参考书
《TensorFlow:实战Google深度学习框架》(第2版)
两个计算交叉熵函数的区别:tf.nn.softmax_cross_entrypy_with_logits和tf.nn.sparse_softmax_cross_entrypy_with_logits
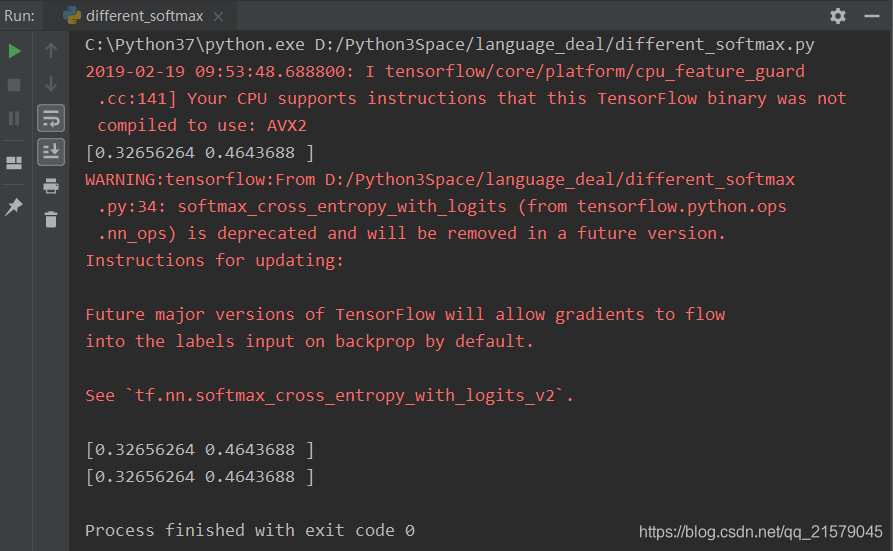
#!/usr/bin/env python # -*- coding: UTF-8 -*- # coding=utf-8 """ @author: Li Tian @contact: 694317828@qq.com @software: pycharm @file: different_softmax.py @time: 2019/2/19 9:30 @desc: 两个计算交叉熵函数的区别:tf.nn.softmax_cross_entrypy_with_logits和tf.nn.sparse_softmax_cross_entrypy_with_logits """ import tensorflow as tf # 假设词汇表的大小为3,语料包含两个单词“2 0” word_labels = tf.constant([2, 0]) # 假设模型对两个单词预测时,产生的logit分别是[2.0, -1.0, 3.0]和[1.0, 0.0, -0.5] # 注意这里的logit不是概率,因此它们不是0.0~1.0范围之间的数字。如果需要计算概率, # 则需要调用prob=tf.nn.softmax(logits)。但这里计算交叉熵的函数直接输入logits即可 predict_logits = tf.constant([[2.0, -1.0, 3.0], [1.0, 0.0, -0.5]]) # 使用sparse_softmax_cross_entropy_with_logits计算交叉熵 loss = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=word_labels, logits=predict_logits) # 运行程序,计算loss的结果是[0.32656264, 0.46436879],这对应两个预测的perplexity损失。 sess = tf.Session() x = sess.run(loss) print(x) # softmax_cross_entropy_with_logits与上面的的函数相似,但是需要将预测目标以概率分布的形式给出。 word_prob_distribution = tf.constant([[0.0, 0.0, 1.0], [1.0, 0.0, 0.0]]) loss = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_distribution, logits=predict_logits) # 运行结果与上面相同 y = sess.run(loss) print(y) # 由于softmax_cross_entropy_with_logits允许提供一个概率分布,因此在使用时有更大的自由度。 # 举个例子,一种叫label smoothing的技巧是将正确数据的概率设为一个比1.0略小的值,将错误数据的概率 # 设为比0.0略大的值,这样可以避免模型与数据过拟合,在某些时候可以提高训练效果。 word_prob_smooth = tf.constant([[0.01, 0.01, 0.98], [0.98, 0.01, 0.01]]) loss = tf.nn.softmax_cross_entropy_with_logits(labels=word_prob_distribution, logits=predict_logits) z = sess.run(loss) print(z)
运行结果:
![]()