1. 前言
HashMap是基于底层叫Entry[]数组实现的一种哈希表
现在稍微深入一点,讲解HashMap里面的一个点:存取(put/get)数据的时候,Entry数组index下标的计算。
2. hashCode,hash与index的概念
a).put/get一个元素的时候,会调用该元素的hashCode方法,比如下面的自定义KeyObject类。

b).hashCode的数据会被用来计算hash值

如果细心的小伙伴,去print一下这个hash值,就会发现其实是一个非常大的整数,比如2028737这样的,显然这个hash值不会是底层Entry[]数组的index值。
所以总结一下:
- hashCode:HashMap的Key对象里面的方法hashCode产生的值
- hash:通过hashCode的值,通过一定算法产生的hash值
- index:通过hash值计算产生的,HashMap底层数组Entry[]的偏移值那计算index的方法是什么呢?
3 index的计算原则
Entry[]数组的长度在初始化的时候会被指定,假定这个值为length。
那index的值就从 0 ~ length-1。所以index需要尽可能的平衡,也就是分布均匀,不能某些位置上存储特别多的数据,某些位置上又特别少。
前面我们说过,通过hash值来计算index,那使用什么办法可以满足:
- 性能高效
- 均匀分析
4 index的计算方法
4.1 取模运算(方式一)
hash值为int,index需要映射到0 ~ length -1,最直观的使用取模运算,也就是:
index = hash值 % length 这个时候index的值的范围就是 0 ~ length -1
但是,Java 官方没有采用这个办法,因为这种效率不是最高的。
4.2 位运算(为什么长度一定是2的n次方)
为了解决取模效率的问题,Java官方采用了位运算的方法。
index = hash值 & (length -1)
这个时候,如果要index的值的范围也是 0 ~ length -1,需要一个前置条件:
length的长度必须是2的n次幂。当length的长度是2的n次方时,有以下的公式成立:
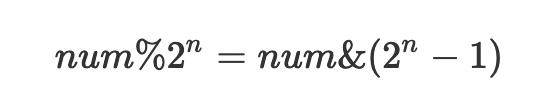
因为:一个数num除以2n,相当于右移n位,那么移出去的那些数自然就是余数了,举个例子158除以8:

4.3 取模和位运算性能比较
看到这里会有人问,为什么取模运算会比位运算慢,慢多少呢?我们来做个实验:
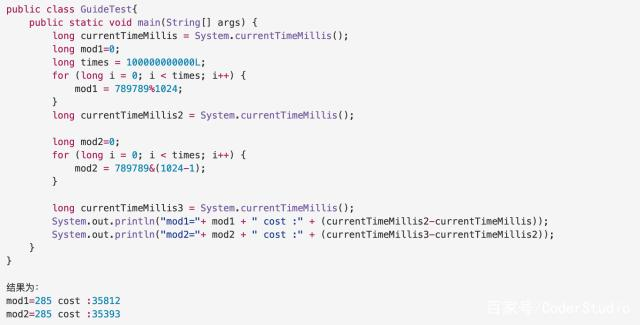
5. 要点总结(常见问题)
- 如何计算index的
- 为什么不用取模,要用位运算
- 为什么长度一定是2的n次方
摘自:https://baijiahao.baidu.com/s?id=1646023968436883100&wfr=spider&for=pc