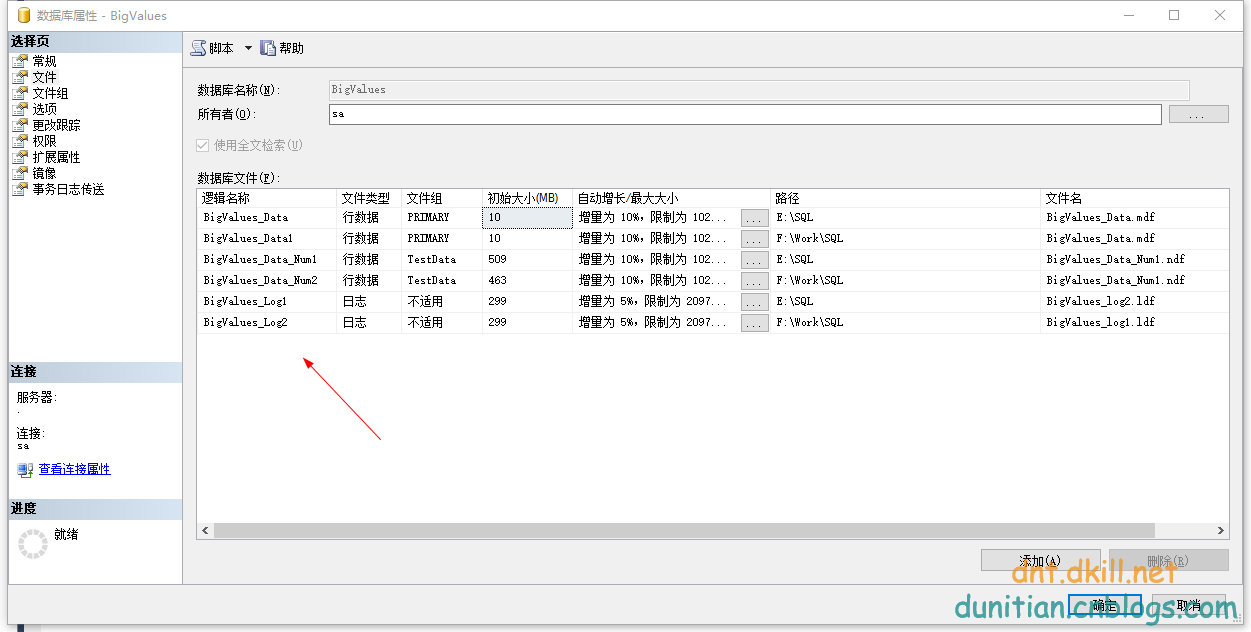
前天有学弟问逆天:“逆天,有没有一种方式可以让我一个表存到两个数据库文件中,或者说怎么把一个表的数据平摊到其他数据库文件中?”
(⊙o⊙)…,逆天数据库优化不是很强悍,不过类似的情景倒是见过,可以给你一个思路。比如说我们在创建数据库的时候就可以好好利用文件组。
举个例子:
我们一般创建数据库都是这么来的:

create database BigValues
on primary --数据库文件,主文件组
(
name='BigValues_Data', --逻辑名
size=10mb, --初始大小
filegrowth=10%, --文件增长
maxsize=1024mb, --最大值
filename=N'E:SQLBigValues_Data.mdf'--存放路径(包含文件后缀名)
)
log on --日记
(
name='BigValues_Log',
size=5mb,
filegrowth=5%,
filename=N'E:SQLBigValues_log.ldf'
)

利用文件组就可以这么创建
--创建数据库
create database BigValues
on primary --数据库文件,主文件组
(
name='BigValues_Data', --逻辑名
size=10mb, --初始大小
filegrowth=10%, --文件增长
maxsize=1024mb, --最大值
filename=N'E:SQLBigValues_Data.mdf'--存放路径(包含文件后缀名)
),
(
name='BigValues_Data1',
size=10mb,
filegrowth=10%,
maxsize=1024mb,
filename=N'F:WorkSQLBigValues_Data1.mdf'
),
filegroup TestData --TestData文件组(表创建到不同的文件组里面可以分担压力)
(
name='BigValues_Data_Num1',
size=10mb,
filegrowth=10%,
maxsize=1024mb,
filename=N'E:SQLBigValues_Data_Num1.ndf'
),
(
name='BigValues_Data_Num2',
size=10mb,
filegrowth=10%,
maxsize=1024mb,
filename=N'F:WorkSQLBigValues_Data_Num2.ndf'
)
log on --日记
(
name='BigValues_Log1',
size=5mb,
filegrowth=5%,
filename=N'E:SQLBigValues_log1.ldf'
),
(
name='BigValues_Log2',
size=5mb,
filegrowth=5%,
filename=N'F:WorkSQLBigValues_log2.ldf'
)
go
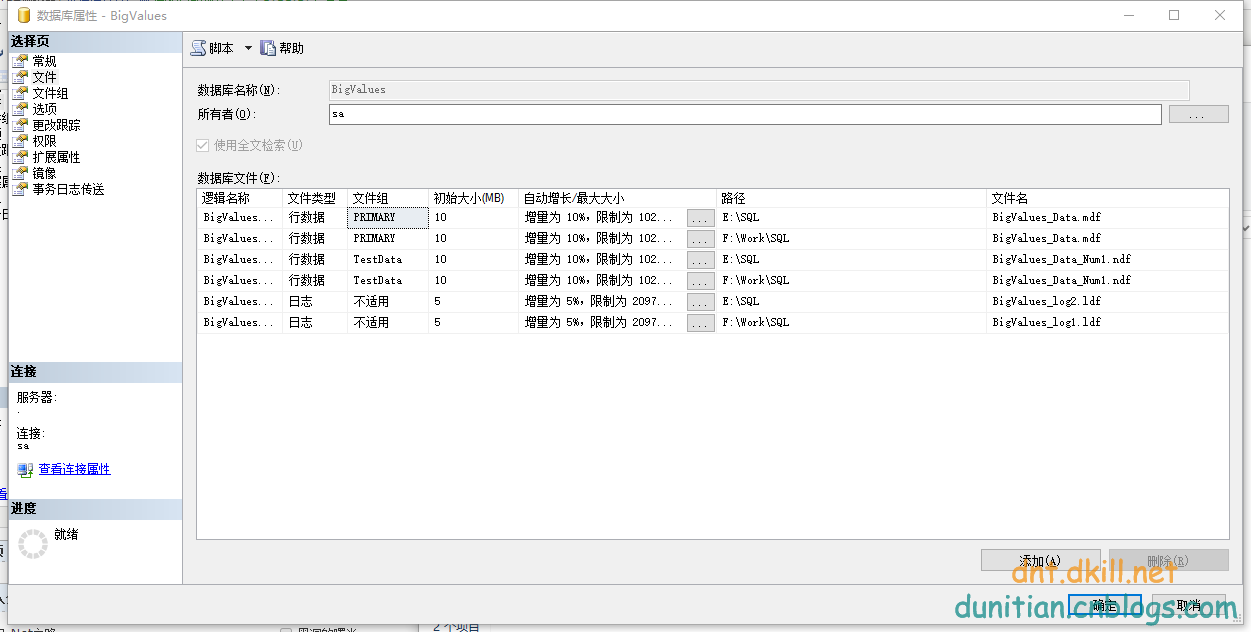
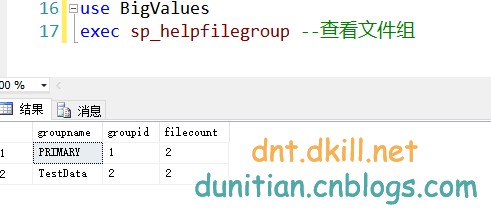
我们要是想查看文件组的信息就可以执行这个存储过程:(跟上图一起看)
exec sp_helpfilegroup --查看文件组
学弟的疑问就来了,为啥我创建表的时候都是在主文件组里呢?
那么想在指定文件组里创建表怎么搞呢?
看案例:(创建表的时候在最后写上 on 文件组名)
--在指定文件组中创建文件
create table Test
(
Tid int primary key identity,
Title01 nvarchar(100) default('标题01'),
Title02 nvarchar(100) default('标题02'),
Title03 nvarchar(100) default('标题03'),
DataStatus tinyint default(0) --0~255 size:1字节
) on TestData
我们插点数据看看吧:
 View Code
View Code有没有发现什么?数据平坦了哇(可以想象,如果平摊到多个文件各个盘,那么你的写入或者读写数据的效率是多么的高了~)