这个春节真长,闲来无事看看算法视频,不得不说老师讲得透彻深刻、通俗易懂,趁热打铁,做个总结
请听题:给N(1<N<10)个自然数,每个数的范围为1~10000,现在让你以最快的速度判断某一个数是否在这N个数内,不能用现有的HashMap,该如何实现?
最直接反应的解决方法
法一:遍历
法二:排序+二分
......
不符合本文标题,也不够高级...
更高级的做法:开辟一个数组,最大下标为N个数中最大的数,将N个数作为数组的下标,数组所有值默认0,若该数存在,则将该数下标对应得值改成1,判断一个K在不在N个树中,直接判断a[k]是否为1即可
举个栗子:
给定一组数 2,0,17,31,5,判断10是否在其中。
1、建立数组a[30]
2、将a[0]~a[29]的值都默认成0
3、将a[2]、a[0]、a[17]、a[31]、a[5]改成1
4、判断a[10]是否等于1,若是则在其中,否则不在
这就是最基础的hash算法
但是。。。。
有个问题:当最大数据过大时,非常浪费空间。如果题目再加个条件,只给10个空间,怎么办???
取模:10个数,最多就是10个空间。其实就是Hash函数(就是Hash函数,不太懂,)
继续以上述栗子为例
2%10=2 => a[2] = 2
0%10=0 => a[0] = 0
17%10=7 => a[7] = 17
31%10=1 => a[1] = 31
5%10=5 => a[5] = 5
但是。。。。
又有个问题:当有两个或以上的数取模后值一样怎么办??这就叫hash碰撞,也就是hash冲突
使用hash算法时,有很多办法解决hash冲突
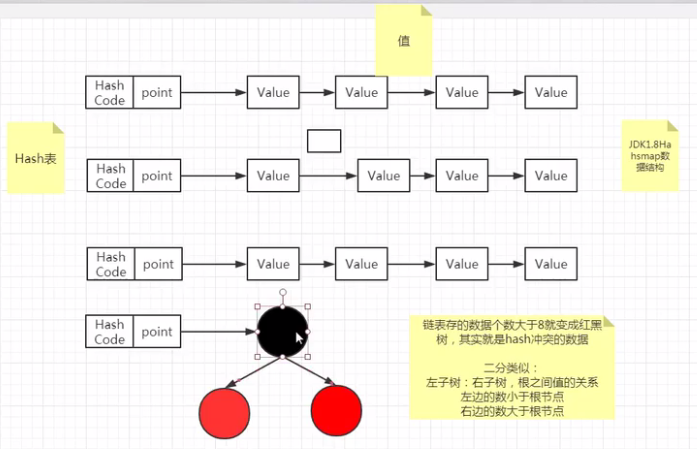
法一:使用链表,jdk1.7的HashMap就是用的该算法
举个栗子:10,2,32,44,77
a[2]=2,32
缺点:当所有数取模后的值都一样的时候,就变成了一个单链表,查找很麻烦
注:Hash的效率取决于冲突的数量,冲突越多,效率就越低,所以一个好的Hash函数可以解决Hash的效率
法二:使用链表+红黑树,当链表节点大于8时,用红黑树,经过测试后总结。jdk1.8 HashMap用的该算法