一. python 中常用的正则表达式

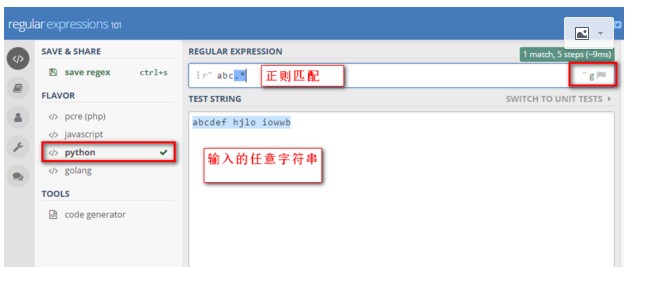
二. 正则表达式的网站,可以进行在线正则匹配
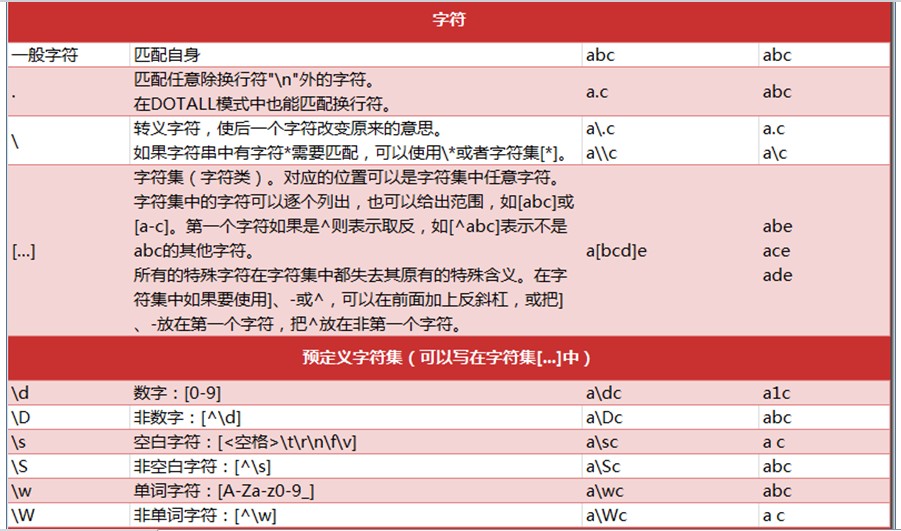
1. 使用方法及正则介绍
1》 ‘.’ 匹配任意除换行符外(
)的任意字符
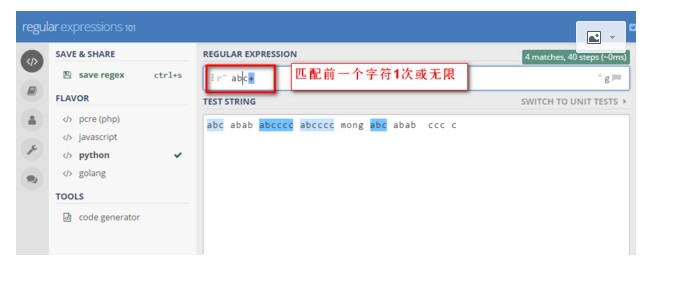
‘*’ 匹配前一个字符0次或任意多次
2》 匹配数字0-9

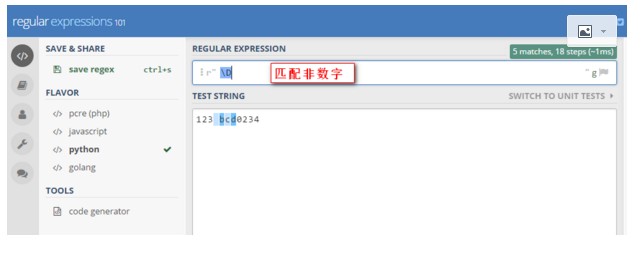
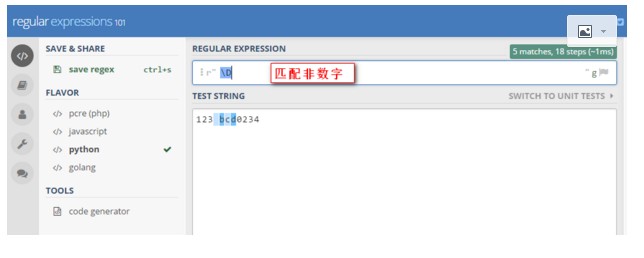
3》D 匹配非数字 [^]
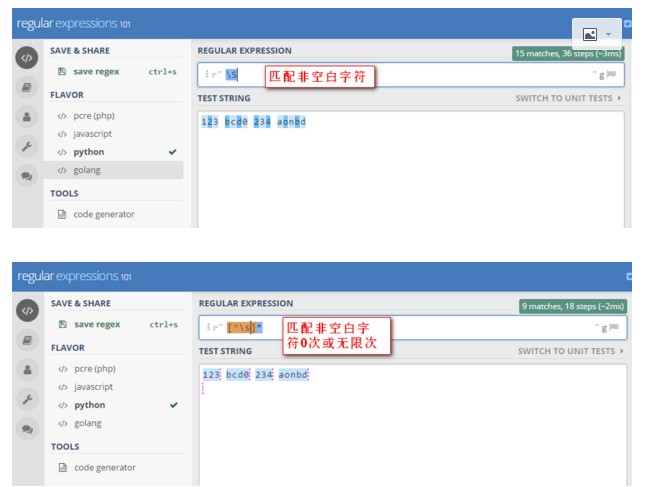
4》s 匹配空格字符

5》 S 匹配非空白字符 [^s]*
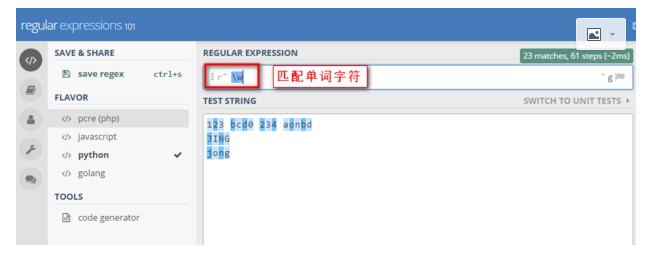
6> w 匹配单词字符 [a-z] [A-Z][0-9]
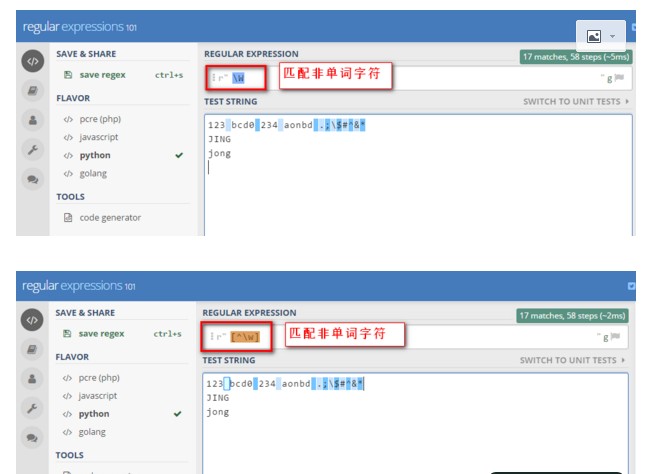
7> W 匹配非单词字符 [^w]
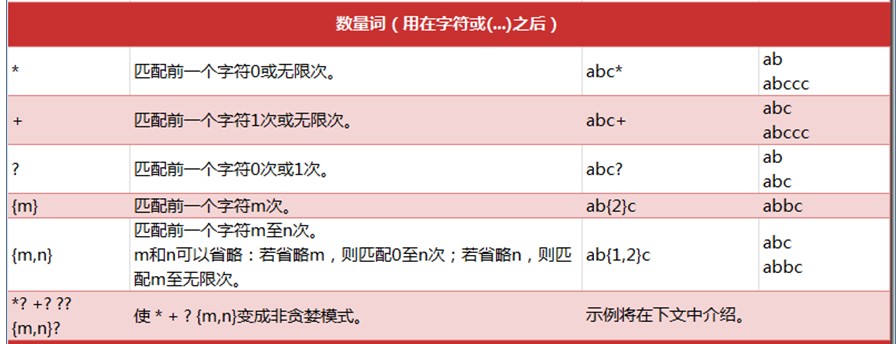
9 )* 匹配前一个字符0次或无限次
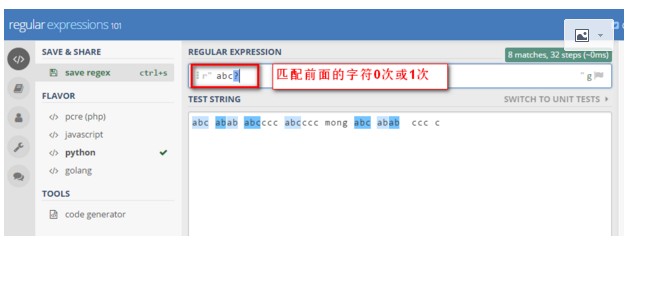
10》? 匹配前面的字符0次或1次
11》{m} 匹配前一个字符m次

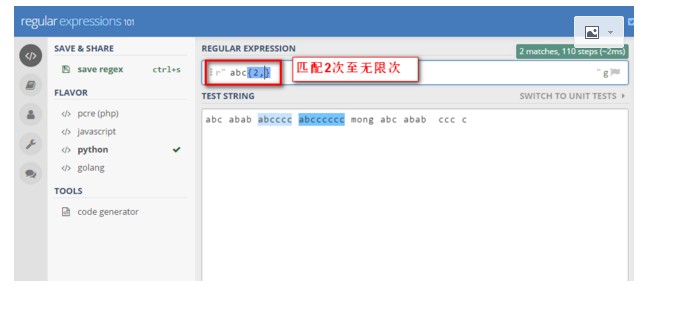
12》{m,n} 匹配前一个字符m次至n次
m和n都可以省略,若省m,则表示匹配前一个字符0次至n次
若省略n,则表示匹配m至无限次
省略m:{0,n}

省略n:{m,0}。匹配m次至无限次
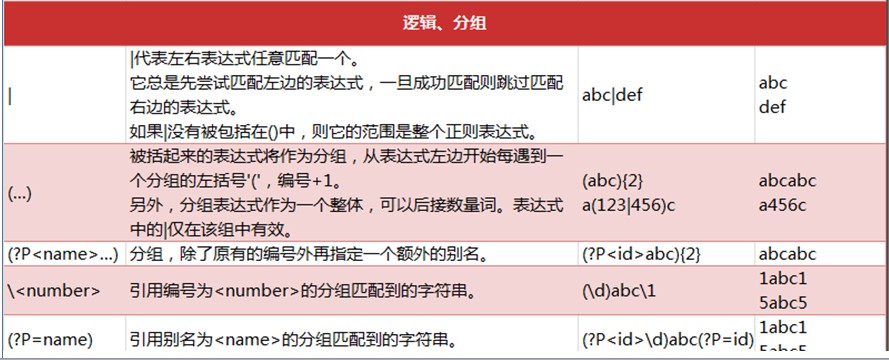
12》 ^ 以什么什么开头
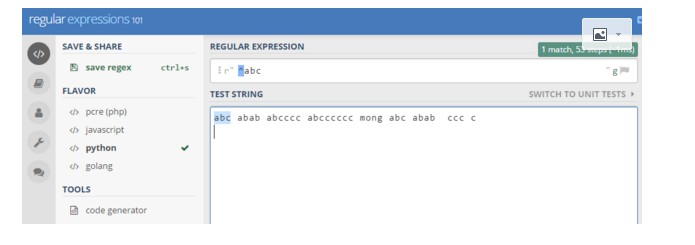
13》 $ 以什么什么结尾
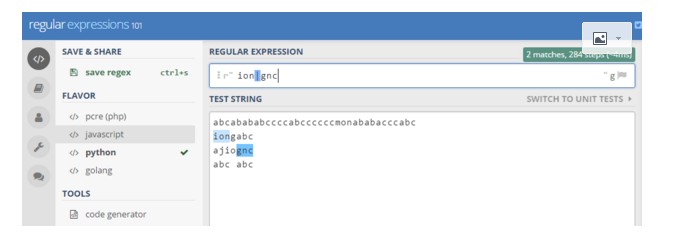
14》 | 代表左右表达式任意匹配一个。它总是嫌尝试匹配左边的表达式,一旦成功
成功匹配则跳过右边的表达式。如果| 没有被包括在()中,则它的范围是整个
正则表达式。
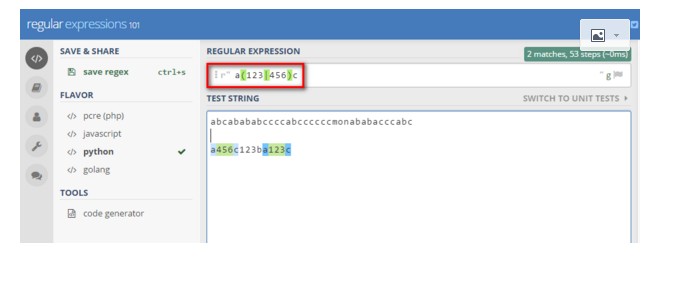
15》(.......) 被括起来的表达式将作为分组,从表达式左边开始每遇到一个分组的左
括号‘(’ ,编号+1。另外分组表达式作为一个整体,可以后接数量词。表
达式中的 | 仅在该组中有效。
16》正则表达式的分组
(?P<name>....) 分组,除了原有的编号外再指定一个额外的别名
<number> 引用编号为<number>的分组匹配到的字符串。
(?P=name) 引用别名为<name> 的分组匹配到的字符串。