑上创建的文本文件,默认使用的是ansi编码,因此当我们用另外的编码保存时,再打开就会出现乱码;(注意:这里并不是指文本文件工具只认识ansi编码,它本身是认识很多编码的,比如你用一个已写好的utf-8文件用文本文件打开,它也是不会乱码,只是在用它新创建文件的时候会默认ansi编码)
java.io.File;File类只表现文件(目录)的信息(名称、大小)
File file = new File("E:\javaio");访问E盘下的javaio;常用方法:
file.exists():判断文件是否存在;
file.mkdir()/file.mkdirs():如果文件不存在,则创造文件;/多级目录
file.delete();删除文件;
file.isDirectory();判断文件是否是目录;
file.isFile();判断文件是否是文件
file.getAbsolutePath();查找文件的绝对路径;
file.getName();查看文件的名字;
file.getParent();查看文件的父目录;
File类的过滤、遍历
file.list();返回的是字符串数组,是子的名称,不包含子目录下的内容;
如果要遍历子目录下的目录,我们返回的就不能是字符串数组,这样没法做递归;而要返回一个File对象;
File[] files = file.listFiles();返回直接子目录的文件对象数组;
通过遍历files,并判断files是否为目录,如是目录则再循环遍历,如是文件则打印输出,这样即可返回一个目录下所有子目录的子文件;
RandomAccessFile类是java提供对文件内容的访问,可读可写;支持随机访问,即访问文件的任意位置;
打开文件的模式有rw(读写)、r(只读)例:
RandomAccessFile raf = new RandomAccessFile(file,“rw”);
刚开始打开文件指针在开头;
常用的方法:
raf.write(int);只写一个字节(后8位);同时指针指向下一个位置;
int b = raf.read();只读一个字节
raf.getFilePointer();返回指针所在位置;
raf.seek(int);将指针放到所指位置;
文件读写完成后需关闭;
字节流
InputStream:抽象了应用程序读取数据的方式;
OutputStream:抽象了应用程序写出数据的方式;
EOF = End 读到-1就读到结尾
InputStream抽象类提供的方法:
int b =In.read():读取一个字节填充到int底八位中;
In.read(byte[] buf);读取数据填充到字节数组buf中
Inread(byte[] buf,int start,int size);读取数据填充到字节数组buf中,从buf字节数组的start位置开始,存放size长度的数据
在读取数据时,我们会把字节数组中的数读出来,但由于int是32位,我们写进字节数组中的只是int类中的底8位,所以可以通过&0xff对高24位进行清零;
OutputStream抽象类提供的方法:
Out.write(int b);写出一个byte到流,b的底八位;
Out.write(byte[] buf)将buf字节数组写入到流;
Out.write(byte[] buf , int start, int size);buf字节数组从start位置开始,写size长度的字节到流;
FileInputStream:InputStream的子类,具体实现了再文件上读取数据


需要注意的是FileOutputStream里的参数可以是(filename,[ture]);如果加了true,则表示是追加文件内容,如果没有参数true,则存在文件时,删除文件内容并添加新内容,如没文件,则创建文件并添加新内容;
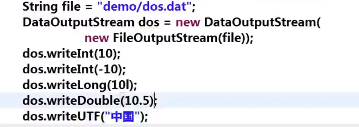
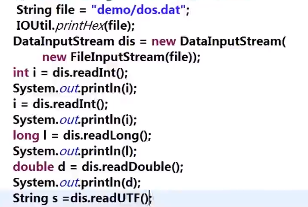
DataOutputStream/DataInputStream:对流进行扩展;
传入的参数是outputStream类/InputStream类,提供了一些可以直接传入不同类型的方法,而不需先将其传为字节数组后再传入,如:
outputStream类
InputStream类
BufferedInputStream/BufferedOutputStream类:这两个流类为IO提供了带缓冲区的操作;
在文件的读写效率上,批量带缓冲区的读写是比较高效的;
字符流:
文本:java 的文本是16位无符号整数,是字符的unicode编码(双字节编码)
文件是byte、byte、byte的数据序列;
文本文件:是将文本(char)按某种编码方案序列化成byte的存储;
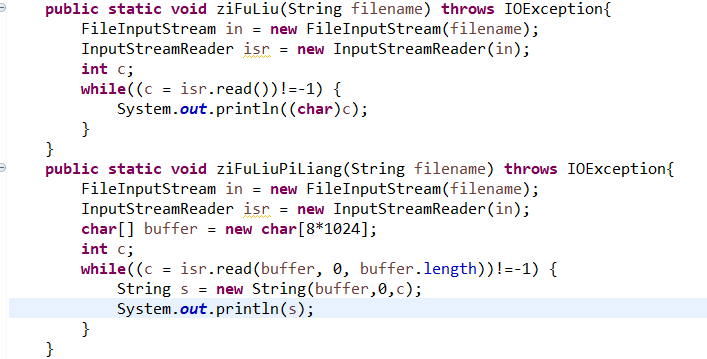
字符流(Reader类/ Writer类)
InputStreamReader类:完成了byte流解析为char流,按编码解析
OutputStreamWriter类:完成了char流到byte流,按编码解析
FileReader/FileWriter:直接创建了可用于字符流操作的对象,缺点是该类的创造函数并没有提供可以指定编码格式的方法,因此若要指定编码格式,还是需要用上述的InputStreamReader类;
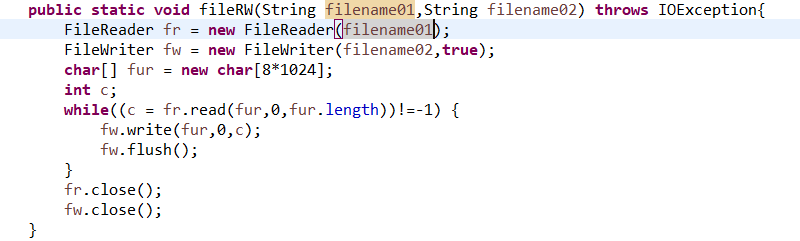
字符流过滤器:
BufferedReader------->readline:一次读一行;
BufferedWriter/PrintWriter--------->写一行;

注意,这两个类中的方法都不能识别换行,所以读的时候是用println,而写的时候用了write后,在后面需调用newLine()方法进行换行操作;
PrintWriter类在创建上会比较简洁,它可以直接加文件名进行创建:

写操作用的是println()可直接进行写并换行:

对象的序列化和反序列化:将Object转换成byte序列,反之就叫做对象 的反序列化;
序列化流(ObjectOutputStream),字节过滤流,常用方法有:writeObject();
反序列化流(ObjectInputStream),常用方法:readObject();
序列化接口(Serializable)
对象必需实现话序列化接口,才能进行序列化;
反序列化:

若对象的元素用transient修饰,则不会进行jvm默认的序列化,不过是可以自己完成这个元素的序列化;
序列化子父类的关系:
对子类进行反序列化操作时,如果父类没有实现序列化接口,那么父类的构造函数会被调用;