原文地址:https://zhuanlan.zhihu.com/p/92705250
1.跨模态检索的定义
在这篇文章中A Comprehensive Survey on Cross-modal Retrieval,作者给出了跨模态检索(Cross Modal Retrieval)的定义:It takes one type of data as the query to retrieve relevant data of another type。大概意思就是说,将一种类型的数据作为查询去检索另一种相关类型的数据。那么什么叫不同类型(different type or different modality)的数据呢?在文章Multimodal Machine Learning: A Survey and Taxonomy中,作者认为目前有主要的3种模态(modalities),分别是自然语言(写和说等)、视觉信号(图片和视频等)以及声音信号(对声音的编码以及韵律等)。在文章A Comprehensive Survey on Cross-modal Retrieval中,作者也给出了一个很直观的例子,a user can use a text to retrieve relevant pictures or videos(一个使用者使用文本去检索相关图片或视频)。这儿也有一张很直观的跨模态检索的框架图:
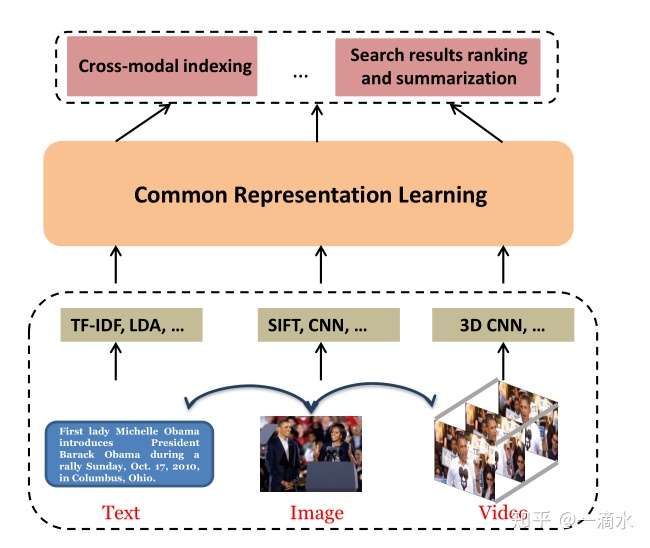
2.一些经典的方法
跨模态检索在方法上主要分为两大类,一类是实值表示学习(real-valued representation learning),另一类是二值表示学习(binary representation learning),也称为跨模态哈希方法。实值表示学习直接对从不同模态提取到的特征进行学习;而二值表示学习是对从不同模态提取到的特征先映射到汉明二值空间,然后在此空间中进行学习。
2.1.Real-valued representation learning
- Multimedia Content Processing through Cross-Modal Association,这篇文章中,作者提出了一种Cross-modal Factor Analysis(CFA)的方法来完成对语音和图像序列进行检索(
)。这是一种无监督学习的方法。
- A New Approach to Cross-Modal Multimedia Retrieval,这篇文章主要对文本和图片之间的检索进行研究(
),作者提出了一种CCA方法,利用典型相关分析的方法(canonical correlation analysis)用来学习text和image之间的相关性。大概方法就是将文本和图像从各自的原本的空间映射到CCA空间,然后利用距离(L1 距离和L2 距离)来对文本和图像的相似性进行刻画。这是一种无监督学习的方法。
- Multimodal Deep Learning,这篇文章中,作者第一次提出了采用深度学习的方法来处理多模态任务。
- Deep Canonical Correlation Analysis,这篇文章中,作者提出了一种DCCA(Deep Canonical Correlation Analysis)的框架,主要用来学习两种模态之间的非线性转换,使结果是高度线性相关的。这个方法可以看做前面介绍的CCA方法的非线性的扩展,也可以看做是KCCA(Kernel Canonical Correlation Analysis)的一种替换。但是这个方法的缺点是过度的占用内存、计算偏慢以及可能发生过拟合。
- Generalized Multiview Analysis: A Discriminative Latent Space,这篇文章作者提出了一种Generalized Multiview Analysis(GMA)的方法来完成文本和图像之间的检索(
- Multimodal Learning with Deep Boltzmann Machines,这篇文章主要对文本和图片之间的检索进行研究(
或
。
- Deep Correlation for Matching Images and Text,这篇文章中,作者提出了一种端对端的深度典型相关分析方法(End-to-End Deep Canonical Correlation Analysis)对文本和图片进行检索(
- Jointly Modeling Deep Video and Compositional Text to Bridge Vision and Language in a Unified Framework,这篇文章中,作者提出了一种统一的joint video-language model的框架来完成文本和视频之间的检索(
)。
- Cross-Modal Retrieval With CNN Visual Features: A New Baseline,这篇文章提出了一种deep semantic matching(deep-SM)的方法来完成文本和图像之间的检索(
- Look, Imagine and Match: Improving Textual-Visual Cross-Modal Retrieval with Generative Models,这是一篇利用GAN和Reinforcement Learning(RL)来进行跨模态检索的文章。文章中将生成过程结合到跨模态特征嵌入中,通过该方法我们不仅可以学习全局抽象特征还有局部层次特征。
- Webly Supervised Joint Embedding for Cross-Modal Image-Text Retrieval,在这篇文章中,作者认为目前的很多图像和文本之间的检索受到了小样本数据集的困扰,但是通常自己标注更大的数据集的话会很昂贵,故作者利用深度学习学习带有噪声的web数据集以此增加模型的鲁棒性。
- CAMP: Cross-Modal Adaptive Message Passing for Text-Image Retrieval,之前的大多数方法都是将图像和句子独立嵌入到一个联合空间,并比较它们的相似性。作者认为之前的那些方法在计算相似性之间很少考虑了图像和文本之间的相互关系。在这篇文章中,作者提出了一种Crossmodal Adaptive Message Passing(CAMP)方法来完成文本和图像之间的检索任务(
- Cross-Modal Interaction Networks for Query-Based Moment Retrieval in Videos,这篇文章中,作者提出了一个新型的Cross-Modal Interaction Network(CMIN)来完成文本和视频之间的检索(
2.2.Binary representation learning
- Large-Scale Supervised Multimodal Hashing with Semantic Correlation Maximization,作者提出了一种semantic correlation maximization (SCM)来完成文本和图像之间的检索(
- Semantics-Preserving Hashing for Cross-View Retrieval,在这篇文章中,作者提出了一种Semantics-Preserving Hashing method(SePH)的方法来完成文本和图像之间的检索(
- Deep Cross-Modal Hashing,在这篇文章中,作者首次将feature learning和hash-code learning结合到一个框架下,提出了端对端的deep cross-modal hashing(DCMH)方法。
- MTFH: A Matrix Tri-Factorization Hashing Framework for Efficient Cross-Modal Retrieval,作者在文中提到了hashing具有占内存小,查询速度快等优点。但作者认为,当前的跨模态哈希方法常常需要学习等长的哈希码来表示多模态数据,并使他们具有直观的可比性。因此作者提出了一种Matrix Tri-Factorization Hashing(MTFH)的方法来对不同数据进行不同长度的编码。
- Self-Supervised Adversarial Hashing Networks for Cross-Modal Retrieval,作者认为得益于深度学习的成功,导致了跨模态检索取得了飞速的发展,但是还是有一个主要的瓶颈:如何弥补模态之间的差异,进一步提高检索的精度。因此作者提出了self-supervised adversarial hashing (SSAH) 方法,即采用对抗+跨模态哈希结合的方法。
- Triplet-Based Deep Hashing Network for Cross-Modal Retrieval,在这篇文章中,作者认为现有的跨模态哈希方法由于忽略了包含丰富语义信息的异构数据之间的相对相似性,导致检索性能不佳,几乎所有的跨模态哈希方法都无法获得强大的哈希码。因此作者提出了一种tripletbased deep hashing network(TDH)的方法来完成文本和图像之间的检索(
注:上述文章的顺序都是按照提出时间进行排列的。
3.数据集
主要的数据集有
- Pascal VOC 2007:数据集包含9963张图片,每张图片有399个标签注释,一共有20个类别。
- NUS-WIDE:数据集包含269648张图片,每张图片包含81个真实的标签以及100个文本注释。
- Pascal Sentence:数据集是Pascal VOC的子集,包含1000对图像和文本的描述(有多个文本描述)。一共有20个类别,每个类别分别有50对图像和文本。
- Wikipedia:数据集包含2866对图片和文本的描述(只有1个描述),一共是10个类别。
- INRIA-Websearch:数据集包含71478对图像和文本的描述,一共有353个类别。
- Flickr8K:数据集是包含8000张图片,每张图片有5个注释。
- Flickr30K:是数据集Flickr8K的扩展,包含31784张图片,每张图片5个注释。
- IAPR TC-12:数据集包含20000张图片,每张图片用英语、德语和西班牙语这3种语言进行注释。
- MSCOCO:数据集包含123000张图片,每张图片采用5个文本进行注释。
- ActivityCaption:数据集包含20000个未经修剪的视频,每个视频都包含多个自然语言的描述。
- TACoS:数据集中只包含127个视频,虽然每个视频都有详细的文本标注,但是依旧缺乏多样性。