一、normalization
1、图例

2、Kibana

二、字符过滤器
1、html过滤器

2、字符过滤器
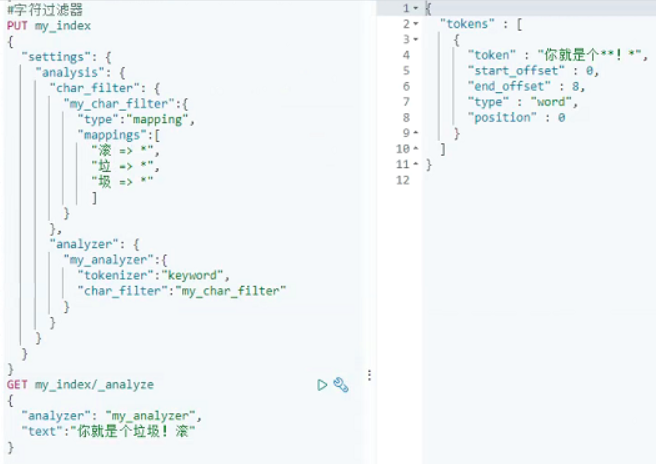
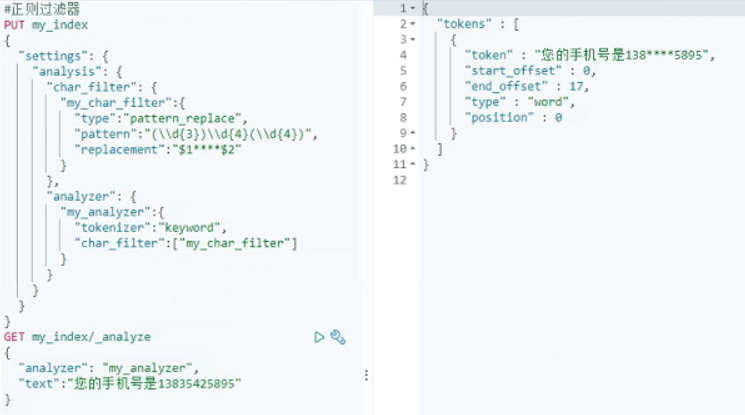
3、正则过滤器
三、令牌过滤器
1、同义词
文本指定同义词替换
1 PUT /test_index 2 { 3 "settings": { 4 "analysis": { 5 "filter": { 6 "my_synonym":{ 7 "type":"synonym_graph", 8 "synonyms_path":"analysis/synonym.txt" 此处为自定义近义词文本 9 } 10 }, 11 "analyzer": { 12 "my_analyzer":{ 13 "tokenizer":"ik_max_word", 14 "filter":["my_synonym"] 15 } 16 } 17 } 18 } 19 } 20 GET test_index/_analyze 21 { 22 "analyzer": "my_analyzer", 23 "text":["大G,霸道,daG"] 24 }

代码中自定义同义词
1 PUT /test_index 2 { 3 "settings": { 4 "analysis": { 5 "filter": { 6 "my_synonym":{ 7 "type":"synonym", 8 "synonyms":["赵,钱,孙,李=>吴","周=>王"] 9 } 10 }, 11 "analyzer": { 12 "my_analyzer":{ 13 "tokenizer":"standard", 14 "filter":["my_synonym"] 15 } 16 } 17 } 18 } 19 } 20 GET test_index/_analyze 21 { 22 "analyzer": "my_analyzer", 23 "text":["赵,钱,孙,李","周"] 24 }
2、大小写
1 GET test_index/_analyze 2 { 3 "tokenizer": "standard", 4 "filter": ["lowercase"], 5 "text":["ASADASD FDF GFDD ASDASDQW"] 6 } 7 GET test_index/_analyze 8 { 9 "tokenizer": "standard", 10 "filter": ["uppercase"], 11 "text":["sadasd fdsfsg xzczxcxzc"] 12 }
3、停用词
1 PUT /test_index 2 { 3 "settings": { 4 "analysis": { 5 "analyzer": { 6 "my_analyzer": { 7 "type": "standard", 8 "stopwords":["me"] 将指定的词语在结果中不展示 9 } 10 } 11 } 12 } 13 } 14 GET test_index/_analyze 15 { 16 "analyzer": "my_analyzer", 17 "text":["Teacher me and you in the china"] 18 }
四、自定义分词器
1 PUT custom_analysis 2 { 3 "settings":{ 4 "analysis":{ 5 "char_filter": { 6 "my_char_filter":{ 7 "type":"mapping", 8 "mappings":["& ==> and","| => or"] 9 }, 10 "html_strip_char_filter":{ 11 "type":"html_strip", 12 "escaped_tags":["a"] 13 } 14 }, 15 "filter": { 16 "my_stopword":{ 17 "type":"stop", 18 "stopwords":["is","in","the","a","at","for"] 19 } 20 }, 21 "tokenizer": { 22 "my_tokenizer":{ 23 "type":"pattern", 24 "pattern":"[ ,.!?]" 25 } 26 }, 27 "analyzer": { 28 "my_analyzer":{ 29 "type":"custom", type为custom使得es辨认出为自定义分词器 30 "char_filter":["my_char_filter","html_strip_char_filter"], 31 "filter":["my_stopword","lowercase"], 32 "tokenizer":"my_tokenizer" 33 } 34 } 35 } 36 } 37 } 38 GET custom_analysis/_analyze 39 { 40 "analyzer":"my_analyzer", 41 "text":["What is ,<a>as.df</a> . ss<p> in ? &</p> | is ! in the a at for"] 42 }
五、中文分词器
pluginsikconfig目录下文件描述:
自定义ik分词器词库:在IKAnalyzer.cfg.xml文件中添加新增文件

六、热更新
由来:ik分词器在词库中添加词汇后必须重启才会生效,但是生产环境如果频繁重启会出问题,这时就需要热更新
有了热更新,当我们在频繁扩展ik分词器后就不需要频繁重启es
1、基于远程词库文件
请求url:localhost:9200/api/hotWord?wordlib=(等于1时为新增ik词库,等于2时为停用词)
代码:先在application.yml文件中配置端口号

2、基于数据库
需要修改ik分词器源码