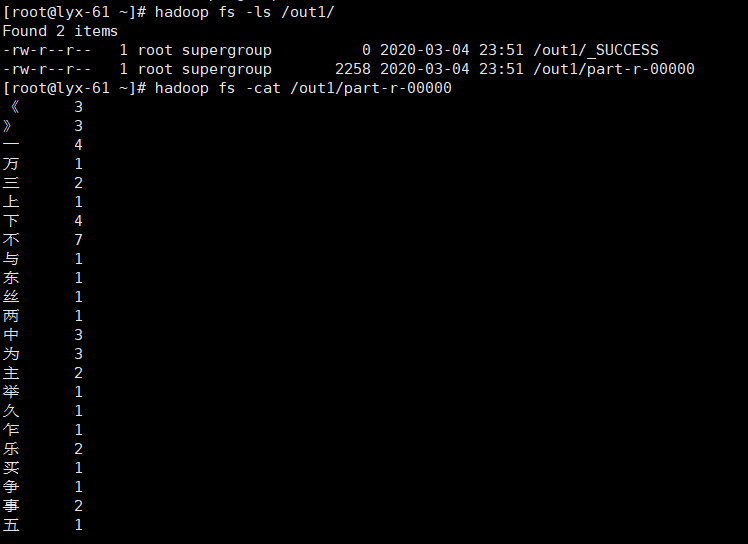
运用MapReduce来统计一个文章的重复的字数
1.准备一篇文章,并且上传到hdfs

注意编码是要utf-8 这样上传到liunx上面才不会乱码

先上传到linux :rz

在上传到hdfs :hadoop fs -put 琵琶行.txt /

2.写MapReduce程序
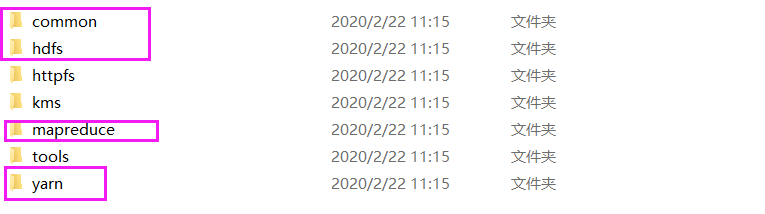
MapReduce基于yarn组件,想要做MapReduce就必须先开启hdfs和yarn。所以我们需要导入common包、hdfs包、yarn包和MapReduce包。jar包位置位于hadoop/share/hadoop里。将common、hdfs、yarn、MapReduce文件夹下的所有jar包及其依赖包导入到项目中。
Mapper阶段:Map必须得继承Mapper类,并且重写mapper方法,Map类会输出成一个文件temp。之后reduce阶段会使用这个文件。
temp里面的相同的key聚集起来。
/*
* KEYIN 表示我们当前读取一个文件[qqq.txt] 读到多少个字节了 数量词
* VALUEIN 表示我们当前读的是文件的多少行 逐行读取 表示我们读取的一行文字
* KEYOUT 我们执行MAPPER之后 写入到文件中KEY的类型
* VALUEOUT 我们执行MAPPER之后 写入到文件中VALUE的类型
* */
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{
public void map(LongWritable ikey, Text ivalue, Context context) throws IOException, InterruptedException {
//去掉 , 。 ?
char[] charArray = ivalue.toString().replace(",", "").replace("。", "").replace("?", "").toCharArray();
for (char c : charArray) {
//写入到一个临时文件中
context.write(new Text(String.valueOf(c)), new IntWritable(1));//写入到临时文件当中
}
}
}
Reduce阶段:必须得继承Reducer类,重写reduce方法
/**
* KEYIN Text
* VALUEIN IntWritbale
* KEYOUT Text 我们Reduce之后 这个文件中内容的 Key是什么
* VALUEOUT IntWritable 这个文件中内容Value是什么
*/
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum=0;
for(IntWritable value:values)
{
sum+=value.get();
}
context.write(key,new IntWritable(sum));
}
}
Job阶段:配置信息
/**
* Driver这个类 用来执行一个任务 Job
* 任务=Mapper+Reduce+HDFS
* 把他们3者 关联起来
*/
public class WordCountJob {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.43.61:9000"); //指定使用的hdfs文件系统
Job job = Job.getInstance(conf, "WordCount"); //任务名
job.setJarByClass(WordCountJob.class); //指定job类
// TODO: specify a mapper
job.setMapperClass(WordCountMapper.class); //指定mapper类
// TODO: specify a reducer
job.setReducerClass(WordCountReduce.class); //指定reduce类
job.setMapOutputKeyClass(Text.class); //指定map输出的key数据格式
job.setMapOutputValueClass(IntWritable.class); //指定map输出的value数据格式
// TODO: specify output types
job.setOutputKeyClass(Text.class); //指定reduce输出的key数据格式
job.setOutputValueClass(IntWritable.class); //指定reduce输出的value数据格式
// TODO: specify input and output DIRECTORIES (not files)
FileInputFormat.setInputPaths(job, new Path("/琵琶行.txt")); //指定需要计算的文件或文件夹
FileOutputFormat.setOutputPath(job, new Path("/out1/")); //指定输出文件保存位置,此文件夹不得存在
if (!job.waitForCompletion(true))
return;
}
}
3.打成jar包,上传到linux。




rz 上传到虚拟机

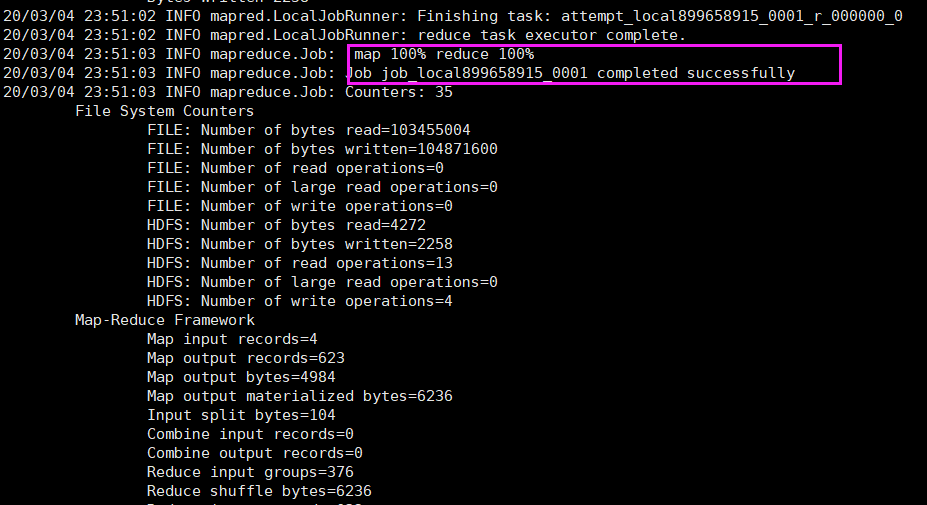
4.运行jar包:hadoop jar wordcount.jar

运行完成
5.查看最后结果文件