原文地址:https://zhuanlan.zhihu.com/p/24833574
一.前言
CNN作为一个著名的深度学习领域的“黑盒”模型,已经在计算机视觉的诸多领域取得了极大的成功,但是,至今没有人能够“打开”这个“黑盒”,从数学原理上予以解释。这对理论研究者,尤其是数学家来说当然是不可接受的,但换一个角度来说,我们终于创造出了无法完全解释的事物,这也未尝不是一种进步了!
当然,虽然无法完全“打开”这个“黑盒”,但是仍然出现了很多探索这个“黑盒”的尝试工作。其中一个工作就是今天我们讨论的重点:可视化CNN模型,这里的可视化指的是可视化CNN模型中的卷积核。
可视化工作分为两大类,一类是非参数化方法:这种方法不分析卷积核具体的参数,而是先选取图片库,然后将图片在已有模型中进行一次前向传播,对某个卷积核,我们使用对其响应最大的图片块来对之可视化;而另一类方法着重分析卷积核中的参数,使用参数重构出图像。
这一篇文章着重分析第一类可视化方法。
二.发展
最初的可视化工作见于AlexNet[1]论文中。在这篇开创Deep Learning新纪元的论文中,Krizhevshy直接可视化了第一个卷积层的卷积核:
 我们知道,AlexNet[1]首层卷积层(conv1)的filters是(96,3,11,11)的四维blob,这样我们就可以得到上述96个11*11的图片块了。显然,这些重构出来的图像基本都是关于边缘,条纹以及颜色的信息。但是这种简单的方法却只适用于第一层卷积层,对于后面的卷积核我们就无法使用这种方法进行直接可视化了。
我们知道,AlexNet[1]首层卷积层(conv1)的filters是(96,3,11,11)的四维blob,这样我们就可以得到上述96个11*11的图片块了。显然,这些重构出来的图像基本都是关于边缘,条纹以及颜色的信息。但是这种简单的方法却只适用于第一层卷积层,对于后面的卷积核我们就无法使用这种方法进行直接可视化了。
最开始使用图片块来可视化卷积核是在RCNN[2]论文中,

Girshick[2]的工作显示了数据库中对AlexNet模型较高层(pool5)某个channel具有较强响应的图片块;
之后,在ZFNet[4]论文中,系统化地对AlexNet进行了可视化,并根据可视化结果改进了AlexNet得到了ZFNet,拿到了ILSVRC2014的冠军。这篇文章可以视为CNN可视化的真正开山之作,我们下面将重点分析一下这一篇:[1311.2901] Visualizing and Understanding Convolutional Networks
然后再2015年,Yosinski[5]根据以往的可视化成果(包括参数化和非参数化方法)开发了一个可用于可视化任意CNN模型的toolbox:yosinski/deep-visualization-toolbox,通过简单的配置安装之后,我们就可以对CNN模型进行可视化了。
三.论文解读
Abstract
CNN模型已经取得了非常好的效果,但是正如前面所言,CNN在大多数人眼中,只是一个“黑盒”模型,它为什么表现得这么好,以及如何提升CNN的精度,这些都是不清楚的。这篇文章研究了这些问题。文中介绍了一种新的可视化方法,借助它,我们可以深入了解中间层和分类器的功能。通过使用类似诊断的方式,作者还得到了比AlexNet更好的结构:ZFNet;最后,作者还通过在ImageNet上训练,然后在其他数据集上进行fine-tuning,得到了非常好的结果。
1.Introduction
CNN在图像分类和物体检测领域大放异彩,主要是以下几项因素的作用:1).数以百万计带标签的训练数据的出现;2).GPU的强大计算能力,使得训练大的模型成为可能。
尽管如此,从科学的角度来看,这是令人很不满意的。因为我们并不能解释这个复杂的模型,也就不理解为什么它能达到这么好的效果,而不了解这个模型如何工作和为什么有作用,我们改进模型就只能使用试错法。这篇论文提出了一种新的可视化技术,揭示了模型中任意层的feature map与输入之间的响应关系。
2.Approach
2.1 Visualization with a Deconvnet
为了了解卷积操作,我们需要首先了解中间层的特征激活值。我们使用了一种新的方式将这些激活值映射回输入像素空间,表明了什么样的输入模式将会导致feature map中一个给定的激活值。我们使用反卷积网络来完成映射[6]。一个反卷积网络可以被看成是一个卷积模型,这个模型使用和卷积同样的组件(过滤和池化),但是却是相反的过程,因此是将特征映射到像素。在[6]中,反卷积网络被提出作为一种进行非监督学习的方法,但是在这里,它没有学习能力,仅仅用来探测一个已经训练好的卷积神经网络。
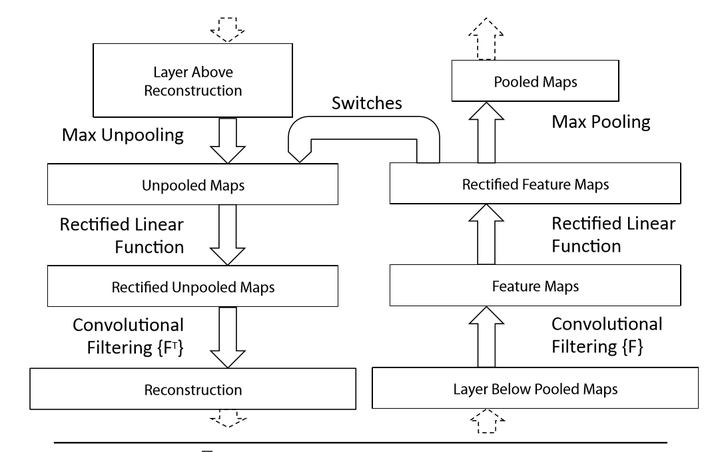
如上图所示,反卷积可视化以各层得到的特征图作为输入,进行反卷积,得到结果,用以验证显示各层提取到的特征图。为检验一个给定CNN的激活,我们就将该激活的feature map后接一个反卷积网络,然后通过:反池化、反激活、反卷积。重复上述过程直到原始输入层。
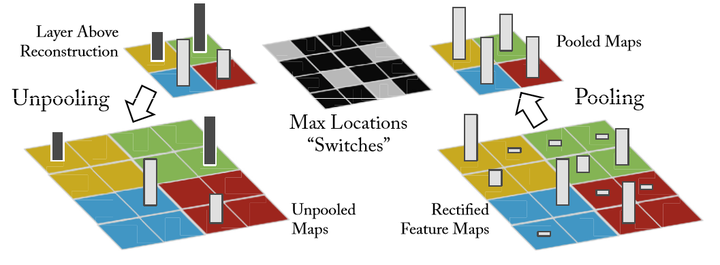
Unpooling:
在卷积神经网络中,max-pooling操作是不可逆的,然而我们可以通过一系列switch变量来记录池化过程中最大激活值的坐标位置。在反池化的时候,只把池化过程中最大激活值所在的位置坐标的值激活,其它的值置为0,当然这个过程只是一种近似,因为我们在池化的过程中,除了最大值所在的位置,其它的值也是不为0的。过程如下图所示:
 Rectification:
Rectification:
CNN使用ReLU确保每层输出的激活之都是正数,因此对于反向过程,我们同样需要保证每层的特征图为正值,也就是说这个反激活过程和激活过程没有什么差别,都是直接采用relu函数。
Filtering:
卷积过程使用学习到的过滤器对feature map进行卷积,为近似反转这个过程,反卷积使用该卷积核的转置来进行卷积操作
注意在上述重构过程中我们没有使用任何对比度归一化操作
3.Training Details
略
4.Convnet Visualization
使用前面描述的方法,现在我们使用在ImageNet验证集上使用反卷积进行特征图的可视化.
1.Feature Visualization:



以上就是对模型的可视化结果。对于一个给定的feature map,我们展示了响应最大的九张响应图,每个响应图向下映射到像素空间,揭示出其不同的结构激发映射并且揭示出其对输入变形的不变性。在这些可视化结果边上我们展示了对应的图片块。这些具有比仅仅关注图片块中判别结构的可视化具有更大的变化。例如,在layer5的第一行第二列,这些图片块似乎没有什么共同之处,但是从左边的可视化结果我们可以看出,这个特殊的feature map关注的是背景中的草,而不是前景中的物体。
来自每个层中的投影显示出网络中特征的分层特性。第二层响应角落和其他的边缘/颜色信息,层三具有更复杂的不变性,捕获相似的纹理,层四显示了显著的变化,并且更加类别具体化,层五则显示了具有显著姿态变化的整个对象。
---------------------------------------------------------------------------------------------------------------------------
这里的内容是这篇文章极其重要的贡献,虽然还是不能完全解释CNN这个黑盒,但是通过可视化,我们发现了CNN学习到的特征呈现分层特性,底层是一些边缘角点以及颜色的抽象特征,越到高层则越呈现出具体的特征,这一过程正与人类视觉系统类似。这也为如何得到更好的模型给出了指导,一个最简单的思路便是使网络更深,使得每层的特征更加层次分明,这样就能学到更加泛化的特征,后来的VGGNet以及ResNet则证明了这一点。上图中左侧的图像就是根据反卷积网络得到的结果,下面我们详细解释一下右侧的图片块是如何得到的。
首先我们介绍一下感受野(Receptive Field)[7]:
感受野是一个非常重要的概念,receptive field往往是描述两个feature maps A/B上神经元的关系,假设从A经过若干个操作得到B,这时候B上的一个区域只会跟a上的一个区域
相关,这时候
成为
的感受野。用图片来表示:
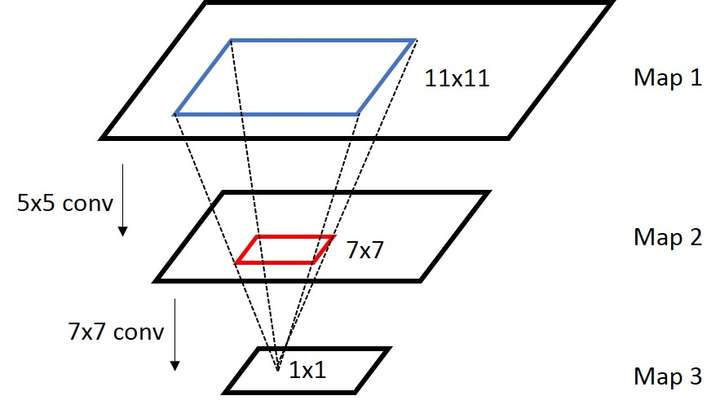 在上图里面,map3里1x1的区域对应map2的receptive field是那个红色的7x7的区域,而map2里7x7的区域对应于map1的receptive field是蓝色的11x11的区域,所以map3里1x1的区域对应map 1的receptive field是蓝色的11x11的区域。
在上图里面,map3里1x1的区域对应map2的receptive field是那个红色的7x7的区域,而map2里7x7的区域对应于map1的receptive field是蓝色的11x11的区域,所以map3里1x1的区域对应map 1的receptive field是蓝色的11x11的区域。
那么很容易得出来,receptive field的计算公式如下:
- 对于Convolution/Pooling layer:
其中表示第i层layer的输入的某个区域,
表示第i层layer的步长,
表示kernel size,注意,不需要考虑padding size。
- 对于Neuron layer(ReLU/Sigmoid/…)
很容易看出,除了不考虑padding之外,上述过程与反卷积计算feature map的尺寸的公式是一样的。
而上述计算图片块的过程正是应用了感知野的概念,我们举个例子:
 首先图片经过AlexNet做一次前向传播,之后在conv5层可以得到一个feature map,我们对这个feature map做一次max pooling,只保留其中响应最大的值(1x1),然后根据以上感受野的计算公式一路计算回输入图像中:
首先图片经过AlexNet做一次前向传播,之后在conv5层可以得到一个feature map,我们对这个feature map做一次max pooling,只保留其中响应最大的值(1x1),然后根据以上感受野的计算公式一路计算回输入图像中:
AlexNet结构如下:
 其中ReLU和LRN层感受野不会产生变化,所以我们只需要考虑pool层和conv层:
其中ReLU和LRN层感受野不会产生变化,所以我们只需要考虑pool层和conv层:
conv5:
conv4:
conv3:
pool2:
conv2:
pool1:
conv1:
所以,conv5层一个feature map中响应最大的值所对应的输入图中的感受野是163x163的尺寸,我们从原图中切割出163x163的图片块即可。这就是论文中图片块的来源。
---------------------------------------------------------------------------------------------------------------------------
2.Feature Evolution during Training:
 上图显示了训练过程中的特征演变,对于一个layer中给定的feature map,图中给出在训练epochs在[1,2,5,10,20,30,40,64]时,训练集对该feature map响应最大的可视化图片。可以看出,较低层(L1,L2)只需要几个epochs就可以完全收敛,而高层(L5)则需要很多次迭代,需要让模型完全收敛之后。这一点正好与深层网络的梯度弥散现象正好相反,但是这种底层先收敛,然后高层再收敛的现象也很符合直观
上图显示了训练过程中的特征演变,对于一个layer中给定的feature map,图中给出在训练epochs在[1,2,5,10,20,30,40,64]时,训练集对该feature map响应最大的可视化图片。可以看出,较低层(L1,L2)只需要几个epochs就可以完全收敛,而高层(L5)则需要很多次迭代,需要让模型完全收敛之后。这一点正好与深层网络的梯度弥散现象正好相反,但是这种底层先收敛,然后高层再收敛的现象也很符合直观
3.Feature Invariance:
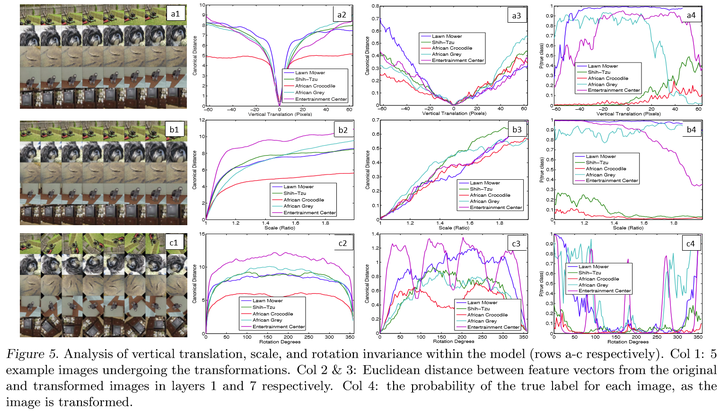 上图显示出了相对于未变换的特征,通过垂直平移,旋转和缩放的5个样本图像在可视化过程中的变化。小变换对模型的第一层有着显著的影响,但对顶层影响较小,对于平移和缩放是准线性的。网络输出对于平移和缩放是稳定的。但是一般来说,除了具有旋转对称性的物体来说,输出来旋转来说是不稳定的.(这说明了卷积操作对于平移和缩放具有很好的不变性,而对于旋转的不变性较差)
上图显示出了相对于未变换的特征,通过垂直平移,旋转和缩放的5个样本图像在可视化过程中的变化。小变换对模型的第一层有着显著的影响,但对顶层影响较小,对于平移和缩放是准线性的。网络输出对于平移和缩放是稳定的。但是一般来说,除了具有旋转对称性的物体来说,输出来旋转来说是不稳定的.(这说明了卷积操作对于平移和缩放具有很好的不变性,而对于旋转的不变性较差)
4.1 Architecture Selection

可视化训练模型不但可以洞察CNN的操作,也可以帮助我们在前几层选择更好的模型架构。通过可视化AlexNet的前两层(图中b,d),我们就可以看出问题:
1)第一层filter是非常高频和低频的信息,中间频率的filter很少覆盖
2)第二层的可视化有些具有混叠效应,由于第一层比较大的stride
为了解决这些问题:
1)将第一层的filter的尺寸从11*11减到7*7
2)缩小间隔,从4变为2。
这两个改动形成的新结构,获取了更多的信息,而且提升了分类准确率。
4.2 Occlusion Sensitivity
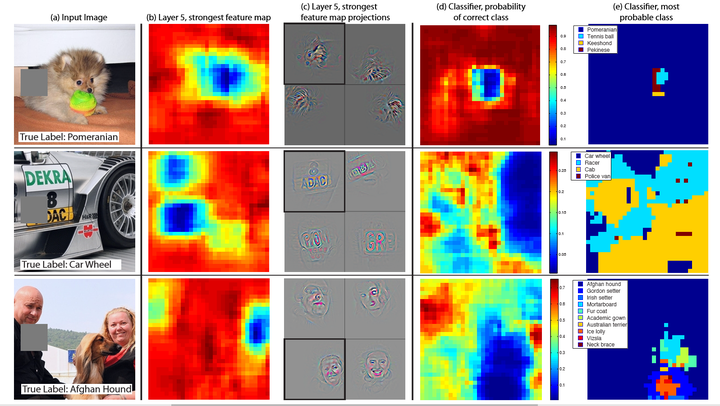
对于图片分类方法,一个自然的问题就是模型究竟是真正确定物体在图片中的位置,或者只是使用了周围的上下文信息,上图尝试通过使用一个灰色方形系统地遮挡输入图中的不同部分来回答这个问题,并监视分类器的输出。示例清楚地表明,模型是在场景中定位物体,因为当物体被遮挡住时被正确识别的概率显著下降了。
4.3 Correspondence Analysis
深度模型与许多现有的识别方法的区别在于,它没有用于建立不同图像中的特定对象部分之间的显式机制。然而,一个有趣的可能性是,深层模型可能隐式地计算它们。

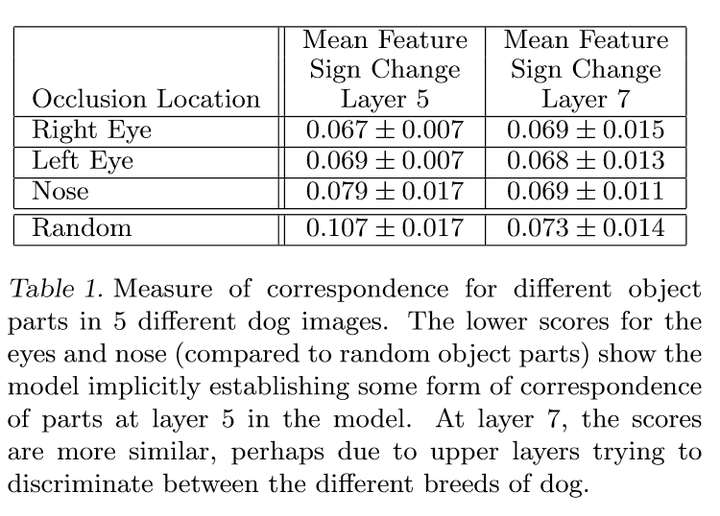
为了验证这一点,我们随机选择了5张包含狗正脸的图片;然后遮蔽相同的部分来观察。
观察方法:首先计算图片遮蔽前后特征,两个特征向量做差,通过sign来确定符号;然后通过海明距离来计算5张照片两两之间的一致性,然后求和。
由实验结果可以得出,layer5的特征一致性中,眼和鼻子的数值较低,说明眼和鼻子比其他部分,有更强的相关性,这也说明深度网络能够隐式地建立对应关系。但是在layer7中眼,鼻子和随机的数值较为相似,可能是因为高层尝试去区分狗的种类。
5 Experiments
略
四.可视化实践
论文终于解读完了,上述论文是Deep Learning发展中一篇很重要的论文,因为他尝试从可视化的角度去解释CNNs中的机制,通过各种实验也确实发现了很多有趣而重要的结论,如CNN中特征学习的分层性质,训练过程中的特征演变,CNN对于平移和缩放的不变性。
接下来我们使用[5]中的Deep Visualization toolbox对CNN进行可视化。
知乎专栏 首先我们按照这篇文章在VirtualBox Ubuntu14.04中安装配置好caffe,
1.Compile the deconv-deep-vis-toolbox branch of caffe
$ git remote add yosinski https://github.com/yosinski/caffe.git
$ git fetch --all
$ git checkout --track -b deconv-deep-vis-toolbox yosinski/deconv-deep-vis-toolbox
$ make clean
$ make -j
$ make -j pycaffe2.Install prerequisites
$ sudo apt-get install python-opencv scipy python-skimage3.Download and configure Deep Visualization Toolbox code
$ git clone https://github.com/yosinski/deep-visualization-toolbox
$ cd deep-visualization-toolbox$ cp models/caffenet-yos/settings_local.template-caffenet-yos.py settings_local.py然后我们修改settings_local.py中的caffe路径,改成我们的安装路径即可
$ vim settings_local.py$ cd models/caffenet-yos/
$ ./fetch.sh
$ cd ../..4.Run it
$ ./run_toolbox.py
不出意外的外,应该会出现这样的toolbox:
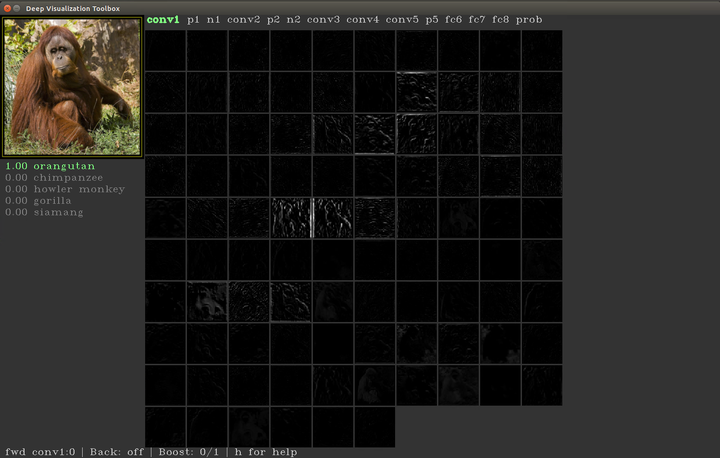 左上角是输入图片,中间的部分是对图片经过网络(这里是CaffeNet)进行前向传播之后得到feature map的可视化,我们可以通过上下左右控制光标移动,按'h'键可以查看按键的功能,我们尝试移动一下光标,看一下conv5的第151个feature map,
左上角是输入图片,中间的部分是对图片经过网络(这里是CaffeNet)进行前向传播之后得到feature map的可视化,我们可以通过上下左右控制光标移动,按'h'键可以查看按键的功能,我们尝试移动一下光标,看一下conv5的第151个feature map,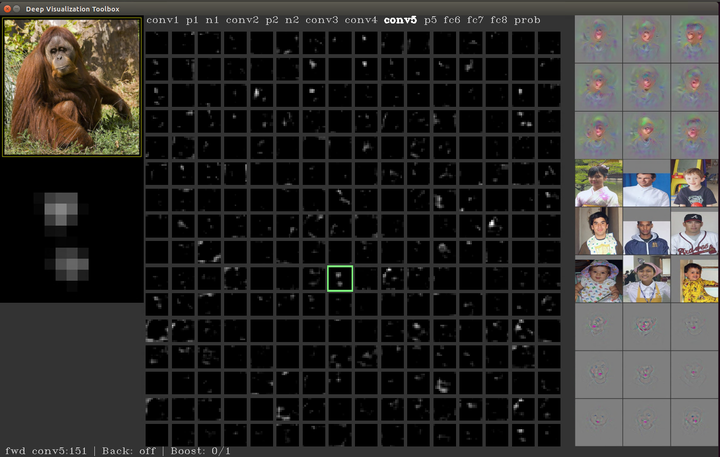 左边的中间区域是feature map的放大版本,右侧上方的九张图片是参数化的可视化方法(gradient ascent),这里暂且不提,右侧中间区域就是使用在上面提到的方法,得到的这个feature map的前9张响应图片块,下方是对这几张图片进行反卷积的结果
左边的中间区域是feature map的放大版本,右侧上方的九张图片是参数化的可视化方法(gradient ascent),这里暂且不提,右侧中间区域就是使用在上面提到的方法,得到的这个feature map的前9张响应图片块,下方是对这几张图片进行反卷积的结果
接下来,我们按‘b'键,对这个feature map进行反卷积,
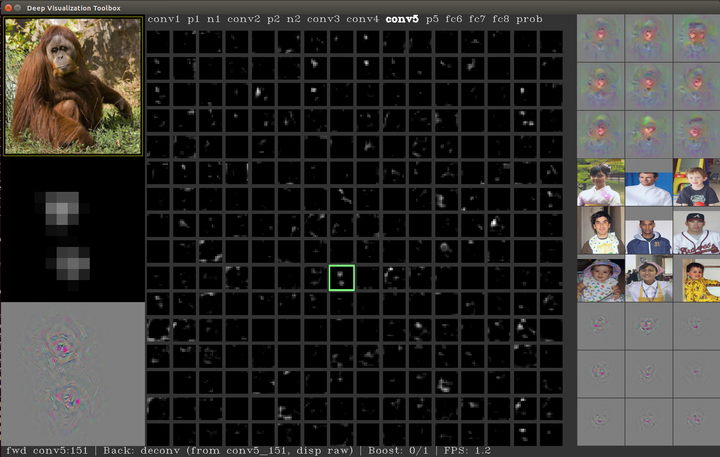 左下方出现的就是特征可视化的结果。
左下方出现的就是特征可视化的结果。
再使用'e’键,可以load下一幅图片,
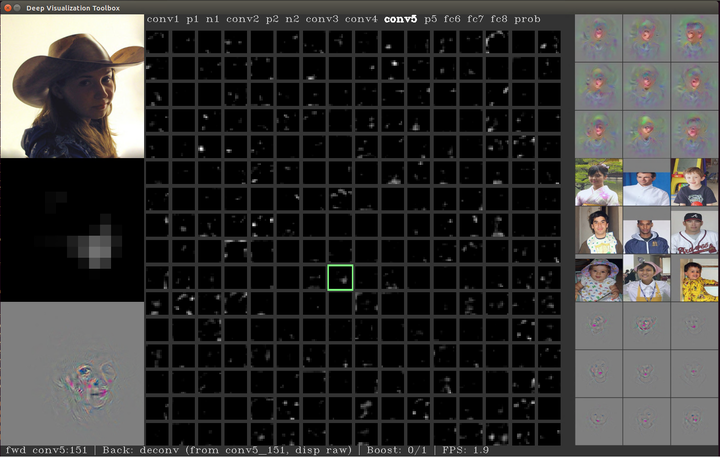 注意,右侧的结果是不会产生变化的,因为那些图片是提前计算好的。
注意,右侧的结果是不会产生变化的,因为那些图片是提前计算好的。
所以如果我们想使用这个工具可视化自己的CNN的话,我们需要:
1.提前准备好右边的图片(将数据集通过CNN,找出Top9张图片并将其deconv)
2.仿照model文件夹下文件,准备好相应model和配置文件
3.仿照settings_local.py编写settings_local.template-<your_network>.py
五.总结
通过非参数的可视化方法,我们从一定角度上探索了CNN这个“黑盒”,我们知道了CNN是从底层到高层,从抽象到具体来学习特征的,同时这个可视化也为我们改进网络结构提供了可能!
References
1. Krizhevsky, A., Sutskever, I., Hinton, G.: Imagenet classification with deep convolutional neural networks. In: NIPS (2012)
2. Girshick, R., Donahue, J., Darrell, T., Malik, J.: Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv:1311.2524 (2014)
3. Y. LeCun, B. Boser, J.S. Denker, D. Henderson, R.E. Howard, W. Hubbard, L.D. Jackel, et al. Hand-written digit recognition with a back-propagation network. In Advances in neural information processing systems, 1990.
4. Zeiler, Matthew D and Fergus, Rob. Visualizing and understanding convolutional neural networks. arXiv preprint arXiv:1311.2901, 2013.
5. J. Yosinski, J. Clune, A. M. Nguyen, T. Fuchs, and H. Lipson, “Understanding neural networks through deep visualization,” CoRR, vol. abs/1506.06579, 2015.
6. Zeiler, M., Taylor, G., Fergus, R.: Adaptive deconvolutional networks for mid and high level feature learning. In: ICCV (2011)
7. Marcher:Concepts and Tricks In CNN