一.查询分类
1.基本查询:
使用elasticsearch内置查询条件进行查询。
2.组合查询:
把多个查询组合在一起进行复合查询。
3.过滤:
查询同时,通过filter条件在不影响打分的情况下筛选数据。
二.设置索引和映射
1.建立lagou索引:
PUT lagou { "mappings": { "jobs": { "properties": { "title":{ #保存该字段 "store":true, "type":"text", #分析方式为ik_max_word "analyzer": "ik_max_word" }, "salary_min": { "type":"integer" }, "city":{ "store": true, "type":"keyword" }, "Company":{ "properties":{ "name":{ "type":"text" }, "address":{ "type":"text" } } }, "pub-date":{ "type":"date", "format": "yyyy-MM-dd" } } } } }
2.插入数据:
PUT lagou/job/1 { "title":"Java后端研发", "salary_min":20000, "city":"北京", "Company":{ "name":"百度", "address":"北京" }, "pub_date":"2018-10-28" } PUT lagou/job/2 { "title":"Python分布式爬虫", "salary_min":20000, "city":"成都", "Company":{ "name":"美团", "address":"成都" }, "pub_date":"2018-10-27" } PUT lagou/job/3 { "title":"前端研发", "salary_min":20000, "city":"北京", "Company":{ "name":"阿里", "address":"北京" }, "pub_date":"2018-10-28" } PUT lagou/job/4 { "title":"Python后端", "salary_min":20000, "city":"成都", "Company":{ "name":"美团", "address":"成都" }, "pub_date":"2018-10-27" }
3.elasticsearch-ik介绍:https://github.com/medcl/elasticsearch-analysis-ik
支持的解析方法:

三.基本查询
1.match查询:会对输入进行分词,然后到指定的字段去搜索有相同的词(ik分词会自动将大小写转换),注类型为keywords的不会分词,包含也搜索不到GET lagou/_search
{ "query": { "match": { #python大小写都行,ik会把输入分词为“python”和“哈哈” "title": "python哈哈" } }
}

2.term查询:不会分词,只有在搜索的字段中完全包含匹配输入内容才行
GET lagou/_search { "query": { "term": { #为python就有两条数据,以下返回为空 "title": "python哈哈" } } }

3.terms查询:传递数组,任何一个满足都返回
GET lagou/_search { "query": { "terms": { "title": ["python哈哈","python"] } } }
4.match数量控制:
GET lagou/_search { "query": { "match": { "title": "python" } }, #从第二条数据开始 "from":1, #只显示两条 "size":2 }
5.match_all查询:查询lagou所有:
GET lagou/_search { "query": { "match_all": {} } }
6.match_phrase查询:(短语查询)就像 match 查询对于标准全文检索是一种最常用的查询一样,当你想找到彼此邻近搜索词的查询方法时,就会想到 match_phrase 查询
GET lagou/_search { "query": { "match_phrase": { #会对python系统分词为“python”和“系统”,然后查询满足所有的词才返回 "title": { "query": "python系统",
#slop是python和系统之间的最小距离(距离小于等于6就能搜索到) "slop":6 } } } }
7.multi_match查询:可以指定多个字段查询,如city和address包含北京的文档(或关系,只要有一个包含就行)
GET lagou/_search { "query": { "multi_match": { "query": "北京",
#^3之类的表示权重,打分会更高,即title的权重比address高 "fields": ["city^3","address"] } } }
8.指定返回字段:
GET lagou/_search { #指定返回字段title,city,只能是指明字段是为store的,其他的指明也无法返回 "stored_fields": ["title","city"], "query": { "match": { "title": "python哈哈" } } }
9.通过sort排序:
GET lagou/_search { "query": { "match": { "title": "python" } }, #查询结果以salary_min字段升序排序,"desc"为降序 "sort":[{ "salary_min":{ "order":"asc" } }] }
10.指定范围(range查询):
GET lagou/_search { "query": { #查询字段salary_min为大于等于10000,且小于等于20000的字段,boost为权重 "range": { "salary_min": { "gte": 10000, "lte": 20000, "boost": 2 } } } }
11.wildcard查询:允许通配符
GET lagou/_search { "query": { "wildcard": { "title": { "value": "py*","boost":2 } } } }
四.组合查询
1.bool查询:老版本的filtered已经被bool替换
1.1bool查询包含:nust,must_not,should,filter来完成:
must:文档 必须 匹配这些条件才能被包含进来。
must_not:文档 必须不 匹配这些条件才能被包含进来。
should:如果满足这些语句中的任意语句,将增加 _score ,否则,无任何影响。它们主要用于修正每个文档的相关性得分。
filter:必须 匹配,但它以不评分、过滤模式来进行。这些语句对评分没有贡献,只是根据过滤标准来排除或包含文档。
1.2数据插入:
POST testdb/testype/_bulk {"index":{"_id":1}} {"salary":1000,"title":"Python"} {"index":{"_id":2}} {"salary":1200,"title":"Django"} {"index":{"_id":3}} {"salary":1300,"title":"Scrapy"} {"index":{"_id":4}} {"salary":1400,"title":"Elasticsearch"}
1.3最简单的filter查询:(相当于select * from testype where salary=1300)
#查询薪资为1300的 GET testdb/testype/_search {"query":{ "bool":{ #取出所有数据,不要must也可以,默认取所有的数据 "must": { "match_all": {} }, #筛选薪资为1300的 "filter": { "term": { "salary":1300 } } } } }
1.4查询多个值:(相当于select * from testype where salary=1000 or salary=1300)
GET testdb/testype/_search {"query":{ "bool":{ "must": { "match_all": {} }, "filter": { #查询工资为1000和1300的 "terms": { "salary":[1000,1300] } } } } }
1.5查询不到结果:
GET testdb/testype/_search {"query":{ "bool":{ "must": { "match_all": {} }, "filter": { #title的类型是text,在建立索引时会预处理,将大写转换为小写,而term表示不进行处理,因此搜索不到,而match能查询到或则在建立索引时设置title的属性index=false不进行倒排索引 "term": { "title":"Python" } } } } }
1.6查看分析器解析结果:
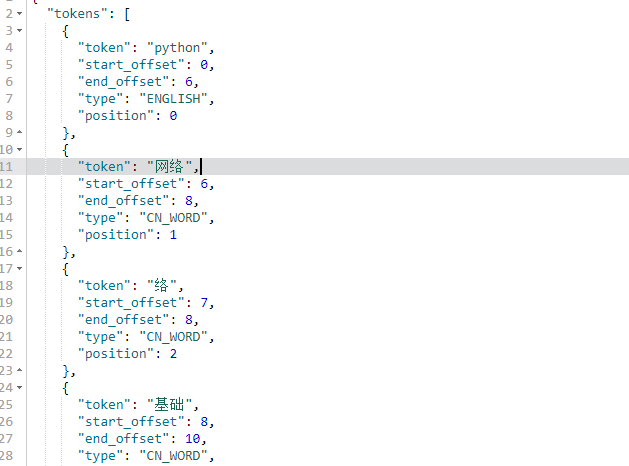
1.6.1ik_max_word:
GET _analyze { "analyzer": "ik_max_word", "text": "Python网络基础学习" }
1.6.2ik_smart:
GET _analyze { "analyzer": "ik_smart", "text" : "Python网络基础学习" }

1.6.3standard(默认):
GET _analyze { "analyzer": "standard", "text" : "Python网络基础学习" }

1.7bool过滤查询,可以做组合过滤查询:(如查询salary为1200或者title为Python的且排除salary为1000的)
select * from testype where (salary=1200 or title="Python") and salary!=1000
GET testdb/testype/_search { "query": { "bool": { "should": [ {"term": {"salary": 1200}}, {"term": {"title":"python"}} ], "must_not": [ {"term": {"salary": "1000" }} ] } } }
1.8嵌套查询:
select * from testype where salary=1200 or (salary=1000 and title="python")
GET testdb/testype/_search { "query": { "bool": { "should": [ {"term": { "salary":1200 }}, {"bool": {"must": [ {"term": { "title": "python" }}, {"term": { "salary": 1000 }} ]}} ] } } }
1.9过滤空和非空:
1.9.1数据:
POST testdb2/testype2/_bulk {"index":{"_id":1}} {"tags":["Python","django"]} {"index":{"_id":2}} {"other_field":["Java",null]} {"index":{"_id":3}} {"tags":["C#","GUI"]} {"index":{"_id":4}} {"tags":[null]} {"index":{"_id":5}} {"tags":["C"]}
1.9.2存在tags且不为空:
select tags from testype2 where tags is not NULL
GET testdb2/testype2/_search { "query": { "bool":{ "filter":{ "exists":{ "field":"tags" } } } } }

1.9.3不存在tags或tags为空:
GET testdb2/testype2/_search { "query": { "bool":{ "must_not":{ "exists":{ "field":"tags" } } } } }

2.constant_score 查询:
当我们不关心检索词频率TF(Term Frequency)对搜索结果排序的影响时,可以使用constant_score将查询语句query或者过滤语句filter包装起来。
五.更多:
1.模糊搜索:
#可搜索到Java等等 GET jobbole/artitle/_search { "query": { "fuzzy": { "title":"jav" } } }
编辑距离:是一种字符串之间相似程度的计算方法,入Linux,Liux,两个字符串之间的编辑距离等于等于使一个字符串变成另外一个字符串而进行的:
(1)插入(2)删除(3)替换(4)相邻字符交换位置而进行的操作最小次数

GET jobbole/artitle/_search { "query": { "fuzzy": { "title":{ "value": "linux", #fuzziness是最小编辑距离 "fuzziness": 2,
#前面不变化词的长度 "prefix_length": 0 } } } }
2.搜索自动补全:
POST jobbole/artitle/_search?pretty { "suggest": { #变量名,任意 "title-suggest": { #内容 "text":"java", "completion":{ "field":"suggest", "fuzzy": { "fuzziness":2 } } } } , "_source": "title" }