概述
查找就是在由若干记录组成的集合中找出关键字值与给定值相同的记录。如查找成功,返回找到的记录的信息或者在表中的位置,查找失败就返回一个代表失败的标志。一个查找算法的优劣取决于查找过程中的比较次数,使用平均比较长度(平均比较次数)ASL来衡量查找算法的效率,ASL是和指定值进行比较的关键字的个数的期望值。
ASL=∑n1Pi*Ci
其中,Ci表示查找到第i个数据元素时已经比较的次数,Pi是查找表中第i个数据元素的概率。
静态查找和动态查找
根据查找算法是否改变查找表的内容,将查找算法分为静态查找和动态查找。静态查找对查找表查找时,查找成功就返回记录的信息或在查找表中的位置,查找失败就返回一个代表失败的标志,并不对查找表进行插入和删除,或经过一段时间之后再对查找表进行集中式的插入和删除操作。动态查找是查找与插入和删除在同一阶段进行,例如,在某些问题中,查找成功时,删除查找到的记录,查找失败时,插入被查找的记录。
查找结构
为了提高查找效率,为带查找序列选择合适的数据结构以存储这些数据,这种面向查找的数据结构就称为查找结构。主要有以下三种数据结构:
1)线性表:适用于静态查找,查找方法有顺序查找和二分查找。
2)树表:适应于动态查找,查找方法是采用二叉排序树进行查找(类似二分查找过程)。
3)哈希表:静态和动态查找均合适,查找方法是哈希技术。
无序查找和有序查找
无序查找要求查找表有序无序均可。有序查找要求查找表必须是有序的。
顺序查找
顺序查找算法是最简单的查找算法,从查找表的一端开始,顺序查找每个记录,直至另一端为止。实现代码如下:


1 //顺序查找,n是数组长度,a从[0,n-1] 2 public static int sequenceSearch(int[] a,int value,int n){ 3 int i=0; 4 while (i<n&&a[i]!=value){//比较大小和检查边界同时进行 5 ++i; 6 } 7 if(i<n){ 8 return i;//查找成功 9 } 10 else { 11 return -1;//查找失败 12 } 13 }
查找成功时的平均查找长度是:
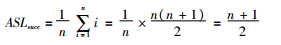
查找失败时平均查找长度是(无序表的查找,到最后一个元素才能确定查找失败):n。
哨兵
为简化边界条件而引入的附加节点(记录)均可称为哨兵,哨兵常用在循环和递归中,用于边界条件的检查。上述顺序查找算法不仅要比较查询表中元素是否与查找值相同,同时还要检测是否越界,因此可以添加哨兵,简化程序,添加哨兵后的代码如下:
1 //添加哨兵的顺序查找,n是数组最后一个元素的索引,[1,n]是查找表内容,a[0]是哨兵 2 public static int sequenceSearch2(int[] a,int value,int n){ 3 int i=n; 4 a[0]=value; 5 while (a[i]!=value){//通过哨兵避免了边界检查 6 --i; 7 } 8 if(i>0){ 9 return i;//查找成功 10 } 11 else { 12 return -1;//查找失败 13 } 14 }
查找成功时的平均查找长度是仍然是(n+1)/2。查找失败时的平均查找长度是n+1(最后需要与哨兵比较,多了一次比较)。
在查找表元素个数大于1000时,添加哨兵的查找时间几乎减少了一半。顺序查找算法对查找表的存储结构没有要求,顺序存储和链式存储均可应用,并且对表中记录的顺序也没有要求,不过,查找效率低下,时间复杂度是O(n)。
折半查找
折半查找要求查找表是有序的,并且是顺序存储,另外,一般应用于静态查找。实现代码如下:
1 //折半查找 2 public static int binarySearch(int[] a,int value,int n){ 3 /* 4 边界检查 5 */ 6 int low=0; 7 int high=n-1; 8 int mid=low+(high-low)/2;//防止溢出.(high+low)/2可能会溢出。 9 while (low<=high){ 10 if(a[mid]==value){ 11 return mid; 12 } 13 else if (a[mid]>value){ 14 high=mid-1; 15 } 16 else if(a[mid]<value){ 17 low=mid+1; 18 } 19 mid=low+(high-low)/2; 20 } 21 return -1;//查找失败 22 }
根据折半查找的过程,也就是mid的不断变化,可以生成二叉判定树,通过mid构造这棵判定树,这棵树的左子树节点的值都小于其根节点的值,右子树的值都大于根节点的值,其实,根据折半查找的过程生成的二叉判定树就是一棵二叉排序树。根据已排序的查找表生成二叉判定树的过程如下:

1)对于元素个数为n的查找表,生成的二叉判定树高度(高度从1开始计数)h=⌈log(n+1)⌉,与n个节点的完全二叉树的高度相同。推导过程如下:
对于高度为h的二叉判定树,第一层至第h-1层为满二叉树,所以有:
2d-1-1<=n<=2d-1,进而有2d-1<=n+1,n+1<=2d,最后d-1<=log2(n+1)<=d,而d-1和d都是整数,所以有d=⌈log(n+1)⌉。
2)根据二叉判定树得到查找成功时的ASL:

ASL=1/9*(1+2*2+3*4+4*2)=25/9。
3)查找到外部节点时表示查找失败,外部节点比判定树节点个数多1个,失败时的ASL=1/10*(3*6+4*4)=17/5。
折半查找的最坏性能与平均性能相当接近,其时间复杂度是O(log n)。
哈希查找
基于比较的查找算法,其下界是O(log n)~O(n),要突破这个下界就不能依赖比较来进行查找。哈希技术的思想是把记录在表中的位置和记录对应的关键字之间建立一种映射关系,通过记录的关键字就可以得到记录的位置,理想情况下,通过哈希函数根据记录的关键字计算直接得到记录的位置,此时查找的时间复杂度是是O(1)。哈希查找要解决的关键问题是:构造哈希函数和冲突的解决方法。
哈希函数
哈希函数的设计遵循两个原则:
1)计算简单。简单的哈希函数可以快速得到哈希地址,加快查找效率。
2)函数值均匀分布。通过哈希函数计算得到的哈希地址分布的越均匀产生冲突的可能性越小,查找效率越高。在不产生冲突的理想条件下,哈希表的查找、插入(查找失败就在空白处插入查找值)、删除(查找到元素可以选择删除)的时间复杂度都是O(1)。另外,哈希地址均匀分布也是提高了空间的利用率。为了达到理想情况,在不考虑空间的情况下,完全可以申请一块巨大的存储空间,这样就避免了冲突的发生。
除留余数法
哈希函数的构造方法有很多,主要使用的是除留余数法。本着抓大放小的原则,这里只介绍除留余数法。
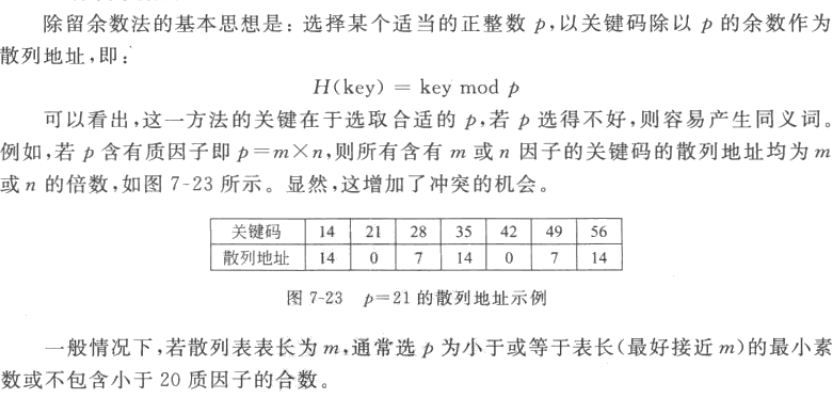
除留余数法最关键的是选择模值p,假设查找表的元素个数为n,选择大于n的最小质数作为模值p。某正整数的质因数肯定不大于其开方值,以这个开方值作为上界,2作为下界,得到p的代码实现如下:
1 //计算大于查找表元素个数的最小质数。 2 public static int calHashTableLength(int len){ 3 int maxPrimeFactor; 4 int i; 5 while (true){ 6 maxPrimeFactor=(int)Math.sqrt(++len);//某数的的一个质因数肯定不超过其平方 7 for (i=2; i <=maxPrimeFactor ; i++) { 8 if(len%i==0){ 9 break;//有一个质因数就表示不是质数,退出循环 10 } 11 } 12 if(i>maxPrimeFactor){//是质数 13 return len; 14 } 15 } 16 }
处理冲突的方法
一般情况下,很难有理想的哈希函数存在。两个不同的关键字可能会映射到同一个哈希地址,称之为冲突。发生冲突时,就需要另外找一个地址用来存放记录。下面介绍冲突的处理方法。
开放地址法
使用开放地址法处理得到的哈希表成为闭哈希表。所谓的开放地址法,就是在由关键字得到的哈希地址一旦发生冲突,就去寻找下一个空的哈希地址,只要哈希表还有空位置,就一定可以找到新地址。以下介绍开放地址法中常用的线性探测法。
线性探测法
当冲突发生时,线性探测法从冲突位置的下一个位置开始,依次寻找空哈希地址(没有存值的),直至绕了一圈到达冲突位置的前一个位置,此时表示哈希表已满,未找到一个空白位置。公式表示如下:
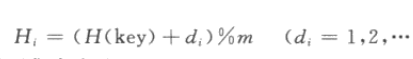
开放定址法的步骤如下:
1)根据关键字key计算哈希地址hashAddr,如果ht[hashAddr]等于key,那么查找成功,返回key的哈希地址hashAddr,否则转2
2)如果hashAddr对应的位置为空,表示查找失败,将ht[hashAddr]置为key,然后返回-1(表示查找失败),否则转3
3)走到这一步表示,newHashAddr对应的位置不为空并且ht[hashAddr]!=key,这表明发生了冲突,令newHashAddr=(hashAddr+1)%m,得到新的哈希地址,如果ht[newHashAddr]不为空(也就是已经填充了元素),比较其与key是否相等,相等就查找成功,返回newHashAddr,否则继续计算下一个哈希地址newHashAddr=(newHashAddr+1)%m,一直到newHashAddr+1=newHashAddr,也就是移动了一圈之后到达了原冲突地址的前一个位置(循环检测条件是ht[newHashAddr]!=-1&&newHashAddr!=hashAddr)。
4)如果循环停止有两种情况,其一,ht[newHashAddr]==-1,也就是找到一个空白处,将查找值填入,返回失败标识。其二,通过不断的访问下个位置,到了原冲突位置的前一个位置,表示赚了一圈都没有空白位置,说明表已经满了,抛出“表满”异常,然后返回查找失败标识。
具体实现代码如下:
1 //除留余数法构造哈希函数,其中hashTableLength是根据查找表大小求得的大于查找表个数的最小质数 2 //开放定址法之线性探测法,是一种处理冲突的方式。新地址计算:H=(H(key)+d)%m (d=1,2....m-1),哈希函数使用除留余数法. 3 //假设哈希表中存储的都是正整数,以-1表示哈希表中并没有存储内容 4 public static int hashSearch(int[] hashTable,int m,int key){//既包含查找又包含删除 5 int hashAddr=key%m; 6 if(hashTable[hashAddr]==key){//根据哈希地址查找到关键字 7 System.out.println("直接找到,位置是:"+hashAddr); 8 return hashAddr;//查找成功 9 } 10 if(hashTable[hashAddr]==-1){//对应的哈希地址位置为空 11 hashTable[hashAddr]=key; 12 return -1;//查找失败 13 } 14 System.out.println(String.format("%s发生冲突",key)); 15 int newHashAddr=(hashAddr+1)%m; 16 while (hashTable[newHashAddr]!=-1&&newHashAddr!=hashAddr){//向后探测的元素不为空且还未移动到第一次的探测位置 17 if(hashTable[newHashAddr]==key){ 18 System.out.println("探测成功,最终位置:"+newHashAddr); 19 return newHashAddr;//查找成功 20 } 21 System.out.println(String.format("向后探测位置:%s",newHashAddr)); 22 newHashAddr=(newHashAddr+1)%m;//继续向后探测 23 } 24 25 if(hashTable[newHashAddr]==-1){//探测到的位置为空,停止探测,查找失败,插入元素。 26 System.out.println("探测成功,最终位置:"+newHashAddr); 27 hashTable[newHashAddr]=key; 28 return -1;//查找失败 29 } 30 System.out.println("没有查找到元素,哈希表已满不能插入元素"); 31 return -1; 32 33 }
下面是线性探测法的一个应用实例。

从闭散列表中删除一个记录不是采取直接删除的方式,而是做一个删除的标志,表示曾经有记录占用,但是现在不再占用。当查找至这个位置时,应该继续沿着序列查找,而不是代表查找失败,直接插入。当插入时,为了保证关键字不重复,不能直接插入,应该沿着探测序列探测下去。
关键字经过哈希函数的映射得到相同的哈希地址,称两个关键字为同义词。线性探测法会导致不是同义词的关键字争抢哈希地址,也就是发生冲突,称之为堆积现象。堆积导致冲突的发生,增加了比较次数(比较是否与哈希表中值相等),降低了查找效率。
链地址法
用链地址法处理冲突构造的哈希表称为开哈希表。链地址法是为将具有相同哈希地址的记录存到一个链表中(同义词子表),哈希表中存放指向各个链表的头指针。如下所示:
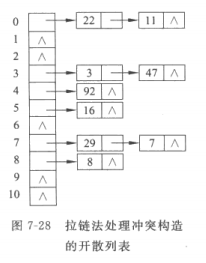
链地址法的实现代码如下:
1 //链地址法 2 public static Node hashSearch2(Node[] hashTable,int m,int key){ 3 int hashAddr=key%m; 4 System.out.println(String.format("关键字%s对应的哈希地址是:%s",key,hashAddr)); 5 Node subListNode=hashTable[hashAddr].next; 6 while (subListNode!=null&&!subListNode.ele.equals(key)){ 7 System.out.println("检测到冲突,查询同义词子表下个元素"); 8 subListNode=subListNode.next; 9 } 10 ////查找到同义词的末尾都未找到或者对应的哈希地址后没有同义词子表 11 // 查找失败,将待查元素插入表头(时间局部性) 12 if(subListNode==null){ 13 Node head=hashTable[hashAddr].next; 14 hashTable[hashAddr].next=new Node(key,head==null?null:head); 15 System.out.println("查找失败,插入查找元素"); 16 return null;//查找失败 17 } 18 //查找成功 19 System.out.println("查找成功"); 20 return subListNode; 21 }
下面是链地址法的一个应用实例以及伪代码:

总结
可以看到,对于同一个查找表,使用链地址法的平均查找长度较开放定址法的小,也就是查找效率更高。链地址法(开散列表)添加了单链表,增加了存储开销,不过也达到了以空间换时间的目的,并且不会产生堆积现象,查找、插入(头插法)、删除操作易于实现。而闭散列表没有多余的单链表,存储效率更高,不过由于堆积现象,使得查找效率较低,又由于将空位置作为查找失败的标识,所以闭散列表删除操作较复杂。

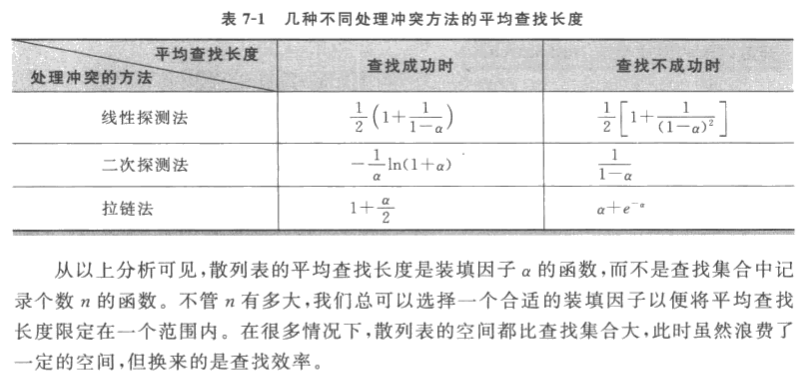
可以创建一个相对查找表个数合适的较大长度的哈希表,达到以空间换时间的目的。
参考:数据结构 C++版 第二版 王红梅。