1. HTTP和HTTPS
1.1 HTTP和HTTPS的关系
HTTP协议(HyperText Transfer Protocol,超文本传输协议):是一种发布和接收 HTML页面的方法。
HTTPS(Hypertext Transfer Protocol over Secure Socket Layer)简单讲是HTTP的安全版,在HTTP下加入SSL层。
SSL(Secure Sockets Layer 安全套接层)主要用于Web的安全传输协议,在传输层对网络连接进行加密,保障在Internet上数据传输的安全。
- HTTP的端口号为80,
- HTTPS的端口号为443
1.2 HTTP工作原理
网络爬虫抓取过程可以理解为模拟浏览器操作的过程。
浏览器的主要功能是向服务器发出请求,在浏览器窗口中展示您选择的网络资源,HTTP是一套计算机通过网络进行通信的规则。
2. HTTP的请求与响应
HTTP通信由两部分组成: 客户端请求消息 与 服务器响应消息
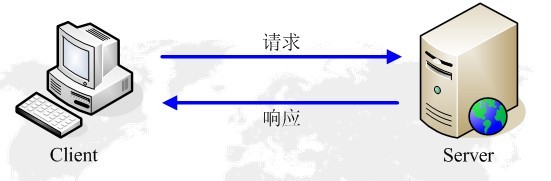
浏览器发送HTTP请求的过程(四步骤):
1) 当用户在浏览器的地址栏中输入一个URL并按回车键之后,浏览器会向HTTP服务器发送HTTP请求。HTTP请求主要分为“Get”和“Post”两种方法。
2) 当我们在浏览器输入URL http://www.baidu.com 的时候,浏览器发送一个Request请求去获取 http://www.baidu.com 的html文件,服务器把Response文件对象发送回给浏览器。
3) 浏览器分析Response中的 HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。 浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
4) 当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
URL(Uniform / Universal Resource Locator的缩写):统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种标识方法。
3. 客户端HTTP请求
3.1 HTTP请求头信息
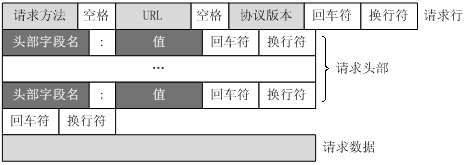
URL只是标识资源的位置,而HTTP是用来提交和获取资源。客户端发送一个HTTP请求到服务器的请求消息,包括以下格式:
请求行、请求头部、空行、请求数据
四个部分组成,下图给出了请求报文的一般格式。
4. 请求方法
GET https://www.baidu.com/ HTTP/1.1
根据HTTP标准,HTTP请求可以使用多种请求方法。
HTTP 0.9:只有基本的文本 GET 功能。
HTTP 1.0:完善的请求/响应模型,并将协议补充完整,定义了三种请求方法: GET, POST 和 HEAD方法。
HTTP 1.1:在 1.0 基础上进行更新,新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
HTTP 2.0(未普及):请求/响应首部的定义基本没有改变,只是所有首部键必须全部小写,而且请求行要独立为 :method、:scheme、:host、:path这些键值对。
HTTP1.1 和HTTP2.0对比案例速度测试:https://http2.akamai.com/demo
|
序号 |
方法 |
描述 |
|
1 |
GET |
请求指定的页面信息,并返回实体主体。 |
|
2 |
HEAD |
类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 |
|
3 |
POST |
向指定资源提交数据进行处理请求(例如提交表单或者上传文件),数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
|
4 |
PUT |
从客户端向服务器传送的数据取代指定的文档的内容。 |
|
5 |
DELETE |
请求服务器删除指定的页面。 |
|
6 |
CONNECT |
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
|
7 |
OPTIONS |
允许客户端查看服务器的性能。 |
|
8 |
TRACE |
回显服务器收到的请求,主要用于测试或诊断。 |
HTTP请求主要分为Get和Post两种方法
GET是从服务器上获取数据,POST是向服务器传送数据
GET请求参数显示,都显示在浏览器网址上,HTTP服务器根据该请求所包含URL中的参数来产生响应内容,即“Get”请求的参数是URL的一部分。 例如: https://www.baidu.com/s?wd=love
POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送,通常用来向HTTP服务器提交量比较大的数据(比如请求中包含许多参数或者文件上传、用户成立、用户注册操作等),请求的参数包含在“Content-Type”消息头里,指明该消息体的媒体类型和编码,
注意:避免使用Get方式提交表单,因为有可能会导致安全问题。 比如说在登陆表单中用Get方式,用户输入的用户名和密码将在地址栏中暴露无遗。
4.11 Cookie (Cookie)--重要
Cookie:浏览器用这个属性向服务器发送Cookie。Cookie是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息,也可以用来实现会话功能,以后会详细讲。
6.1 常见状态码
常用200(OK 请求成功)。
300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用302(所请求的页面已经临时转移至新的url)、307和304(使用缓存资源)。
400~499:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服务器拒绝访问,权限不够,反爬虫不返回数据的时候一般也这样)。
500~599:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)。
7. Cookie和Session
服务器和客户端的交互仅限于请求/响应过程,结束之后便断开,在下一次请求时,服务器会认为新的客户端。
为了维护他们之间的链接,让服务器知道这是前一个用户发送的请求,必须在一个地方保存客户端的信息。
Cookie:通过在 客户端(一般是浏览器) 记录的信息确定用户的身份。
Session:通过在 服务器端 记录的信息确定用户的身份。
8. Token
基于 Token 的身份验证是什么呢?很多大型网站也都在用,比如 Facebook,Twitter,Google+,Github 等等,比起传统的身份验证方法,Token 扩展性更强,也更安全点,非常适合用在 Web 应用或者移动应用上。Token 的中文有人翻译成 “令牌”,意思就是,你拿着这个令牌,才能过一些关卡。
使用基于 Token 的身份验证方法,在服务端不需要存储用户的登录记录。大概的流程是这样的:
- 客户端使用用户名跟密码请求登录
- 服务端收到请求,去验证用户名与密码
- 验证成功后,服务端会签发一个 Token,再把这个 Token 发送给客户端
- 客户端收到 Token 以后可以把它存储起来,比如放在 Cookie 里或者 Local Storage 里
- 客户端每次向服务端请求资源的时候需要带着服务端签发的 Token
- 服务端收到请求,然后去验证客户端请求里面带着的 Token,如果验证成功,就向客户端返回请求的数据.
三、HTTP/HTTPS抓包工具--Fiddler
Fiddler[ˈfɪdlə(r)]
1. HTTP代理神器Fiddler
Fiddler是一款强大Web调试工具,它能记录所有客户端和服务器的HTTP请求。 Fiddler启动的时候,默认IE的代理设为了127.0.0.1:8888,而其他浏览器是需要手动设置。
2. 工作原理
Fiddler 是以代理web服务器的形式工作的,它使用代理地址:127.0.0.1,端口:8888
5.2 响应 (Response) 部分详解
- Transformer —— 显示响应的编码信息。
- Headers —— 用分级视图显示响应的 header。
- TextView —— 使用文本显示相应的 body。
- ImageVies —— 如果请求是图片资源,显示响应的图片。
- HexView —— 用十六进制数据显示响应。
- WebView —— 响应在 Web 浏览器中的预览效果。
- Auth —— 显示响应 header 中的 Proxy-Authorization(代理身份验证) 和 Authorization(授权) 信息。
- Caching —— 显示此请求的缓存信息。
- Privacy —— 显示此请求的私密 (P3P) 信息。
- Raw —— 将整个响应显示为纯文本。
- JSON - 显示JSON格式文件。
- XML —— 如果响应的 body 是 XML 格式,就是用分级的 XML 树来显示它 。
爬虫基本库之urllib、urllib2、requests
1. urlopen--打开连接
2. Request-封装请求头信息
如果需要执行更复杂的操作,比如增加HTTP报头,必须创建一个 Request 实例来作为urlopen()的参数;而需要访问的url地址则作为 Request 实例的参数。
二、urllib.request:GET请求和POST请求
1. urllib.request默认只支持HTTP/HTTPS的GET和POST方法
2.1 urllib 和 urllib2区别
在python2中urllib 和 urllib2 都是接受URL请求的相关模块,但是提供了不同的功能。
两个最显著的不同如下:
在python2时代:
1)urllib 仅可以接受URL,不能创建 设置headers 的Request 类实例;
2)但是 urllib 提供 urlencode 方法用来GET查询字符串的产生,而 urllib2 则没有。(这是 urllib 和 urllib2 经常一起使用的主要原因)
3)编码工作使用urllib的urlencode()函数,帮我们将key:value这样的键值对转换成"key=value"这样的字符串,解码工作可以使用urllib的unquote()函数。(注意,不是urllib2.urlencode() )
问题:为什么有时候POST也能在URL内看到数据?
1)GET方式是直接以链接形式访问,链接中包含了所有的参数,服务器端用Request.QueryString获取变量的值。如果包含了密码的话是一种不安全的选择,不过你可以直观地看到自己提交了什么内容。
2)POST则不会在网址上显示所有的参数,服务器端用Request.Form获取提交的数据,在Form提交的时候。但是HTML代码里如果不指定 method 属性,则默认为GET请求,Form中提交的数据将会附加在url之后,以?分开与url分开。
3)表单数据可以作为 URL 字段(method="get")或者 HTTP POST (method="post")的方式来发送。比如在下面的HTML代码中,表单数据将因为 (method="get") 而附加到 URL 上:
5. 处理HTTPS请求 SSL证书验证
5.1 https和SSL之间是什么关系
https和SSL之间是什么关系:https就是在http上面加了一层ssl协议,在http站点上部署SSL数字证书就变成了https。
现在随处可见 https 开头的网站,urllib2可以为 HTTPS 请求验证SSL证书,就像web浏览器一样,如果网站的SSL证书是经过CA认证的,则能够正常访问
5.3 关于CA认证(数字证书认证中心)
CA(Certificate Authority)是数字证书认证中心的简称,是指发放、管理、废除数字证书的受信任的第三方机构,如
CA的作用是检查证书持有者身份的合法性,并签发证书,以防证书被伪造或篡改,以及对证书和密钥进行管理。
一般正常的网站都会主动出示自己的数字证书,来确保客户端和网站服务器之间的通信数据是加密安全的。
ProxyHandler处理器(代理设置)
使用代理IP,这是爬虫/反爬虫的第二大招,通常也是最好用的。 第一招,更换User-Agent
很多网站会检测某一段时间某个IP的访问次数(通过流量统计,系统日志等),如果访问次数多的不像正常人,它会禁止这个IP的访问。
所以我们可以设置一些代理服务器,每隔一段时间换一个代理,就算IP被禁止,依然可以换个IP继续爬取。
2.1开放代理 2.2 随机选择ip 2.3 私密代理
列举您使用过的 Python 网络爬虫所用到的网络数据包?
requests、urllib、urllib2
4) 列举您使用过的 Python 网络爬虫所用到的解析数据包?
BeautifulSoup、Xpath、lxml
5) 爬取数据后使用哪个数据库存储数据的,为什么?
有规则的数据可以存入 MySQL 中,但是要注意抓取内容出现缺失的情况
不规则的数据存储在 MongoDB 中,直接将数据存入再进行数据清洗
你用过的爬虫框架或者模块有哪些?谈谈他们的区别或者优缺点?
Python 自带:urllib,urllib2
第三方:requests
框架:Scrapy
正则Re模块直接使用的一些常用方法主要有:
- match 方法:从起始位置开始查找,一次匹配
- search 方法:从起始位置开始查找,一次匹配
- findall 方法:全部匹配,返回列表
- finditer 方法:全部匹配,返回迭代器
- split 方法:分割字符串,返回列表
- sub 方法:替换
12. 注意:贪婪模式与非贪婪模式
- 贪婪模式:在整个表达式匹配成功的前提下,尽可能多的匹配 ( * );
- 非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配 ( ? );
- Python里数量词默认是贪婪的。
三、XPath与lxml类库
如果不用正则处理HTML文档很累,还有没有其他的方法?
有!那就是XPath,我们可以先将 HTML文件 转换成 XML文档,然后用 XPath 查找 HTML 节点或元素。可以可以取到里面的内容了。
1. 什么是XML
XML 指可扩展标记语言(EXtensible Markup Language)
XML 是一种标记语言,很类似 HTML
XML 的设计宗旨是传输数据,而非显示数据
XML 的标签需要我们自行定义。
XML 被设计为具有自我描述性。
XML 是 W3C 的推荐标准
2. 什么是XPath(很重要)
XPath (XML Path Language) 是一门在 XML和HTML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
一、BeautifulSoup4 --解析和提取 HTML/XML 数据
1. BeautifulSoup4简介和安装使用
1.1 BeautifulSoup4简介
BeautifulSoup4和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,
支持CSS选择器(http://www.w3school.com.cn/cssref/css_selectors.asp)、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
|
抓取工具 |
速度 |
使用难度 |
安装难度 |
|
正则 |
最快 |
困难 |
无(内置) |
|
BeautifulSoup |
慢 |
最简单 |
简单 |
|
lxml |
快 |
简单 |
一般 |
1. Queue(队列对象)
Queue是python中的标准库,python2可以直接import Queue引用,python3可以import queue;
队列是线程间最常用的交换数据的形式,python下多线程的思考,对于资源,加锁是个重要的环节。因为python原生的list,dict等,都是not thread safe的。而Queue,是线程安全的,因此在满足使用条件下,建议使用队列。
初始化: class Queue.Queue(maxsize) FIFO 先进先出
包中的常用方法:
Queue.qsize() 返回队列的大小
Queue.empty() 如果队列为空,返回True,反之False
Queue.full() 如果队列满了,返回True,反之False
Queue.full 与 maxsize 大小对应
Queue.get([block[, timeout]])获取队列,timeout等待时间
创建一个“队列”对象
- import queue
- myqueue = queue.Queue(maxsize = 10)
- 将一个值放入队列中
- myqueue.put(10)
二、 Selenium与PhantomJS
[səˈli:niəm]
PhantomJS:无界面的浏览器
Selenium: 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
1. Selenium
[səˈli:niəm]
1.1 Selenium简介
文档地址:http://selenium-python.readthedocs.io/index.html
Selenium(http://www.seleniumhq.org/)是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。
支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。
Selenium这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。
测试系统功能——创建回归测试检验软件功能和用户需求。
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
. PhantomJS (芬特木)
英[ˈfæntəm]
2.1 PhantomJs简介
PhantomJS(http://phantomjs.org/) 是一个基于Webkit的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的 JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器要高效。
如果我们把 Selenium 和 PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,这个爬虫可以处理 JavaScrip、Cookie、headers,以及任何我们真实用户需要做的事情。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。
2.4.8 Headless Chrome 无界面浏览器
在 PhantomJS 年久失修, 后继无人的节骨眼
Google 发布了 chrome 59 / 60 正式版
注意:headless模式需要Chrome 59支持
这意味着在无 GUI 环境下, PhantomJS 不再是唯一选择
新的Chrome63版已经开始在windows上支持headless mode
PhantomJS 的核心开发者之一 Vitaly Slobodin 近日宣布,已辞任 maintainer ,不再维护项目。
Vitaly 发文表示,Chrome 59 将支持 headless 模式,用户最终会转向去使用它。Chrome 比PhantomJS 更快,更稳定,也不会像 PhantomJS 这样疯狂吃内存:
“我看不到 PhantomJS 的未来,作为一个单独的开发者去开发 PhantomJS 2 和 2.5 ,简直就像是一个血腥的地狱。即便是最近发布的 2.5 Beta 版本拥有全新、亮眼的 QtWebKit ,但我依然无法做到真正的支持 3 个平台。我们没有得到其他力量的支持!”
3. 快速入门
Selenium 库里有个叫 WebDriver 的 API。WebDriver 有点儿像可以加载网站的浏览器,但是它也可以像 BeautifulSoup 或者其他 Selector 对象一样用来查找页面元素,与页面上的元素进行交互 (发送文本、点击等),以及执行其他动作来运行网络爬虫。
一、机器视觉与Tesseract介绍
['tesəˌrækt]
1. 机器视觉
从 Google 的无人驾驶汽车到可以识别假钞的自动售卖机,机器视觉一直都是一个应用广 泛且具有深远的影响和雄伟的愿景的领域。
我们将重点介绍机器视觉的一个分支:文字识别,介绍如何用一些 Python库来识别和使用在线图片中的文字。
我们可以很轻松的阅读图片里的文字,但是机器阅读这些图片就会非常困难,利用这种人类用户可以正常读取但是大多数机器人都没法读取的图片,验证码 (CAPTCHA)就出现了。验证码读取的难易程度也大不相同,有些验证码比其他的更加难读。
将图像翻译成文字一般被称为光学文字识别(Optical Character Recognition, OCR)。可以实现OCR的底层库并不多,目前很多库都是使用共同的几个底层 OCR 库,或者是在上面 进行定制。
2. ORC库概述
['tesəˌrækt]
在读取和处理图像、图像相关的机器学习以及创建图像等任务中,Python 一直都是非常出色的语言。虽然有很多库可以进行图像处理,但在这里我们只重点介绍:Tesseract
Tesseract
Tesseract 是一个 OCR 库,目前由 Google 赞助(Google 也是一家以 OCR 和机器学习技术闻名于世的公司)。Tesseract 是目前公认最优秀、最精确的开源 OCR 系统。 除了极高的精确度,Tesseract 也具有很高的灵活性。它可以通过训练识别出任何字体,也可以识别出任何 Unicode 字符。
scrapy 框架--Spider、CrawlSpider
1. scrapy简介
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
Scrapy架构图
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
1.1 启动scrapy Shell
2 response
Scrapy Shell根据下载的页面会自动创建一些方便使用的对象,例如 Response 对象,以及 Selector 对象 (对HTML及XML内容)。
当shell载入后,将得到一个包含response数据的本地 response 变量,输入 response.body将输出response的包体,输出 response.headers 可以看到response的包头。
Selectors选择器
scrapy Selectors 内置 XPath 和 CSS Selector 表达式机制
Selector有四个基本的方法,最常用的还是xpath:
xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表
extract(): 序列化该节点为Unicode字符串并返回list
css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表,语法同 BeautifulSoup4
re(): 根据传入的正则表达式对数据进行提取,返回Unicode字符串list列表
六、Spider
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
class scrapy.Spider是最基本的类,所有编写的爬虫必须继承这个类。
主要用到的函数及调用顺序为:
1) __init__() : 初始化爬虫名字和start_urls列表
2) start_requests() 调用make_requests_from url():生成Requests对象交给Scrapy下载并返回response
3) parse() : 解析response,并返回Item或Requests(需指定回调函数)。Item传给Item pipline持久化 , 而Requests交由Scrapy下载,并由指定的回调函数处理(默认parse()),一直进行循环,直到处理完所有的数据为止。
八、CrawlSpider(规则爬虫)
1.3.2 CrawlSpider简要说明
CrawlSpider是爬取那些具有一定规则网站的常用的爬虫,它基于Spider并有一些独特属性
1)rules: 是Rule对象的集合,用于匹配目标网站并排除干扰
2)parse_start_url: 用于爬取起始响应,必须要返回Item,Request中的一个。
因为rules是Rule对象的集合,所以这里也要介绍一下Rule。它有几个参数:link_extractor、callback=None、cb_kwargs=None、follow=None、process_links=None、process_request=None
其中的link_extractor既可以自己定义,也可以使用已有LinkExtractor类,主要参数为:
3)allow:满足括号中“正则表达式”的值会被提取,如果为空,则全部匹配。
4)deny:与这个正则表达式(或正则表达式列表)不匹配的URL一定不提取。
5)allow_domains:会被提取的链接的domains。
6)deny_domains:一定不会被提取链接的domains。
7)restrict_xpaths:使用xpath表达式,和allow共同作用过滤链接。还有一个类似的restrict_css
Scrapy 框架实战--Request/Response、Mongodb、Middlewares
1. Request
1.2 常用的参数
1.2.1 url
url: 就是需要请求,并进行下一步处理的url
1.2.2 callback
callback: 指定该请求返回的Response,由那个函数来处理。
1.2.3 method
method: 请求一般不需要指定,默认GET方法,可设置为"GET", "POST", "PUT"等,且保证字符串大写
1.2.4 headers
headers: 请求时,包含的头文件。一般不需要。内容一般如下:
# 自己写过爬虫的肯定知道
Host: media.readthedocs.org
User-Agent: Mozilla/5.0 (Windows NT 6.2; WOW64; rv:33.0) Gecko/20100101 Firefox/33.0
Accept(艾克三普特): text/css,*/*;q=0.1
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Referer: http://scrapy-chs.readthedocs.org/zh_CN/0.24/
Cookie: _ga=GA1.2.1612165614.1415584110;
Connection: keep-alive
If-Modified-Since: Mon, 25 Aug 2014 21:59:35 GMT
Cache-Control: max-age=0
1.2.5 meta
meta: 比较常用,在不同的请求之间传递数据使用的。字典dict型
request_with_cookies = Request(
url="http://www.example.com",
cookies={'currency': 'USD', 'country': 'UY'},
meta={'dont_merge_cookies': True}
)
1.2.6 encoding
encoding: 使用默认的 'utf-8' 就行。
1.2.7 dont_filter
dont_filter: 表明该请求不由调度器过滤。这是当你想使用多次执行相同的请求,忽略重复的过滤器。默认为False。
1.2.8 errback
errback: 指定错误处理函数
三种scrapy模拟登陆策略
1. 发送POST请求--scrapy.FormRequest
只要是需要提供post数据的,就可以用这种方法。下面示例里post的数据是账户密码:
可以使用 yield scrapy.FormRequest(url, formdata, callback)方法发送POST请求。
如果希望程序执行一开始就发送POST请求,可以重写Spider类的start_requests(self) 方法,并且不再调用start_urls里的url。
2. 模拟登陆--FormRequest.from_response()和scrapy.Request
通常网站通过 实现对某些表单字段(如数据或是登录界面中的认证令牌等)的预填充。
使用Scrapy抓取网页时,如果想要预填充或重写像用户名、用户密码这些表单字段, 可以使用 FormRequest.from_response() 方法实现。
3. 使用cookie--登录人人网scrapy.FormRequest
登录那页就找那页的cookie
如果实在没办法了,可以用这种方法模拟登录,虽然麻烦一点,但是成功率100%
1. Mongodb简介
1.1 NoSQL简介
NoSQL(Not Only SQL ),意即“不仅仅是SQL” ,指的是非关系型的数据库 。是一项全新的数据库革命性运动,早期就有人提出,发展至2009年趋势越发高涨。NoSQL的拥护者们提倡运用非关系型的数据存储,相对于铺天盖地的关系型数据库运用,这一概念无疑是一种全新的思维的注入。
关系型数据库中的表都是存储一些结构化的数据,每条记录的字段的组成都一样,即使不是每条记录都需要所有的字段,但数据库会为每条数据分配所有的字段。而非关系型数据库以键值对(key-value)存储,它的结构不固定,每一条记录可以有不一样的键,每条记录可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。
1.2 常见的NoSql(非关系型数据库)数据库
CouchDB
Redis
MongoDB
Neo4j
HBase
BigTable
1.3 NoSql数据库优缺点
在优势方面主要体现在下面几点:- 简单的扩展
快速的读写
低廉的成本
灵活的数据模型
在不足方面主要有下面几点:
不提供对SQL的支持
支持的特性不够丰富
现有的产品不够成熟
1.4 MongoDB简介
MongoDB是用C++语言编写的非关系型数据库。特点是高性能、易部署、易使用,存储数据十分方便,主要特性有:
面向集合存储,易于存储对象类型的数据
模式自由
支持动态查询
支持完全索引,包含内部对象
支持复制和故障恢复
使用高效的二进制数据存储,包括大型对象
文件存储格式为BSON(一种JSON的扩展)
1.6 MongoDB基本概念
- 文档(document)是MongoDB中数据的基本单元,非常类似于关系型数据库系统中的行(但是比行要复杂的多)。
- 集合(collection)就是一组文档,如果说MongoDB中的文档类似于关系型数据库中的行,那么集合就如同表。
- MongoDB的单个计算机可以容纳多个独立的数据库,每一个数据库都有自己的集合和权限。
- MongoDB自带简洁但功能强大的JavaScript shell,这个工具对于管理MongoDB实例和操作数据作用非常大。
- 每一个文档都有一个特殊的键”_id”,它在文档所处的集合中是唯一的,相当于关系数据库中的表的主键。
四、使用 pymongo让MongoDB与python交互
七、Downloader Middlewares
1.1 通常防止爬虫被反主要有以下几个策略:
1)动态设置User-Agent(随机切换User-Agent,模拟不同用户的浏览器信息)。
2)禁用Cookies(也就是不启用cookies middleware,不向Server发送cookies,有些网站通过cookie的使用发现爬虫行为)。
3)可以通过COOKIES_ENABLED 控制 CookiesMiddleware 开启或关闭。
4)设置延迟下载(防止访问过于频繁,设置为 2秒 或更高)。
5)Google Cache 和 Baidu Cache:如果可能的话,使用谷歌/百度等搜索引擎服务器页面缓存获取页面数据。
6)使用IP地址池:VPN和代理IP,现在大部分网站都是根据IP来ban(禁止)的。
7)使用 Crawlera(https://scrapinghub.com/crawlera)(专用于爬虫的代理组件),正确配置和设置下载中间件后,项目所有的request都是通过crawlera发出。
scrapy-redis分布式组件
一、scrapy-redis
1.2 对scrapy经典框架爬虫原理的理解
1)spider打开某网页,获取到一个或者多个request,经由scrapy engine传送给调度器scheduler
request特别多并且速度特别快会在scheduler形成请求队列queue,由scheduler安排执行。
2)schelduler会按照一定的次序取出请求,经由引擎, 下载器中间键,发送给下载器dowmloader
这里的下载器中间键是设定在请求执行前,因此可以设定代理,请求头,cookie等。
3)下载下来的网页数据再次经过下载器中间键,经过引擎,经过爬虫中间键传送给爬虫spiders
这里的下载器中间键是设定在请求执行后,因此可以修改请求的结果,这里的爬虫中间键是设定在数据或者请求到达爬虫之前,与下载器中间键有类似的功能。
4)由爬虫spider对下载下来的数据进行解析,按照item设定的数据结构经由爬虫中间键,引擎发送给项目管道itempipeline这里的项目管道itempipeline可以对数据进行进一步的清洗,存储等操作,这里爬虫极有可能从数据中解析到进一步的请求request,它会把请求经由引擎重新发送给调度器shelduler,调度器循环执行上述操作。
5)项目管道itempipeline管理着最后的输出。
1.3 scrapy和scrapy-redis的区别和联系
scrapy 是一个通用的爬虫框架,但是不支持分布式,scrapy-redis是为了更方便地实现scrapy分布式爬取,而提供了一些以redis为基础的组件(仅有组件),你可以这么认为,scrapy是一工厂,能够出产你要的spider。而scrapy-redis是其他厂商为了帮助scrapy工厂更好的实现某些功能而制造了一些设备,用于替换scrapy工厂的原设备。
所以要想跑分布式,先让scrapy工厂搭建起来,再用scrapy-redis设备去更换scrapy的某些设备。
scrapy 是爬虫框架,scrapy-redis 是用redis替换了原本scrapy的爬虫调度部分。
1.4 分布式
分布式:一个业务分拆多个子业务,部署在不同的服务器上。
集群:同一个业务,部署在多个服务器上。
例如:小饭店原来只有一个厨师,切菜洗菜备料炒菜全干。后来客人多了,厨房一个厨师忙不过来,又请了个厨师,两个厨师都能炒一样的菜,这两个厨师的关系是集群。为了让厨师专心炒菜,把菜做到极致,又请了个配菜师负责切菜,备菜,备料,厨师和配菜师的关系是分布式,一个配菜师也忙不过来了,又请了个配菜师,两个配菜师关系是集群。
集群是个物理形态,分布式是个工作方式。
只要是一堆机器,就可以叫集群,他们是不是一起协作着干活,这个谁也不知道;一个程序或系统,只要运行在不同的机器上,就可以叫分布式,嗯,C/S架构也可以叫分布式。
集群一般是物理集中、统一管理的,而分布式系统则不强调这一点。
所以,集群可能运行着一个或多个分布式系统,也可能根本没有运行分布式系统;分布式系统可能运行在一个集群上,也可能运行在不属于一个集群的多台(2台也算多台)机器上。
解释下单机结构、集群结构、分布式结构三种结构的区别
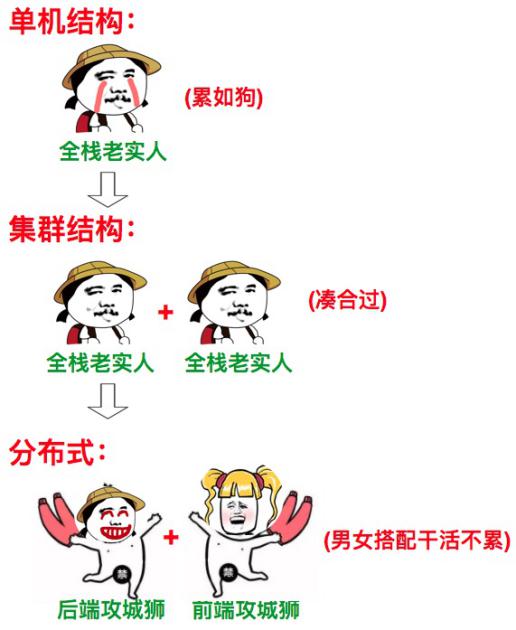
分布式结构就是将一个完整的系统,按照业务功能,拆分成一个个独立的子系统,在分布式结构中,每个子系统就被称为“服务”。这些子系统能够独立运行在web容器中,它们之间通过RPC(远程过程调用)方式通信。
举个例子,假设需要开发一个在线商城。按照微服务的思想,我们需要按照功能模块拆分成多个独立的服务,如:用户服务、产品服务、订单服务、后台管理服务、数据分析服务等等。这一个个服务都是一个个独立的项目,可以独立运行。如果服务之间有依赖关系,那么通过RPC(远程过程调用)方式调用。
这样的好处有很多:
系统之间的耦合度大大降低,可以独立开发、独立部署、独立测试,系统与系统之间的边界非常明确,排错也变得相当容易,开发效率大大提升。
系统之间的耦合度降低,从而系统更易于扩展。我们可以针对性地扩展某些服务。假设这个商城要搞一次大促,下单量可能会大大提升,因此我们可以针对性地提升订单系统、产品系统的节点数量,而对于后台管理系统、数据分析系统而言,节点数量维持原有水平即可。
服务的复用性更高。比如,当我们将用户系统作为单独的服务后,该公司所有的产品都可以使用该系统作为用户系统,无需重复开发。
2. scrapy-redis架构
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取。但是当我们要爬取的页面非常多的时候,单个主机的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时候分布式爬虫的优势就显现出来。
而Scrapy-Redis则是一个基于Redis的Scrapy分布式组件。它利用Redis对用于爬取的请求(Requests)进行存储和调度(Schedule),并对爬取产生的项目(items)存储以供后续处理使用。scrapy-redi重写了scrapy一些比较关键的代码,将scrapy变成一个可以在多个主机上同时运行的分布式爬虫。
2.1 scrapy-redis提供了下面四种组件
scrapy-redis在scrapy的架构上增加了redis提供了下面四种组件(components)(四种组件意味着这四个模块都要做相应的修改):
1)Scheduler(调度器)
2)Duplication Filter(requst的去重过滤器)
3)Item Pipeline(将Item存储在redis中以实现分布式处理)
4)Base Spider
css选择器
要使用css对HTML页面中的元素实现一对一,一对多或者多对一的控制,这就需要用到CSS选择器。
HTML页面中的元素就是通过CSS选择器进行控制的。

HTTP是Hyper Text Transfer Protocol(超文本传输协议)的缩写。HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型。HTTP是一个无状态的协议。
HTTP协议通常承载于TCP协议之上,有时也承载于TLS或SSL协议层之上,这个时候,就成了我们常说的HTTPS。
TCP/IP协议
中译名为传输控制协议/因特网互联协议,又名网络通讯协议,是Internet最基本的协议、Internet国际互联网络的基础,由网络层的IP协议和传输层的TCP协议组成。TCP/IP 定义了电子设备如何连入因特网,以及数据如何在它们之间传输的标准。协议采用了4层的层级结构,每一层都呼叫它的下一层所提供的协议来完成自己的需求。通俗而言:TCP负责发现传输的问题,一有问题就发出信号,要求重新传输,直到所有数据安全正确地传输到目的地。而IP是给因特网的每一台联网设备规定一个地址。
TCP
TCP是面向连接的通信协议,通过三次握手建立连接,通讯完成时要拆除连接,由于TCP是面向连接的所以只能用于端到端的通讯。
反向解析
Url

HTML网页

冒泡排序算法的原理如下:
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
冒泡排序
描述
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地
进行直到没有再需要交换,也就是说该数列已经排序完成。
代码实现
1 # 冒泡排序 2 3 def bubble_sort(lists): 4 5 # 将 lists 列表长度赋值给 count 6 7 count = len(lists) 8 9 # 遍历 lists 中每一个位置 10 11 for i in range(0, count): 12 13 # 遍历当前项的下一项 14 15 for j in range(i + 1, count): 16 17 # 如果当前项的值小于下一项的值,则交换位置 18 19 if lists[i] > lists[j]: 20 21 lists[i], lists[j] = lists[j], lists[i] 22 23 # 将排序后的列表返回 24 25 return lists
1--100的质数
1 num=[]; 2 3 i=2 4 5 for i in range(2,100): 6 7 j=2 8 9 for j in range(2,i): 10 11 if(i%j==0): 12 13 break 14 15 else: 16 17 num.append(i) 18 19 print(num)
队列 栈互相转换
Python有队列没有栈
队列先进先出
栈 先进后出
列表操作
Pip 删除
Append 添加
Insert 插入
问题描述:实现栈与队列的互相转化。
分析:曾今碰到过的一个面试题目,面试官要求如何用队列实现栈,有这个问题进而又引出了如何用栈实现队列,和大家分享下。
解法:
用队列实现栈:栈的特点是先进后出,而队列的特点是先进先出,只用一个队列是不可能实现栈的,因此可以使用两个队列来实现
设两个队列分别是Q1和Q2,当需要将元素压栈时,将元素进入队列Q1,如果要出栈,则将Q1中的除最后一个元素之外的所有元素
出队列,并进入队列Q2,这样就完成了一次出栈。如果再次进栈,只需要将元素进入目前的非空对列中即可,如果要出栈,则把非空
队列中的前几个元素再次出栈,并进入到另一个队列即可。如此反复,就实现了栈的功能。
总结如下:
压栈:向非空队列中压入即可。
出栈:将非空对列中的所有元素出队列,并将其进入到另一个空队列中,但最后一个元素不进入,直接扔掉即可。
用栈实现队列:同样需要利用栈和队列的特点。用两个栈实现队列。
设两个队列为S1和S2,当元素进队时,将元素压入栈S1中,出队时将S1中全部元素弹出并压入栈S2,最后一个元素不压入栈S2,
直接扔掉,然后把栈S2中全部元素出栈,并压入S1中,当再次需要进队时把元素压入S1中,需要出队时,再次移到S2中,如此反复,
就实现了队列的功能。
总结如下:
进队:向非空栈中压入元素。
出队:将非空栈中全部元素出栈并压入另一个栈中,但最后一个元素不压入,直接将其扔掉,然后把栈中所有的元素出栈,并压入原来的栈中。
由于比较简单,我就不再编程实现了,读者可以自己编程验证。