前言
上一篇我们从整体上讲述了MyBatis的整个工作流程,也知道了我们在执行Sql之前,需要先获取SqlSession对象,但是我们也提到了SqlSession下面还有四大对象,所以SqlSession只是个甩手掌柜,真正干活的却是Executor等四大对象:Executor,StatementHandler,ParameterHandler,ResultSetHandler。那么本篇文章就让我们来仔细分析一下这四大对象。
MyBatis架构分层
首先我们先来建立一个MyBatis的整体认知,下面就是MyBatis的一个整体分层架构图:
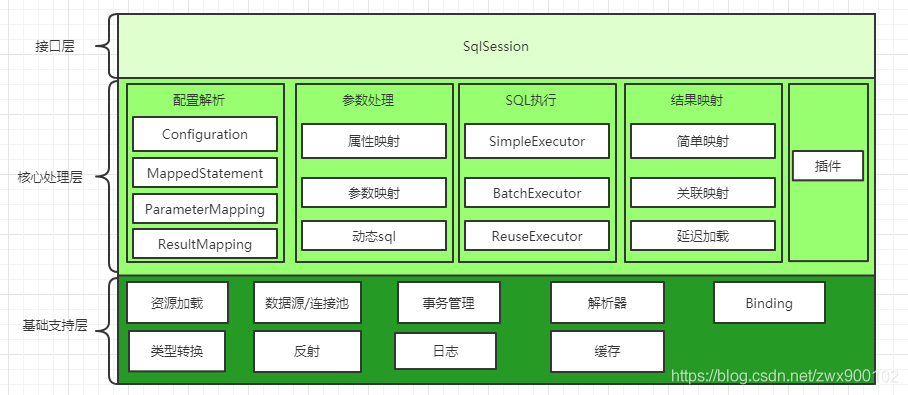
- 接口层
接口层的核心对象就是SqlSession,SqlSession是应用和MyBatis打交道的桥梁,SqlSession上定义了一系列数据库操作方法,然后在收到请求的时候再去调用核心处理层模块来完成具体操作。
- 核心处理层
真正和数据库相关操作都是在核心层完成的,核心层主要做了以下4件事:
1、将接口中传入的参数解析并且映射成为JDBC
2、解析xml文件中的SQL语句,包括参数的插入和动态SQL的生成
3、执行SQL语句
4、处理结果集,并且映射成Java对象
PS:插件也属于核心层,因为插件就是拦截核心处理层对象
- 基础支持层
基础支持层就是封装一些底层操作用来处理核心层的功能
我们今天要讲解的四大天王对象就是核心处理层的四大对象,接下来就让我们逐一进行分析
Executor
Executor就是真正用来执行Sql语句的对象,我们调用SqlSession中的方法,最终实际上都是通过Executor来完成的。我们先来看一下Executor的类图关系:

这里面其实用到了模板方法模式。顶层接口Executor定义了一系列规范,而在抽象类BaseExecutor中将一些固定不变的方法进行了封装,并定义了一下抽象方法待子类实现
BaseExecutor
BaseExecutor是一个抽象类,除了下面的四个方法是抽象方法,其余所有方法都是一些如获取缓存,事务提交,获取事务等公共操作,所以就直接被实现了。
如下图所示,红框之内的四个方法就是抽象方法:
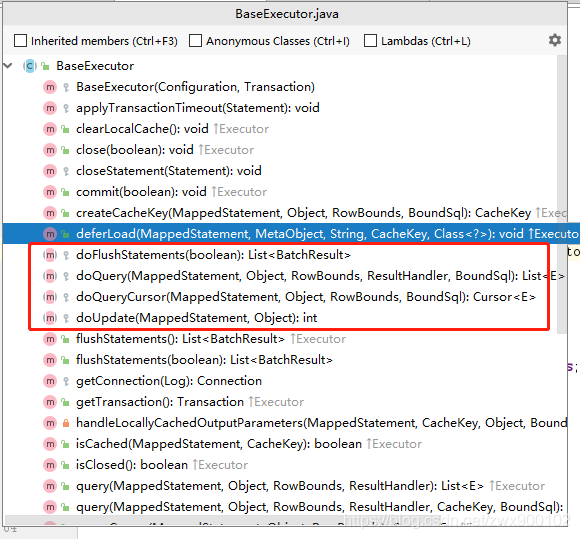
- doFlushStatements():刷新Statement对象
- doQuery():执行查询语句并返回List
- doQueryCursor():执行查询语句并返回Cursor对象
- doUpdate():执行更新操作
我们在讲述MyBatis核心配置的文章中提到,配置文件中的setting标签内有一个属性defaultExecutorType,有三种执行类型:SIMPLE,REUSE,BATCH。如果不配置则默认就是SIMPLE。这三种类型就是对应了BaseExecutor的三个子类:
SimpleExecutor,ReuseExecutor和BatchExecutor。
SimpleExecutor
SimpleExecutor是最简单的一个执行器,没有任何特殊的,就是实现了BaseExecutor中的四个抽象方法。
我们来看其中一个doQuery()方法,可以看到没有任何特殊逻辑,就是很常规的流程操作:

其中初始化Statement对象我们为了对比,也进去看一下:

我们再来看一个doFlushStatements()方法
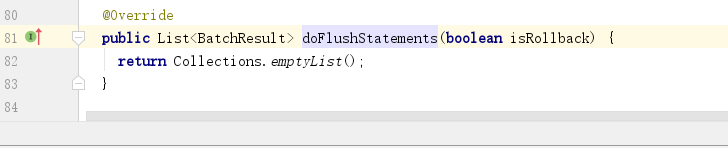
这里什么都没做,直接返回了一个空List
ReuseExecutor
ReuseExecutor相比较于SimpleExecutor做了一点优化,那就是将Statement对象进行了缓存处理,不会每次都创建Statement对象,这样做的话减少了SQL预编译和创建对象的开销。
ReuseExecutor中的查询和更新方法和SimpleExecutor完全一样,而其中的差别就在于创建Statement对象上,我们进去ReuseExecutor的prepareStatement方法:

我们可以看到区别就是多了一个从缓存(Map<sqlString, Statement>)中获取Statement对象的逻辑,用来达到复用Statement对象的目的。
其中getStatement是通过ReuseExecutor内的一个HashMap属性来获取Statement对象,其中key值就是我们执行的sql语句:

我们再来看看doFlushStatements方法,可以看到,这里面会遍历map将Statement关闭,并清空map,看到这里,大家应该就明白了为什么SimpleExecutor内这个方法直接返回的是空,因为SimpleExecutor方法没有Statement需要关闭。
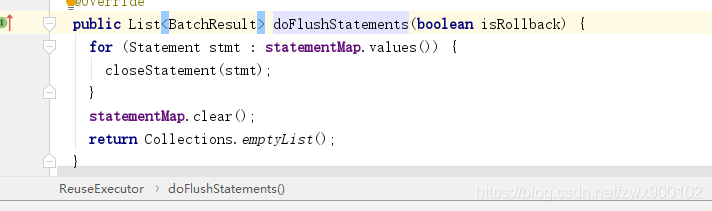
PS:doFlushStatements方法在BaseExecutor中的commit(),rollback(),close()方法中会被调用(即:事务提交,事务回滚,事务关闭三个方法)。
BatchExecutor
BatchExecutor从名字上也可以看出来,这是一个支持批量操作的执行器。
如果说大家都用过jdbc就知道,jdbc是支持批量操作的,有一个executeBatch()方法用来执行批量操作,但是有一个前提就是执行批量操作的sql除了参数不同,其他都应该是相同的(关于这一点,下面我们会举例来说明)。
需要注意的是,批量操作只支持insert,update,delete语句,select语句是不支持的,所以BatchExecutor内的doQuery方法和其他执行器并没有很大不同,区别就是在查询之前会先调用flushStatements(),我们不做过多讨论,主要看一下doUpdate方法:
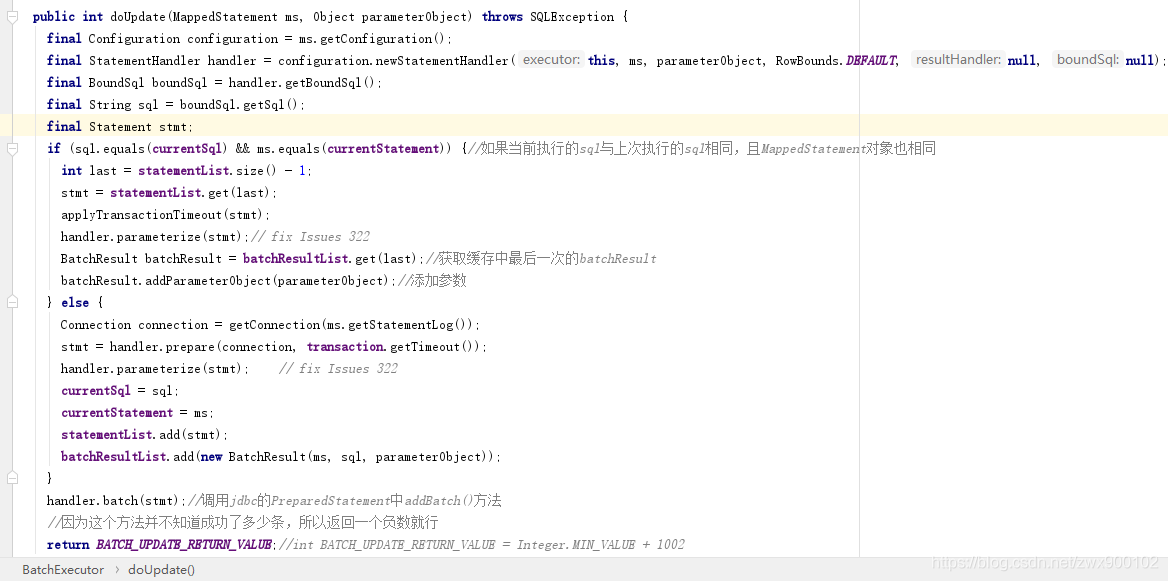
下面是一些成员属性:

这个方法的逻辑就是判断相同模式的sql会共用同一个Statement对象,然后缓存到list内,需要注意的是它只会和前一个进行比对,也就是说假如你有相同模式的2条sql,但是你中间先执行了一条其他sql,那么就会产生3个Statement对象,从而无法共用了。
PS:上面的doUpdate中返回了一个数:BATCH_UPDATE_RETURN_VALUE,这个数其实没有什么特别含义,只需要返回一个没有意义的负数就可以,表示代码不知道执行成功多少条。比如说直接返回-1,或者干脆直接返回Integer.MIN_VALUE都是没有问题的,全凭个人喜好了。
接下来我们再看看doFlushStatements()方法:
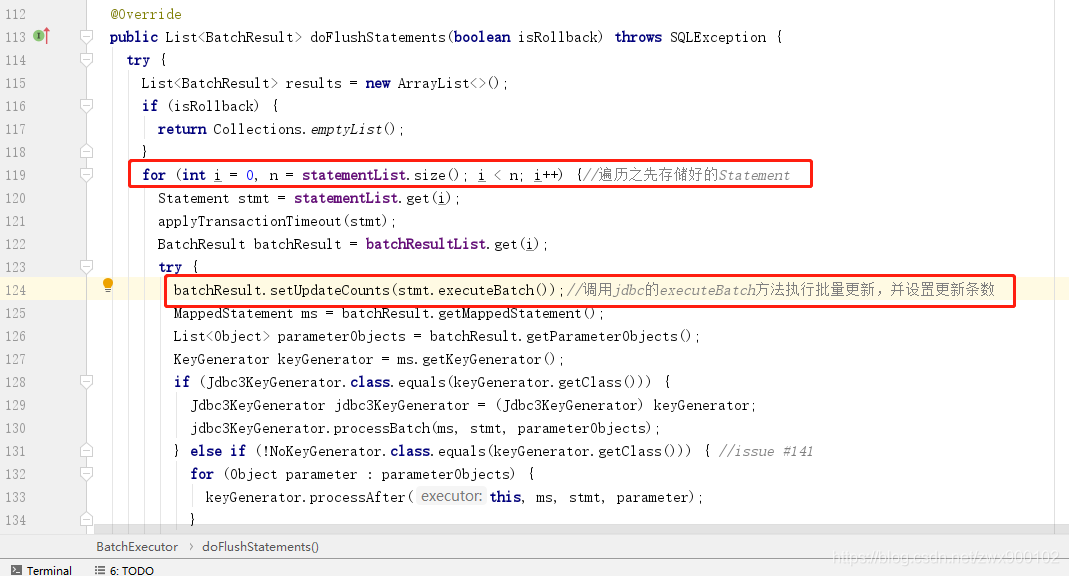
这个方法就是去遍历上面存储好的Statement,依次调用Statement中的executeBatch方法。
三种常用批量插入方式
讲到这里,我们就干脆扯开一点,聊一聊MyBatis编程中常用的三种批量操作方式。
直接代码循环
这是最简单的一种,但也是效率最低的一种,如下简单示例:
UserAddressMapper userAddressMapper = session.getMapper(UserAddressMapper.class); for (UserAddress userAddress : userAddressList){ userAddressMapper.insert(userAddress); }
这种方式会把大部分时间消耗在网络连接通信上,一般不建议使用。
利用MyBatis中批量标签foreach处理
新建测试类:
package org.tuniu.mybatis; import org.apache.ibatis.io.Resources; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import org.tuniu.mybatis.entity.UserAddress; import org.tuniu.mybatis.mapper.UserAddressMapper; import java.io.IOException; import java.io.InputStream; import java.util.ArrayList; import java.util.List; public class TestBatchInsert { public static void main(String[] args) throws IOException { String config = "mybatis-config.xml"; //读取mybatis-config配置文件 InputStream stream = Resources.getResourceAsStream(config); //创建SqlSessionFactory对象 SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(stream, "dev"); //创建SqlSession对象 SqlSession session = sqlSessionFactory.openSession(); try { List<UserAddress> userAddressList = new ArrayList<UserAddress>(); UserAddress userAddr = new UserAddress(); userAddr.setAddress("广东深圳"); userAddressList.add(userAddr); UserAddress userAddr2 = new UserAddress(); userAddr2.setAddress("广东广州"); userAddressList.add(userAddr2); UserAddressMapper userAddressMapper = session.getMapper(UserAddressMapper.class); userAddressMapper.batchInsert(userAddressList); session.commit(); }finally { session.close(); } } }
Mapper接口新增如下方法:
void batchInsert(List<UserAddress> userAddressList);
XML文件如下:
<insert id="batchInsert"> insert into lw_user_address (address) values <foreach collection="list" item="item" separator=","> (#{item.address}) </foreach> </insert>
执行之后输出如下语句:

顺便我们介绍一下foreach标签的用法:
- collection:
表示待循环的对象。当参数为List时,默认"list",参数为数组时,默认"array"。但是当我们在Mapper接口中使用@Param(“xxx”)时,默认的list,array将会失效,必须使用我们自己设置的参数名。 还有一种特殊情况就是假如集合里面有集合或者对象里面有集合,那么可以使用collection=“xxx.属性名”。
- item:
表示当前循环中的元素。
- open/close:
表示循环体开始和结束位置插入的符号,一般成对出现,in语句使用较多,如:
- separator:
表示每个循环之后的分割符号,可参考上面的例子
- index:
当前元素在集合的下标,如果是map则是map的key值,这个参数一般用的相对较少。
<select id="test"> select * from xxx where id in <foreach collection="list" item="item" open="(" close=")" separator=","> #{item.xxx} </foreach> </select>
BatchExecutor插入
我们把上面的普通例子中获取Session的例子改写一下:
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH);
然后执行之后输出sql如下:

可以看到,这两条语句就是相同模式的sql,只是参数不同,所以直接执行一次。
我们把上面的例子改写一下:
UserAddress userAddr = new UserAddress(); userAddr.setAddress("广东深圳"); userAddr.setId(1); userAddressList.add(userAddr); UserAddress userAddr2 = new UserAddress(); userAddr2.setAddress("广东广州"); userAddr2.setId(2); userAddressList.add(userAddr2); UserAddressMapper userAddressMapper = session.getMapper(UserAddressMapper.class); userAddressMapper.insert(userAddr);//sql-1 userAddressMapper.insert10(userAddr2);//sql-10 userAddressMapper.insert(userAddr);//sql-1
insert和insert10分别对应如下语句(一条是1个参数,一条是2个参数):
<insert id="insert" parameterType="UserAddress" useGeneratedKeys="true" keyProperty="address"> insert into lw_user_address (address) values (#{address}) </insert> <insert id="insert10" parameterType="UserAddress" useGeneratedKeys="true" keyProperty="address"> insert into lw_user_address (id,address) values (#{id},#{address}) </insert>
上面就是有两种sql模型,理论上应该执行2次,但是我们根据源码知道,因为insert语句中间被insert10隔开了,所以实际上sql-1也是不能复用的,也就是会执行3次:
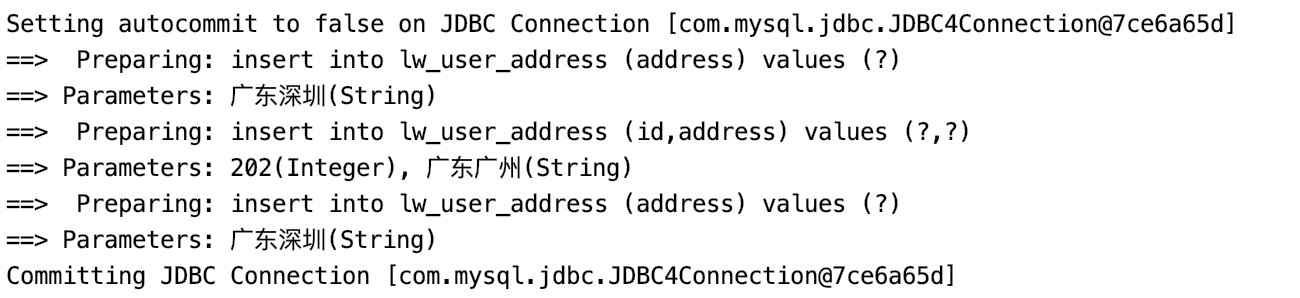
PS:这三种批量执行的效率有兴趣的可以自己去测试一下,效率最高的应该是foreach标签的形式
ClosedExecutor
ClosedExecutor是ResultLoaderMap(懒加载时会使用)内的一个内部类,没有任何具体实现,一般我们不会主动去使用。
CachingExecutor
这个执行器和缓存有关,在这里我们先不展开,下一篇讲述缓存实现原理的时候再来分析
StatementHandler
StatementHandler是数据库会话器,专门用来处理数据库会话的。StatementHandler内运用了适配器模式和策略模式的思想
类图结构和Executor非常相似,如下图所示:

这个接口中的方法也相对较少,prepare方法是用来初始化具体Statement对象的:

BaseStatementHandler
BaseStatementHandler是一个抽象类,实现了StatementHandler中的所有方法,只留下了一个初始化Statement对象方法留给子类实现。
SimpleStatementHandler
SimpleStatementHandler对应JDBC的Statement,是一种非预编译语句,所以参数中是没有占位符的,相当于参数中会用$符号
PreparedStatementHandler
PreparedStatementHandler对应JDBC的PrepareStatement语句,是一种预编译,参数会有占位符,预编译可以防止SQL注入
CallableStatementHandler
CallableStatementHandler依赖于JDBC的Callablement,用来调用存储过程语句
RoutingStatementHandler
RoutingStatementHandler这个从名字上可以看出来,只是起到了一个路由作用,会根据statement类型来生成相对应的Statement对象:

ParameterHandler
ParameterHandler是一个参数处理器,主要是用来对预编译语句进行参数设置额,只有一个默认实现类DefaultParameterHandler。ParameterHandler中只定义了两个方法,一个获取参数,一个设置参数:

ResultSetHandler
ResultHandler是一个结果处理器,StatementHandler完成了查询之后,最终就是通过ResultHandler来实现结果集映射,ResultSetHandler接口中只定义了3个方法用来处理结果,而这三个方法对应了三种返回结果:

ResultHandler也默认提供了一个实现类:DefaultResultSetHandler。一般我们平常用的最多的就是通过handleResultSets来实现结果集转换,这个方法的大致思路我们上一篇文章已经分析过了,在这里就不重复展开。
总结
经过这篇文章的分析,我想大家可以体会到SqlSession只是个甩手掌柜的意思,因为SqlSession只是一个对外接口,实际真正干活的却是Executor等四大对象:Executor,StatementHandler,ParameterHandler,ResultSetHandler。本文的重点讲述了Executor对象,并对比了三种常用批量操作的使用方法,相信通过这篇文章的学习大家对MyBatis的执行流程可以有更深一步的了解,掌握了这四大对象,后面就会更容易理解MyBatis的插件实现原理。
请持续关注我后续文章,MyBatis后续文章系列计划中至少还有三篇,分别会分析缓存实现原理,插件实现原理,和日志管理相关知识。
————————————————
版权声明:本文为CSDN博主「双子孤狼」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/zwx900102/article/details/108696031