前两篇博客分别对拉勾中关于 python 数据分析有关的信息进行获取(https://www.cnblogs.com/lyuzt/p/10636501.html)和对获取的数据进行可视化分析(https://www.cnblogs.com/lyuzt/p/10643941.html),这次我们就用 sklearn 对不同学历和工作经验的 python 数据分析师做一个简单的工资预测。由于在前面两篇博客中已经了解了数据集的大概,就直接进入正题。
一、对薪资进行转换
在这之前先导入模块并读入文件,不仅有训练数据文件,还有一组自拟的测试数据文件。
import pandas as pd import numpy as np import matplotlib.pyplot as plt train_file = "analyst.csv" test_file = "test.csv" # 读取文件获得数据 train_data = pd.read_csv(train_file, encoding="gbk") train_data = train_data.drop('ID', axis=1) test_data = pd.read_csv(test_file, encoding="gbk") train_data.shape, test_data.shape
为了更好地进行分析,我们要对薪资做一个预处理。由于其分布比较散乱,很多值的个数只有1。为了不造成过大的误差,根据其分布情况,可以将它分成【5k 以下、5k-10k、10k-20k、20k-30k、30k-40k、40k 以上】,为了更加方便我们分析,取每个薪资范围的中位数,并划分到我们指定的范围内。
salarys = train_data['薪资'].unique() # 获取到薪资的不同值 for salary in salarys: # 根据'-'进行分割并去掉'k',分别将两端的值转换成整数 min_sa = int(salary.split('-')[0][:-1]) max_sa = int(salary.split('-')[1][:-1]) # 求中位数 median_sa = (min_sa + max_sa) / 2 # 判断其值并划分到指定范围 if median_sa < 5: train_data.replace(salary, '5k以下', inplace=True) elif median_sa >= 5 and median_sa < 10: train_data.replace(salary, '5k-10k', inplace=True) elif median_sa >= 10 and median_sa < 20: train_data.replace(salary, '10k-20k', inplace=True) elif median_sa >= 20 and median_sa < 30: train_data.replace(salary, '20k-30k', inplace=True) elif median_sa >= 30 and median_sa < 40: train_data.replace(salary, '30k-40k', inplace=True) else: train_data.replace(salary, '40k以上', inplace=True)
处理完成后,我们可以将“薪资”单独提取出来当作训练集的 label。
y_train = train_data.pop('薪资').values
二、对变量进行转换
把category的变量转变成numerical表达式
由于变量都不是numerical变量,在训练的时候计算机没办法识别,因此要对它们进行转换。 当我们用numerical来表达categorical的时候,要注意,数字本身有大小的含义,所以乱用数字会给之后的模型学习带来麻烦。于是我们可以用One-Hot的方法来表达category。
pandas自带的get_dummies方法,可以一键做到One-Hot。 这里按我的理解解释一下One-Hot:比如说data['学历要求']有'大专', '本科', '硕士', '不限'。但data['学历要求']=='本科',则他可以用字典表示成这样{'大专': 0, '本科':1, '硕士':0, '不限':0},用向量表示为[0, 1, 0, 0] 。
在此之前,将测试集和训练集组合起来一起处理,稍微方便一点。
data = pd.concat((train_data, test_data), axis=0) dummied_data = pd.get_dummies(data) dummied_data.head()
为了更好地理解 One-Hot ,把处理后的结果展示出来,得到的结果是这样的:

当然,也可以用别的方法,比如用数字代替不同的值,这也是可以的。
上次可视化分析的时候就已经知道数据集中不存在缺失值了,为了走一下流程并确保正确性,再次看一下是否有缺失值。
dummied_data.isnull().sum().sort_values(ascending=False).head(10)

OK,很好,没有缺失值。这些值比较简单,不需要做那么多工作,但还是要先把训练集和测试集分开。
X_train = dummied_data[:train_data.shape[0]].values
X_test = dummied_data[-test_data.shape[0]:].values
三、选择参数
1、DecisionTree(决策树)
from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import cross_val_score features_scores = [] max_features = [.1, .2, .3, .4, .5, .6, .7, .8, .9] for max_feature in max_features: clf = DecisionTreeClassifier(max_features=max_feature) features_score = cross_val_score(clf, X_train, y_train, cv=5) features_scores.append(np.mean(features_score)) plt.plot(max_features, features_scores)
这个过程主要是通过交叉验证获得使模型更好时的参数,交叉验证大概可以理解为,把训练集分成几部分,然后分别把他们设置为训练集和测试集,重复循环训练得到的结果取平均值。Emmm... 感觉这样讲还是有点笼统,还是上网查来得详细吧哈哈。
然后我们得到的参数和值得关系如图所示:
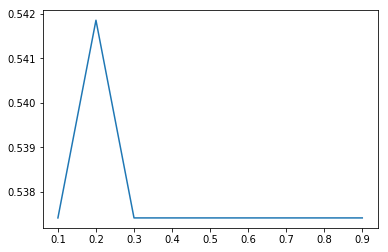
可见当 max_features = 0.2 时达到最大,大概有0.5418。
2、ensemble(集成算法)
集成学习简单理解就是指采用多个分类器对数据集进行预测,从而提高整体分类器的泛化能力。这里将采用sklearn 的 AdaBoostClassifier(adaptive boosting) 通过改变训练样本的权值,学习多个分类器,并将这些分类器进行线性组合,提高泛化性能。
from sklearn.ensemble import AdaBoostClassifier n_scores = [] estimator_nums = [5, 10, 15, 20, 25, 30, 35, 40] for estimator_num in estimator_nums: clf = AdaBoostClassifier(n_estimators=estimator_num, base_estimator=dtc) n_score = cross_val_score(clf, X_train, y_train, cv=5) n_scores.append(np.mean(n_score)) plt.plot(estimator_nums, n_scores)
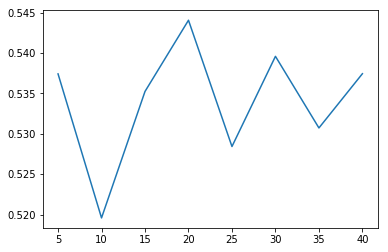
当 estimators=20 的时候,score最高,大概有0.544,虽然跟单个决策树的 score 的值相差不大,但总体还是有所提升。
四、建立模型
参数选择完毕,就可以建立模型了。
dtc = DecisionTreeClassifier(max_features=0.2) abc = AdaBoostClassifier(n_estimators=20)
# 训练
abc.fit(X_train, y_train)
dtc.fit(X_train, y_train)
# 预测
y_dtc = dtc.predict(X_test)
y_abc = abc.predict(X_test)
test_data['薪资(单个决策树)'] = y_dtc
test_data['薪资(boosting)'] = y_abc
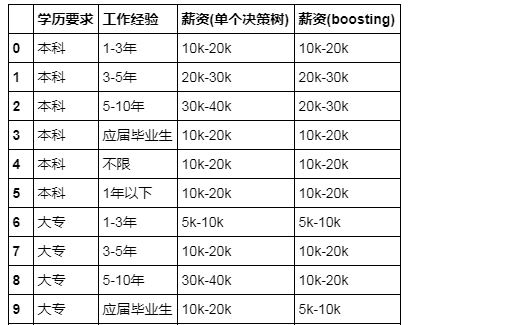
至于结果,总不可能预测得很完美,而且不同模型的结果也会有所不同,更何况它预测出来的结果是否符合常理还有待商榷,所以就把它当作一个小项目就好了,具体代码在这里:https://github.com/MaxLyu/Lagou_Analyze