第12章函数进阶
12-1立即执行函数表达式
立即执行的函数表达式的英文全称为Immediately Invoked Function Expression,简称就为IIFE。这是一个如它名字所示的那样,在定义后就会被立即调用的函数。
我们在调用函数的时候需要加上一对括号,IIFE同样如此。除此之外,我们还需要将函数变为一 个表达式,只需要将整个函数的声明放进括号里面就可以实现。具体的语法如下:
(function(){ //函数体 })() 接下来我们来看一个具体的示例: (function(){ console.log("Hello"); })() // Hello
IIFE可以在执行一个任务的同时,将所有的变量都封装到函数的作用域里面,从而保证了全局的 命名空间不会被很多变量名污染。
这里我可以举一个简单的例子,在以前我们要交换两个数的时候,往往需要声明第三个临时变量
temp
|注:从ES6开始已经不需要这么做了,直接使用结构就可以交换两个数了
let a = 3,b = 5; let temp = a; a = b; b = temp; console.log(a);//5 console.log(b);//3 console.log(temp);//3
这样虽然我们的两个变量被交换了,但是存在一个问题,那就是我们在全局环境下也存在了一个 temp变量,这就可以被称之为污染了全局环境。所以我们可以使用IIFE来解决该问题,如下:
let a = 3,b = 5; (function(a,b){ let temp = a; a = b; b = temp; })(a,b) console.log(a);//3 console.log(b);//5 console.log(temp);//报错
这是一个非常方便的功能,特别是有些时候我们在初始化一些信息时需要一些变量的帮助,但是 这些变量除了初始化之后就再也不会用了,那么这个时候我们就可以考虑使用IIFE来进行初始 化,这样不会污染到全局环境。
( function(){ let days =["星期天",”星期一","星期二",”星期三",”星期四",”星期五",”星期六"]; let date = new Date(); let today = [date.toLocaleDateString(),days[date.getDay()]]; console.log('今天是${today[0]}, ${today[1]},欢迎你回来! '); })() //今天是2017-12-20,星期三,欢迎你回来!
这里我们只是想要输出一条欢迎信息,附上当天的日期和星期几,但是有一个很尴尬的地方在于 上面定义的这些变量我们都只使用一次,后面就不会再用了,所以这个时候我们也是可以考虑使 用IIFE来避免这些无用的变量声明。
通过IIFE,我们可以对我们的代码进行分块。并且块与块之间不会互相影响,哪怕有同名的变量 也没问题,因为IIFE也是函数,在函数内部声明的变量是一个局部变量,示例如下:
(function(){ //block A let name = "xiejie"; console.log('my name is ${name}'); })(); ( function(){ //block B let name = "song"; console.log('my name is ${name}'); })(); // my name is xiejie // my name is song
在var流行的时代,JS是没有块作用域的。什么叫做块作用域呢?目前我们所知的作用域大概 有两种:全局作用域和函数作用域。其中,全局作用域是指声明的变量可在当前环境的任何地方 使用。函数作用域则只能在当前函数所创造的环境中使用。块级作用域是指每个代码块也可以有 自己的作用域,比如在if块中声明一个变量,就只能在当前代码块中使用,外面无法使用。而 用var声明的变量是不存在块级作用域的,所以即使在if块中用var声明变量,它也能在外 部的函数或者全局作用域中使用。
function show(valid){ if(valid){ var a = 100; } console.log('a:',a); } show(true); // 输出a的值为100
这个例子中,a变量是在if块中声明,但是它的外部仍然能输出它的结果。
解决这个问题有两种方法,第一:使用ES6中的let关键字声明变量,这样它就有块级作用域。 第二:使用IIFE,示例如下:
function show(valid){ if(valid){ ( function(){ var a = 100; })(); } console.log('a:',a); } show(true); // 报错:a is not defined
当然,只要浏览器支持,建立尽量使用let的方式来声明变量。
12-2变量初始化
12-2-1执行上下文
在ECMAScript中代码的运行环境分为以下三种:
・全局级别的代码:这是默认的代码运行环境,一旦代码被载入,JS引擎最先进入的就是这个 环境
・函数级别的代码:当执行一个函数时,运行函数体中的代码。
・EvaI级别的代码:在EvaI函数内运行的代码。
为了便于理解,我们可以将"执行上下文"粗略的看做是当前代码的运行环境或者说是作用域。下 面我们来看一个例子,其中包括了全局以及函数级别的执行上下文,如下:
let one = "Hello"; let test = function(){ let two = "Lucy",three = "Bill"; let test2 = function(){ console.log(one,two); } let test3 = function(){ console.log(one,three); } test2(); test3(); } test();
上面这段代码,本身是没有什么意义的,我们主要是要使用这段代码来分析一下里面存在多少个 上下文。在上面的代码中,一共存在4个上下文。一个全局上下文,一个test函数上下文,一个 test2函数上下文和一个test3函数上下文。
通过上面的例子,我们就可以得出下面的结论:
・不管什么情况下,只存在一个全局的上下文,该上下文能被任何其它的上下文所访问到。也 就是说,我们可以在test的上下文中访问到全局上下文中的o ne变量,当然在函数test2或者 test3中同样可以访问到该变量。
・至于函数上下文的个数是没有任何限制的,每到调用执行一个函数时,引擎就会自动新建出 —个函数上下文,换句话说,就是新建一个局部作用域,可以在该局部作用域中声明私有变 量等,在外部的上下文中是无法直接访问到该局部作用域内的元素的。
在上述例子中,内部的函数可以访问到外部上下文中的声明的变量,反之则行不通。那么,这到 底是什么原因呢?引擎内部是如何处理的呢?这需要了解执行上下文堆栈。
执行上下文堆栈
JS引擎的工作方式是单线程的。也就是说,某一个时候只有唯一的一个事件是处于被激活的,其 他的事件都是被放入队列中,等待被处理的。下面的示例图就描述了这样一个堆栈,如下:
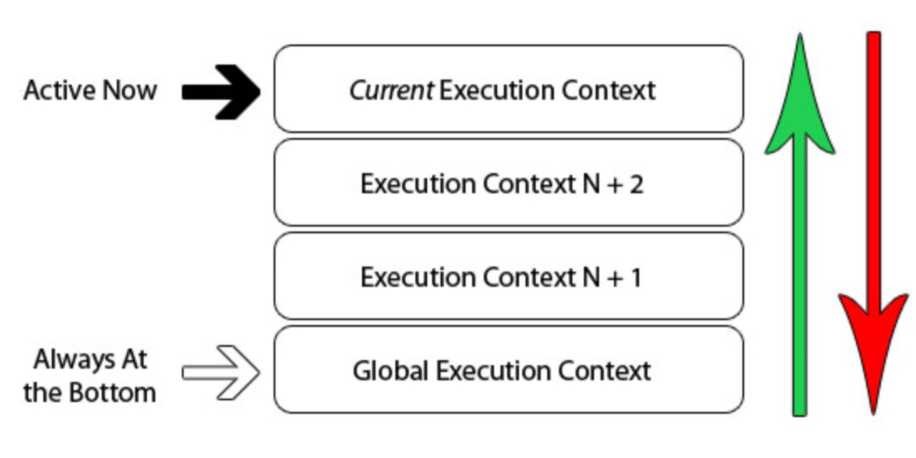
我们已经知道,当JS代码文件被JS引擎载入后,默认最先进入的是一个全局的执行上下文。当 在全局上下文中调用执行一个函数时,程序流就进入该被调用函数内,此时引擎就会为该函数创 建一个新的执行上下文,并且将其压入到执行上下文堆栈的顶部。
JS引擎总是执行当前在堆栈顶部的上下文,一旦执行完毕,该上下文就会从堆栈顶部被弹出,然 后,进入其下的上下文执行代码。这样,堆栈中的上下文就会被依次执行并且弹出堆栈,直到回 到全局的上下文。
来看下面这段代码,分析其一共有多少个上下文:
(function foo(i){
if(i==3){ return; }else{ console.log(i); foo(++i); } })(0); //全局上下文 //函数上下文0 //函数上下文1 //函数上下文2 //函数上下文
上述foo被声明后,通过0运算符强制直接运行了。函数代码就是调用了其自身4次,每次是局部 变量i增加1。每次foo函数被自身调用时,就会有一个新的执行上下文被创建。每当一个上下文执 行完毕,该上下文就被弹出堆栈,回到上一个上下文,直到再次回到全局上下文。所以在本段代 码中一共存在了 5个不同的执行上下文。
由此可见,对于执行上下文这个抽象的概念,可以归纳为以下几点:
・单线程
•同步执行
・唯一的一个全局上下文
・函数的执行上下文的个数没有限制
・每次某个函数被调用,就会有个新的执行上下文为其创建,即使是调用的自身函数,也是如此。
12-2-2函数上下文的建立与激活
我们现在已经知道,每当我们调用一个函数时,一个新的执行上下文就会被创建出来。然而,在 js引擎的内部,这个上下文的创建过程具体分为两个阶段,分别是建立阶段和代码执行阶段。这 两个阶段要做的事儿也不一样。
建立阶段:发生在当调用一个函数,但是在执行函数体内的具体代码之前
•建立变量对象(arguments对象,形式参数,函数和局部变量)
•初始化作用域链
・确定上下文中this的指向对象
代码执行阶段:发生在具体开始执行函数体内的代码的时候
・执行函数体内的每一句代码
我们将建立阶段称之为函数上下文的建立,将代码执行阶段称之为函数上下文的激活。
变量对象
在上面介绍函数两个阶段中的建立阶段时,提到了一个词,叫做变量对象。这其实是将整个上下 文看做是一个对象以后得到的一个词语。具体来讲,我们可以将整个函数上下文看做是一个对 象,那么既然是对象,对象就应该有相应的属性。对于我们的执行上下文来说,有如下的三个属 性:
executionContextObj = {
variableObject : {}, //变量对象,里面包含arguments对象,形式参数,函数和局部变量 scopeChain : {},//作用域链,包含内部上下文所有变量对象的列表 this : {}//上下文中this的指向对象
}
可以看到,这里我们的执行上下文对象有3个属性,分别是变量对象,作用域链以及this,这里我 们重点来看一下变量对象里面所拥有的东西。
在函数的建立阶段,首先会建立arguments对象。然后确定形式参数,检查当然上下文中的函数 声明,每找到一个函数声明,就在variableObject下面用函数名建立一个属性,属性值就指向该 函数在内存中的地址的一个引用。如果上述函数名已经存在于variableObject(简称V0)下面,那 么对应的属性值会被新的引用给覆盖。最后,是确定当前上下文中的局部变量,如果遇到和函数 名同名的变量,则会忽略该变量。
好,接下来我们来通过一个实际的例子来演示函数的这两个阶段以及变量对象是如何变化的。
let foo = function(i){ var a = "Hello"; var b = function privateB(){}; function c(){} } foo(10); 首先在建立阶段的变量对象如下: fooExecutionContext = { variavleObject : { ar guments : {0 : 10,length : 1}, // 确定arguments 对象 i : 0,//确定形式参数 c : pointe r to function c(),//确定函数引用 a : undefined,//局部变量 初始值为undefined b : undefined //局部变量 初始值为undefined }, scopeChain : {}, this : {} }
由此可见,在建立阶段,除了arguments,函数的声明,以及形式参数被赋予了具体的属性值 外,其它的变量属性默认的都是undefinedo并且普通形式声明的函数的提升是在变量的上面 的。
—旦上述建立阶段结束,引擎就会进入代码执行阶段,这个阶段完成后,上述执行上下文对象如
下,变量会被赋上具体的值。
接下来我们再通过一段代码来加深对函数这两个阶段的过程的理解,代码如下:
(function(){ console.log(typeof foo); console.log(typeof bar); var foo = "Hello"; var bar = function(){ return "World"; } function foo(){ return "good"; } console.log(foo,typeof foo); })()
这里,我们定义了一个IIFE,该函数在建立阶段的变量对象如下:
fooExecutionContext = { variavleObject : { arguments : {length : 0}, foo : pointer to function foo(), bar : undefined
}, scopeChain : {}, this : {}
首先确定arguments对象,接下来是形式参数,由于本例中不存在形式参数,所以接下来开始确 定函数的引用,找到foo函数后,创建foo标识符来指向这个foo函数,之后同名的foo变量不会再 被创建,会直接被忽略。然后创建bar变量,不过初始值为undefined。
建立阶段完成之后,接下来进入代码执行阶段,开始一句一句的执行代码,结果如下:
(function(){ console.log(typeof foo);//function console.log(typeof bar);//undefined var foo = "Hello";//foo被重新赋值变成了一个字符串 var bar = function(){ return "World"; } function foo() { return "good"; } console.log(foo,typeof foo);//Hello string })()
12-2-3作用域链
前面在讲解函数上下文时,我们将上下文看做了是一个对象,这个对象有3个属性,分别是变量 对象,作用域链以及this指向。关于this指向我们之前已经介绍过了,变量对象也在上面做了相关 的介绍,最后我们就一起来看一下这个作用域链。
所谓作用域链,就是内部上下文所有变量对象(包括父变量对象)的列表。此链主要是用于变量查 询。
关于作用域链,有一^公式作用域链(ScopeChain) = AO + [[scope]]
其中A0,简单来说就是VO, AO全称为active object(活动对象),对于当前的上下文来讲,一般 将其称之为A0,对于不是当前的上下文,一般被称为V0
[[scope]]:所有父级变量对象的层级列表(也被称之为层级链) 举个例子:
var x = 10; function foo() { var y = 20; console.log(x + y); } foo();//30 这里,我们来分析一下VO和AO //全局 VO : x : 10 foo : pointer to foo() //foo函数上下文 AO : y : 20 ScopeChain : AO(y) + [[scope]](VO:x)
这里,在全局上下文下的VO就是一个x变量,而在foo函数上下文下面,AO有一个变量y,接下来 是作用域链。作用域链等于当前上下文的AO加上父级的VO,所以在函数内部虽然没有变量x,但 是通过作用域链我们找到了父级上下文下面有一个变量x,然后拿来使用。
关于[[scope]],有一个一个非常重要的特性,那就是[[scope]]是在函数创建的时候,就已经被存 储了,是静态的。所谓静态,就是说永远不会变,函数可以永远不被调用,但是[[scope]]在创建 的时候就已经被写入了,并且存储在函数作用域链对象里面。我们来举一个例子说明,如下:
let food = "rice"; let eat = function(){ console.log('eat ${food}'); }; ( function(){ let food = "noodle"; eat();//eat rice })();
这里的结果为eat rice,原因非常简单。因为对于eat()函数来讲,创建的时候它的父级是全局 上下文,所以[[scope]]里面就存储了全局上下文的VO,所以food的值为rice。如果我们将代码稍 作修改,改成如下:
let food = "rice"; ( function(){ let food = "noodle"; let eat = function(){ console.log('eat ${food}'); }; eat();//eat noodle })();
那么这个时候打印出来的值就为eat noodle。因为对于eat()函数来讲,这个时候它的父级为
IIFE,所以[[scope]]里面存储的是IIFE这个函数上下文的VO, food的值为noodle。
最后,我们用一个稍微复杂一些的例子来贯穿上面所介绍的作用域链。
var x = 10; function foo() { var y = 20; function bar() { var z = 30; console.log(x + y + z); } bar(); } foo();// 60
在这里,我们来分析一下变量对象,函数的[[scope]]属性以及上下文作用域链的变化。 首先,刚开始的时候是全局上下文的变量对象:
globalContext.VO = {
x : 10,
foo : pointer to foo()
}
在foo()函数被创建时,此时foo()函数的[[scope]]属性为:
foo.[[scope]] = [ globalContext.VO
];
之后,foo()函数会被激活,确定foo()函数里面的活动对象:
fooContext.AO = { y : 20, bar : pointer to bar()
}
此时foo()函数上下文里面的作用域链的结构为:
fooContext.Scope = fooContext.AO + foo.[[scope]] fooContext.Scope = [
fooContext.AO,
globalContext.VO
当内部函数bar ()函数被创建时,其[[scope]]为:
bar.[[scope]] = [
fooContext.AO, globalContext.VO
];
当bar ()函数被激活,拥有活动对象时,bar()函数的活动对象如下:
barContext.AO = {
z : 30
}
此时bar ()函数上下文的作用域链的结构为:
barContext.Scope = barContext.AO + bar.[[scope]] barContext.Scope = [ barContext.AO, fooContext.AO, globalContext.VO
]
最后总结一下:函数的[[scope]]属性是在函数创建时就确定了,而变量对象则是在函数激活时,
也就是说调用函数时才会确定。
12-3闭包
对于JavaScript程序员来说,闭包(closure)是一个难懂又必须征服的概念。接下来我将从四个方 面来描述闭包的概念:
・为什么要使用闭包
•什么是闭包
•闭包的原理
•闭包的作用和使用
12-3-1闭包基本介绍
首先我们来看看为什么要使用闭包,先看下面这个例子:
var eat = function(){ var food ="鸡翅"; console.log(food); } eat();
例子中声明了一个名为eat的函数,并对它进行调用。js引擎会创建一个eat的执行上下文,其中 声明food变量并赋值。当该方法执行完后,上下文被销毁,food变量也会跟着消失。这是因为 food变量属于eat函数的局部变量,它作用于eat函数中,会随着eat的执行上下文创建而创建,销 毁而销毁。
再看下面这个例子:
var eat = function(){ var food ="鸡翅"; return function(){ console.log(food); } } var look = eat(); look(); look();
在这个例子中,eat函数返回一个函数,并在这个内部函数中访问food这个局部变量。调用eat函 数并将结果赋给look变量,这个look指向了 eat函数中的内部函数,然后调用它,最终输出food的 值。按照之前的说法,这个food变量应该当eat函数调用完后就销毁,后续为什么还能通过调用
look方法访问到这个变量呢?这是因为闭包起了作用。返回的内部函数和它外部的变量food实际 上就是一个闭包。我们不禁想问,为什么它们称为闭包?闭包又能做什么呢?
我们先来看看闭包的概念:
闭包是指引用了自由变量的函数。这个被引用的自由变量将和这个函数一同存在,即使离开了创造它的环境也不例外。这里提到了自由变量,它又是什么呢?
自由变量可以理解成跨作用域的变量,比如子作用域访问父作用域的变量。
这些概念说起来太过于专业,下面我用一个生活中的例子来解释它。假如小王、小强是某某学校 计算机专业的学生。某一天他们的导师在外面接了一个项目,然后为此成立一个项目组,拉了他 两人加入。他们的这个项目组既在学校中建立,但又可以独立于学校存在。比如,小王和小强从 学校毕业了,他们的项目组仍然可以继续存在。所以,我们可以认为他们组建的这个项目组就是 闭包。下面我把这个例子写成了代码:
var school = function(){ var si ="小强"; var s2 ="小王"; var team = function(project){ console.log(s1 + s2 + project); } return team; } var team = school(); team(“做电商项且“);//小强、小王做电商项目 team(“做微信项且“);//小强、小王做微信项目
变量si和s2属于school函数的局部变量,并被内部函数team使用,同时该函数也被返回出去。 在外部,通过调用scho ol得到了内部函数的引用,后面多次调用这个内部函数,仍然能够访问到 si和s2变量。这样si和s2作为自由变量被tea m函数引用,即使创造它们的函数school执行完 了,这些变量依然存在,因此,这就是闭包。
看到这里,我们需要问自己两个问题:
首先,为什么函数内部可以访问外部函数的变量?
这个问题其实很好解释,在变量初始化那节中提到过,当一个函数在创建时其内部会产生一个 scope属性,该属性指向创建该函数的执行上下文中的作用域链对象。这句话说起来比较绕口, 看看下面这张图:
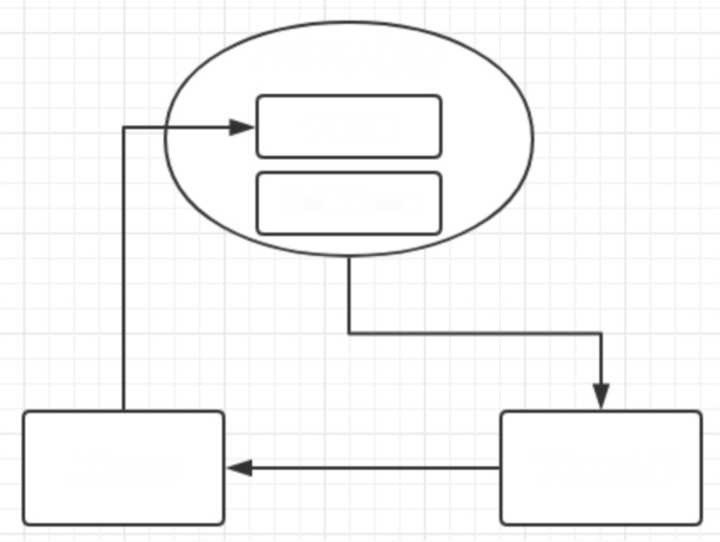
其中作用域链对象包含了该上下文中的VO/AO对象,还有scope对象,比如schoo I上下文中的作 用域链对象就像这样:
school.scopeChain = {
VO:{
si:"小强",
s2:"小王"
},
scope:[[scopeChain]]
}
接下来,咱们就来回答这个问题。当内部函数中找不到对应的变量,它就会到scope指向的对象 中找。该对象保存着外部上下文中的作用域链对象,从该作用域链中就能找到对应的变量。这就 是为什么函数内部可以访问到外部函数变量的原因。下面咱们咱来看看第二个问题:
为什么当外部函数的上下文执行完以后,其中的局部变量还是能通过闭包访问到呢?
其实用上一个问题的答案再延伸一下,这个问题的答案就出来了。你想想,外部函数的上下文即 使结束了,但内部的函数只要不销毁(被外部引用了,就不会销毁),它当中的scope就会一直 引用着刚才上下文的作用域链对象,那么包含在作用域链中的变量也就可以一直被访问到。
把这个理解了,闭包的原理也就明白了。
按照这种说法,在JS中每个函数都有scope对象,并且都会保存外部上下文的作用域链对象。也 就是说,任何时候外部上下文销毁了,只要内部函数还在都能访问到外部的变量。那岂不是任何
函数都可以称为闭包了吗?事实上确实是这样的,从广义上讲,JS的函数都可以称为闭包(因为
它们能访问外部变量)。但我们这里要讲的是狭义上的闭包,这样闭包对于实际应用来讲才会有意
义。
狭义的闭包必须满足两个条件:
・形成闭包环境的函数能够被外部变量引用,这样就算它外部上下文销毁,它依然存在。
・在内部函数中要访问外部函数的局部变量。
后面我提到的闭包都是指要满足这两个条件。下面我们来看看闭包有哪些优缺点,先来看看优 点:
・通过闭包可以让外部环境访问到函数内部的局部变量。
・通过闭包可以让局部变量持续保存下来,不随着它的上下文环境一起销毁。看下面这个例 子:
let count = 0; //全局变量 let compute = function(){ //将计数器加 1 count++; console.log(count); } for( let i = 0 ;i < 100;i++){ compute(); // 循环100 次 } 这个例子是对一个全局变量进行加1的操作,一共加100次,得到值为100的结果。下面用闭包的 方式重构它: var compute = function(){ var count = 0; //局部变量 return function(){ count++; //内部函数访问外部变量 console.log(count); } } var func = compute(); //引用了内部函数,形成闭包 for( var i = 0 ;i < 100;i++){ func(); }
这个例子就不再使用全局变量,其中count这个局部变量依然可以被保存下来。
下面来看看闭包的缺点: 其实闭包本身并没有什么明显的缺点。但往往人们对闭包有种误解:说闭包会将局部变量保存下
来,如果大量使用闭包,而其中的变量又未得到清理,可能会造成内存泄漏。所以要尽量减少闭 包的使用。
局部变量本来应该在函数退出时被解除引用,但如果局部变量被封闭在闭包形成的环境中,那么 这个局部变量就能一直生存下去。从这个角度来看,闭包的确会使一些数据无法被及时销毁。使 用闭包的一部分原因是我们选择主动把一些变量封闭在闭包中,因为可能在以后还需要使用这些 变量。把这些变量放在闭包中和放在全局作用域中,对内存方面的影响是一样的,所以这里并不 能说成是内存泄漏。如果在将来需要回收这些变量,我们可以手动把这些变量设置为n ull。
如果非要说闭包和内存泄漏有关系的地方,那就是使用闭包的同时比较容易形成循环引用,如果 闭包的作用域中保存着一些DOM节点,这个时候就有可能造成内存泄漏。但这本身并非闭包的 问题,也并非JavaScript的问题。在IE浏览器中,由于BOM和DOM中的对象是使用C++以COM 对象的方式实现的,而COM对象的垃圾收集机制采用的是引用计数策略。在基于引用计数策略 的垃圾回收机制中,如果两个对象之间形成了循环引用,那么这两个对象都无法被回收,但循环 引用造成的内存泄漏在本质上也不是闭包造成的。
同样,如果要解决循环引用带来的内存泄漏问题,我们只需要把循环引用中的变量设为n ull即 可。将变量设置为n ull意味着切断变量与它此前引用的值之间的连接。当垃圾收集器下次运行 时,就会删除这些值并回收它们占用的内存。
接下来我们看看到底什么时候会用到闭包。比如我们经常会使用时间函数对某一个变量进行操 作,看这个例子:
let a = 100; setTimeout(function(){ console.log(++a); },1000);
这个例子用到了时间函数setTimeout,并在等待1秒钟后对变量a进行加1的操作。这是一个闭 包,因为setTimeout中的匿名函数对外部变量进行访问,然后该函数又被setTimeout方法引用。 满足了形成闭包的两个条件。所以你看,即使外部上下文结束了,1秒后仍然能对变量a进行加1 操作。
在DOM的事件操作中,也经常用到闭包,比如下面这个例子:
<input id="count" type="button" value="计数"〉 <script> (function(){ var cnt = 0; var count = document.getElementById("count"); count.onclick = function(){ console.log(++cnt); })() </script>
onclick指向的函数中访问了外部变量ent,同时该函数又被o nclick事件引用了,满足两个条件, 是闭包。所以当外部上下文结束后,你继续点击按钮,在触发的事件处理方法中仍然能访问到变 量 ent。
在有些时候闭包还会引起一些奇怪的问题,比如下面这个例子:
for(var i = 1;i <= 3;i++){ setTimeout(function(){ console.log(i); },1000); }
过1秒后分别输出i变量的值为1,2,3。但是,执行的结果是:4,4,4。实际上,问题就出在闭包身 上。你看,循环中的setTimeout访问了它的外部变量i,形成闭包。而i变量只有1个,所以循环3 次的setTimeout中都访问的是同一个变量。循环到第4次,i变量增加到4,不满足循环条件,循 环结束,代码执行完后上下文结束。但是,那3个setTimeout等1秒钟后才执行,由于闭包的原 因,所以它们仍然能访问到变量i,不过此时i变量值已经是4了。
既然是闭包引起的问题,那么解决的方法就是去掉闭包。我们知道形成闭包有两个条件,只要不 满足其一,那就不再是闭包。条件之一,内部函数被外部引用,这个我们没办法去掉。条件二, 内部函数访问外部变量。这个条件我们有办法去掉,比如:
for(var i = 1;i <= 3;i++){ (function(index){ setTimeout(function(){ console.log(index); },1000); })(i) }
这样setTimeout中就可以不用访问for循环声明的变量i了。而是采用调用函数传参的方式把变量i 的值传给了 setTimeout,这样它们就不再形成闭包。也就是说setTimeout中访问的已经不是外部 的变量i,所以即使i的值增长到4,跟它内部也没关系,最后达到了我们想要的效果。
当然,解决这个问题还有个更简单的方法,就是使用ES6中的let关键字。它声明的变量有块作用 域,如果将它放在循环中,那么每次循环都会有一个新的变量i,这样即使有闭包也没问题,因为 每个闭包保存的都是不同的i变量,那么刚才的问题也就迎刃而解。
for(let i = 1;i <= 3;i++){ setTimeout(function(){ console.log(i); },1000); }
12-3-2闭包的更多作用
- 1. 封装变量
闭包可以帮助把一些不需要暴露在全局的变量封装成"私有变量"。假设有一个计算乘积的简单函 数:
//计算传入的数字的乘积
let mult = function(){ let a = 1; for( let i=0;i<arguments.length;i++) { a *= arguments[i]; } return a; } console.log(mult(1,2,3)); // 6
mult函数接受一些number类型的参数,并返回这些参数的乘积。现在我们觉得对于那些相同的 参数来说,每次都进行计算是一种浪费,我们可以加入缓存机制来提高这个函数的性能,如下:
//缓存对象,用于对计算结果进行缓存
let cache = {}; let mult = function(){ //将传入的数字组成字符串作为缓存对象的键 let args = Array.prototype.join.call(arguments,','); if(cache[args]) { return cache[args]; } let a = 1; for( let i=0;i<arguments.length;i++) { a *= arguments[i]; } return cache[args] = a; } console.log(mult(1,2,3)); // 6 console.log(mult(1,2,3)); // 6
我们看到,cache这个变量仅仅是在mult函数中被使用,与其让cache变量跟mult函数一起平行地 暴露在全局作用域下,不如把它封闭在mult函数内部,这样可以减少页面中的全局变量,以避免 这个变量在其他对方被不小心修改而引发错误。代码如下:
let mult = (function(){ //缓存对象,用于结果进行缓存 let cache = {}; return function(){ let args = Array.prototype.join.call(arguments,','); if(cache[args]) { return cache[args]; } let a = 1; for( let i=0;i<arguments.length;i++) { a *= arguments[i]; } return cache[args] = a; } })(); console.log(mult(1,2,3)); // 6 console.log(mult(1,2,3)); // 6
提炼函数是代码重构中的一种常见技巧。如果在一个大函数中有一些代码块能够独立出来,那么 我们常常把这些代码块封装在独立的小函数里面。独立出来的小函数有助于代码的复用,如果这 些小函数有一个良好的命名,它们本身也起到了注释的作用。如果这些小函数不需要在程序的其 他地方使用,那么最好是把它们用闭包封闭起来。重构后的代码如下:
let mult = (function(){ //缓存对象,用于结果进行缓存 let cache = {}; //计算乘积函数和cache—样,该函数同样被闭包封闭了起来 let calc = function(){ let a = 1; for( let i=0;i<arguments.length;i++) { a *= arguments[i]; } return a; } return function(){ let args = Array.prototype.join.call(arguments,','); if(cache[args]) { return cache[args]; } return cache[args] = calc.apply(null,arguments); } })(); console.log(mult(1,2,3)); // 6 console.log(mult(1,2,3)); // 6
- 2. 延续局部变量的寿命
img对象经常用于进行数据上报,如下所示:
let report = function(src){ let img = new Image(); img.src = src; } report('http://xxx.com/getUserInfo');
但是通过查询后台的记录我们得知,因为一些低版本的浏览器的实现存在bug,在这些浏览器下 使用report函数进行数据上报时会丟失30%左右的数据,也就是说‘report函数并不是每一次都 成功发起了 HTTP请求。丟失数据的原因是img是report函数中的局部变量,当report函数在调用 结束后,img局部变量随即被销毁,而此时或许还没来得及发出HTTP请求,所以此次请求就会丟 失掉。
现在我们把img变量用闭包封闭起来,便能解决请求丟失的问题,如下:
let report = (function(){ let imgs = []; return function(src){ let img = new Image(); imgs.push(img); img.src = src; } })();
12-3-3闭包和面向对象设计
过程与数据的结合是形容面向对象中的"对象"时经常使用的表达。对象以属性的形式包含了数 据,以方法的形式包含了过程。而闭包则是在过程中以环境的形式包含了数据。通常用面向对象 思想能实现的功能,用闭包也能够实现,反之亦然。
在JavaScript语言的祖先Scheme语言中,甚至都没有提供面向对象的原生设计,但却可以使用 闭包来实现一个完整的面向对象的系统。下面我们来看看这段跟闭包相关的代码:
let Test = function(){ let value = 0; return { call : function(){ value++; console.log(value); } } } let test = new Test(); test.call();// 1 test.call(); // 2 test.call(); // 3
如果换成面向对象的写法,那就是如下:
let test = { value : 0, call : function(){ this.value++; console.log(this.value); } } test.call(); // 1 test.call(); // 2 test.call(); // 3
或者
let Test = function(){ this.value = 0; } Test.prototype.call = function(){ this.value++; console.log(this.value); } let test = new Test(); test.call(); // 1 test.call(); // 2 test.call(); // 3
12-4递归函数
递归函数是一个一直直接或者间接调用它自己本身,直到满足某个条件才会退出的函数。当需要 设计到迭代过程时,这是一个很有用的工具。下面我们以计算阶乘来进行示例:
let numCalc = function(i){ if(i == 1){ return 1; }else{ return i * numCalc(i-1); } } console.log(numCalc(4));//24
这里,我们要计算4的阶乘,那么我们可以看作是4乘以3的阶乘。而3的阶乘又可以看作是3乘以 2的阶乘,以此类推。
下面是几个常见的递归函数的例子,通过下面的例子可以帮助我们加深对递归函数的理解
1•使用递归计算从m加到n
let numCalc = function (m, n) { if (m === n) { return m; }else { return n + numCalc(m, m > n ? n + 1 : n - 1); } } console.log(numCalc(100, 1));//5050
2•使用递归计算出某一位的斐波那契数
let numCalc = function (i) { if (i == 1) { return 0; }else if (i == 2) { return 1; else { return numCalc(i - 1) + numCalc(i - 2); } } console.log(numCalc(8));//13
3•使用递归打印出多维数组里面的每一个数字
let arr = [1, 2, [3, 4, [5, 6], 7, 8], 9, 10]; let test = function (arr) { for (let i = 0; i < arr.length; i++) { if (typeof arr[i] == 'object') { test(arr[i]); }else { console.log(arr[i]); } } }; test(arr);
12-5高阶函数
在本小结中,我们将向大家介绍J avaScript中函数的高阶用法。
12-5-1高阶函数介绍
高阶函数(higher-order-function)指的是操作函数的函数,一般有以下两种情况:
・函数可以作为参数被传递
・函数可以作为返回值输出
JavaScript中的函数显然满足高阶函数的条件,在实际开发中,无论是将函数当作参数传递,还 是让函数的执行结果返回另外一个函数,这两种情形都有很多应用场景。下面将对这两种情况进 行详细介绍
12-5-2参数传递
把函数当作参数传递,代表可以抽离出一部分容易变化的业务逻辑,把这部分业务逻辑放在函数 参数中,这样一来可以分离业务代码中变化与不变的部分。其中一个常见的应用场景就是回调函 数。
1.回调函数
前面无论是在介绍函数基础的时候,还是在介绍异步编程的时候,我们都有接触过回调函数。回 调函数,就是典型的将函数作为参数来进行传递。
在Ajax异步请求的应用中,回调函数的使用非常频繁。想在Ajax请求返回之后做一些事情,但又 并不知道请求返回的确切时间时,最常见的方案就是把回调函数当作参数传入发起Ajax请求的方 法中,待请求完成之后执行回调函数。俄们将在14章详细介绍Ajax技术)
示例代码如下:
let getUserInfo = function (userId, callback) { $.ajax('http://xx.com/getUserInfo?' + userId, function (data) { if (typeof callback === 'function') { callback(data); } }); } getUserInfo(123, function (data) { alert(data.userName); });
回调函数的应用不仅只在异步请求中,当一个函数不适合执行一些请求时,也可以把这些请求封 装成一个函数,并把它作为参数传递给另外一个函数,"委托"给另外一个函数来执行。比如,想 在页面中创建100个div节点,然后把这些div节点都设置为隐藏。下面是一种编写代码的方式:
let appendDiv = function () { for (var i = 0; i < 100; i++){ var div = document.createElement('div'); div.innerHTML = i; document.body.appendChild(div); div.style.display = 'none'; } }; appendDiv();
把div.style.display = 'none'的逻辑硬编码在appendDiv里显然是不合理
的,appendDiv未免有点个性化,成为了一个难以复用的函数,并不是每个人创建了节点之后 就希望它们立刻被隐藏,于是把div.style.display = 'none'这行代码抽出来,用回调函数 的形式传入appendDiv()方法
let appendDiv = function (callback) { for ( let i = 0; i < 100; i++){ let div = document.createElement('div'); div.innerHTML = i; document.body.appendChild(div); if (typeof callback === 'function'){ callback(div); } } }; appendDiv(function (node) { node.style.display = 'none'; });
可以看到,隐藏节点的请求实际上是由客户发起的,但是客户并不知道节点什么时候会创建好, 于是把隐藏节点的逻辑放在回调函数中,"委托"给appendDiv()方法。appendDiv()方法当然 知道节点什么时候创建好,所以在节点创建好的时候,appendDiv()会执行之前客户传入的回 调函数。
2.数组排序
前面在介绍数组排序时有介绍过sor t()方法,该方法就接收一个函数作为参数。sort()方法 封装了数组元素的排序方法。从sor t()方法的使用可以看到,我们的目的是对数组进行排序, 这是不变的部分;而使用什么规则去排序,则是可变的部分。把可变的部分封装在函数参数里, 动态传入sor t()方法,使sor t()方法方法成为了一个非常灵活的方法。我们这里来复习一 下:
//从小到大排列,输出:[1, 3, 4 ]
[1, 4, 3].sort(function (a, b) { return a - b; }); //从大到小排列,输出:[4, 3, 1 ] [1, 4, 3].sort(function (a, b) { return b - a; });
除了这个sort()方法以外,还有诸如for Each() , map() , eve ry() , some()等函数,也 是常见的回调函数。这些函数在前面都已经介绍过了,这里不再花篇幅进行介绍。
12-5-3返回值输出
相比把函数当作参数传递,函数当作返回值输出的应用场景也许更多。让函数继续返回一个可执 行的函数,意味着运算过程是可延续的。
1.判断数据的类型
我们来看下面的例子,判断一个数据是否为数组。在以往的实现中,可以判断这个数据有没 有length属性,有没有sort方法或者slice方法等。但是更好的方法是使
用 Object,prototype.toString 来计算。Object.prototype.toString.call(obj)返回一^个 字符串,比如 Object.p rototype.toSt ri ng.call([1,2,3])总是返回"[object Array]", 而 Object.prototype.toString.call("str")总是返回"[object String]"。下面是使 用Object,prototype.toString.call()方法来判断数据类型的一系列的isType函数。
let isString = function (obj) { return Object.prototype.toString.call(obj) === '[object String]'; }; let isArray = function (obj) { return Object.prototype.toString.call(obj) === '[object Array]'; }; let isNumber = function (obj) { return Object.prototype.toString.call(obj) === '[object Number]'; };
我们发现,实际上这些函数的大部分实现都是相同的,不同的只
是Object.p rototype.toSt ring.call(obj)返回的字符串。为了避免多余的代码,我们尝试把 这些字符串作为参数提前传入isType函数。代码如下:
let isType = function (type) { return function (obj) { return Object.prototype.toString.call(obj) === '[object ' + type + ]'; } }; let isString = isType('String'); let isArray = isType('Array'); let isNumber = isType('Number'); console.log(isArray([1, 2,引));// 输出:true
当然,还可以用循环语句,来批量注册这些isType函数:
let Type = {}; for (let i = 0, type;type = ['String', 'Array', 'Number'][i++];){ ( function (type) { Type['is' + type] = function (obj) { return Object.prototype.toString.call(obj) === '[object ' + type + ]'; } })(type) } console.log(Type.isArray([])); // 输出:true console.log(Type.isString("str")); // 输出:true
2. getSingle
下面的例子是一个单例模式的例子。
|注:单例模式的定义是:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
<body> <script> let getSingle = function(fn){ let ret; return function(){ return ret || (ret = fn.apply(this.arguments)); } } let createDiv = getSingle(function(){ return document.createElement('div'); }); let div1 = createDiv(); let div2 = createDiv(); console.log(div1 === div2); // true </script> </body>
在这个高阶函数的例子中,既把函数当作参数传递,又让函数执行后返回了另一个函数。
12-5-4面向切面编程
AOP(面向切面编程)的主要作用是把一些跟核心业务逻辑模块无关的功能抽离出来,这些跟业务 逻辑无关的功能通常包括日志统计、安全控制、异常处理等。把这些功能抽离出来之后,再通 过"动态织入"的方式掺入业务逻辑模块中。这样做的好处首先是可以保持业务逻辑模块的纯净和 高内聚性,其次是可以很方便地复用日志统计等功能模块
在Java语言中,可以通过反射和动态代理机制来实现AOP技术。而在JavaScript这种动态语言 中,AOP的实现更加简单,这是JavaScript与生俱来的能力。通常,在JavaScript中实现AOP, 都是指把一个函数"动态织入"到另外一个函数之中。下面通过扩展Function.p rototype来实 现,示例如下:
Function.prototype.before = function (beforefn) { let _self = this; //保存原函数的引用 return function () { //返回包含了原函数和新函数的"代理"函数 beforefn.apply(this, arguments); // 先执行新函数,修正this return _self.apply(this,arguments); // 再执行原函数 } }; Function.prototype.after = function (afterfn) { let _self = this; return function () { let ret = _self.apply(this, ar guments); //先执行原函数 afte rfn.apply(this, ar guments); //再执行新函数return ret; } }; let func = function () { console.log(2); }; func = func.before(function () { console.log(1); }).after(function () { console.log(3); }); func(); // 1 // 2 // 3
把负责打印数字1和打印数字3的两个函数通过AOP的方式动态植入func()函数。通过执行上面 的代码,控制台顺利地返回了执行结果1、2、3。