VSCode小说插件ReadNovel根据内容查找页码
写在前面
-
环境
-
平平无奇的vscode
-
插件ReadNovel(暗示)
-
-
问题
- 我用手机看了好多章了,然后要用vscode这个看
- 如何在vscode续上呢?(即从当前 章节/段落 继续看)
-
目标:
-
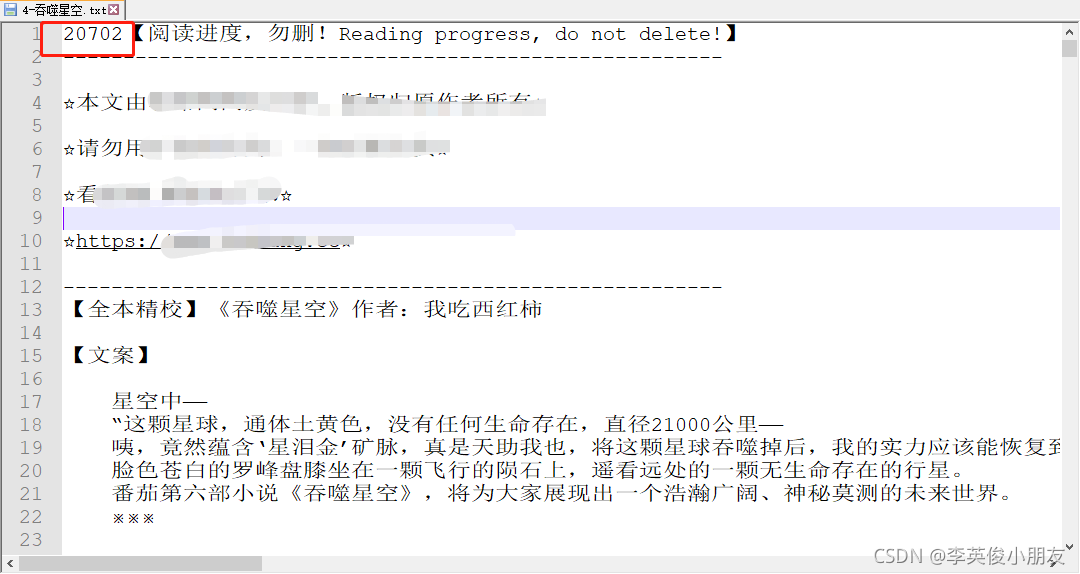
输入当前章节的关键字,查找到对应的 页码 (注意这个页码是ReadNovel在小说文件上对应的页码, 不是对应的行数)
-
进一步说明:
- 这个页码用于保存你看到的位置,实际上插件的作者在对小说文本进行处理的时候,在小说文件的开头新增了好几行文本
- 其次,在读取处理的时候,对空行进行了处理,所以上述页码的数值并不是完全对应文档的总行数,而是去掉空行的文本总行数,再减去开头新增的这些行
-
解决方案
-
使用步骤:
- 启动脚本,输入关键词,查找目标页码
page - 打开小说,修改第一行的页码为
page,保存小说 - 启动vscode,启动ReadNovel
- 开始
- 启动脚本,输入关键词,查找目标页码
-
脚本如下,需要注意的是,我这里是读取了vscode的配置文件,所以写的比较复杂,你自己用的话,直接把小说的路径 赋给
book_path就ok了""" 对vscode插件:ReadNovel提供内容查找和页码定位的操作 """ # -----------------【可以删除】--------------------- # 这里是获取vscode配置文件json,读取成dict的过程 import sys sys.path.append("constants folder") from constants import get_vscode_json_dict vscode_json_dict = get_vscode_json_dict() # -------------------------------------------------- import os from dataclasses import dataclass # 可以直接把文件路径粘到这里就行,不需要像我这样从vscode的配置文件中 book_path = vscode_json_dict.get("ReadNovel.filePath") book_name = os.path.split(book_path)[-1] @dataclass class LocationReadNovel: def __post_init__(self): self.lines_without_blank = self.read_aim_file() def read_aim_file(self): with open(book_path, 'r', encoding='utf-8') as f: lines = f.readlines() return [x for x in lines if len(x.strip()) > 0] def find_page(self, words): index = 0 infos = [] for l in self.lines_without_blank: if words in l: infos.append((index, l)) index += 1 # 展示 for i, info in infos: print(i, ': ', info) def main(): lrn = LocationReadNovel() print('当前书名:', book_name) while True: find_words = input("请输入检索内容:(输入q退出)\n\r") if find_words.strip() == 'q': break lrn.find_page(find_words) if __name__ == '__main__': main() -
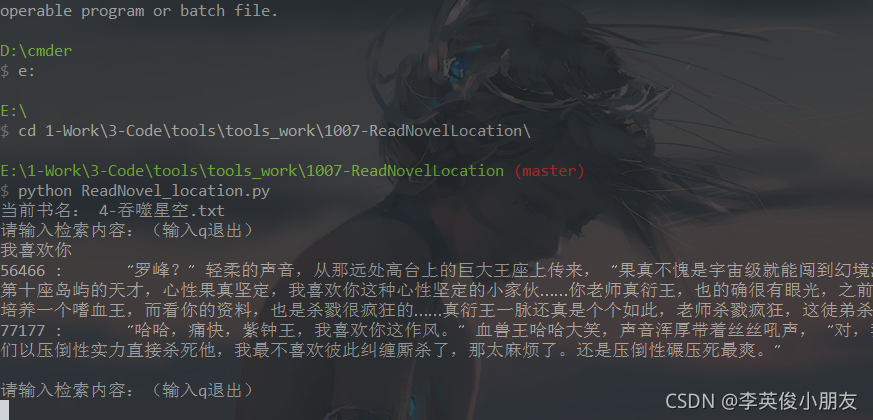
最后展示一下效果:
- ☁️ 我的CSDN:https://blog.csdn.net/qq_21579045
- ❄️ 我的博客园:https://www.cnblogs.com/lyjun/
- ☀️ 我的Github:https://github.com/TinyHandsome
- 我的bilibili:https://space.bilibili.com/8182822
- 粉丝交流群:1060163543,神秘暗号:为干饭而来
碌碌谋生,谋其所爱。 @李英俊小朋友