redis本身是开源的C语言编写的k-v存储系统,他支持String、List、Set、ZSet、hash五种数据结构,每种数据结构底层是如何实现的?其数据结构为什么?
1. String
1.1 结论
底层结构:指针+字符数组
时间复杂度:O(1)
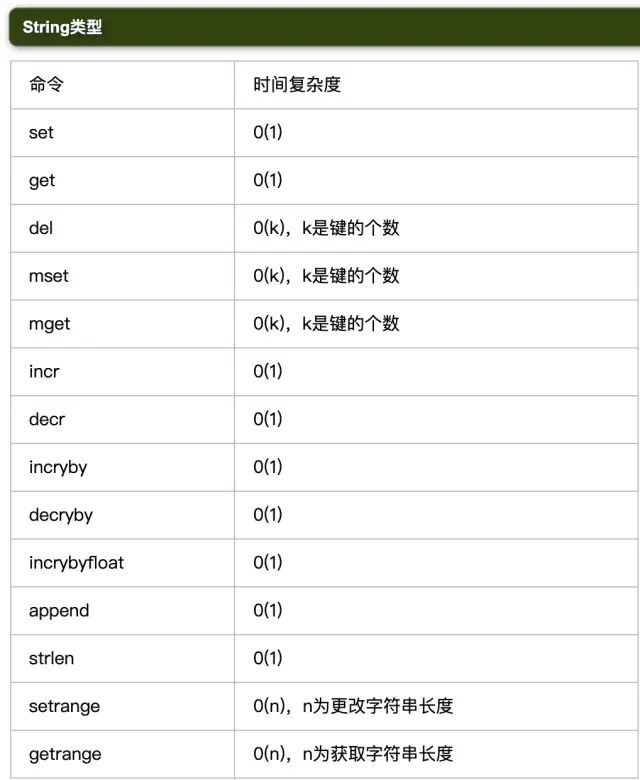
1.2 表格
1.3 底层原理
Redis是C语言开发的,但在C语言中并没有字符串类型,只能使用指针和字符数组的形式来保存一个字符串。所以Redis设计了一个简单的动态字符串(SDS [Simple Dynamic String])来作为底层实现。
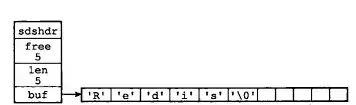
struct sdshdr{
//记录buf数组中已使用的字节的长度
int len;
//记录buf数组中剩余空间的长度
int free;
//字节数组,用于存储字符串
char buf[];
}
获取字符串长度的时间复杂的为O(1),因为len保存的是当前字符串长度。
SDS会自动进行扩容,SDS拼接之后,若此时len小于1MB,则会多分配与len相同的未使用空间,使用free表示;若ken大于1MB,则会多分配1MB空间。
惰性释放,当字符串进行缩短之后,程序不会立即回收空间,而是记录在free中,以便后序拼接的使用。
2. LIST
2.1 结论
底层结构:双向链表
时间复杂度:查询效率为O(n)。但是访问两端元素的时间复杂度O(1)
lRange时间复杂度O(n);lpop时间复杂度O(1);lpush key value1 value2 value3... valueN从list的左边添加一个或者多个元素 时间复杂度O(1~n);
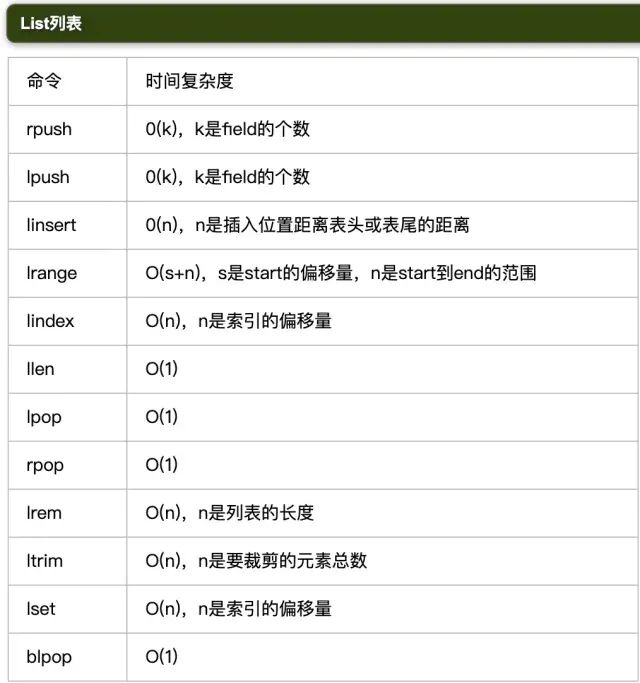
2.2 表格
2.3 底层原理
底层结构:quicklist
一个链表结构可以有序的存储多个字符串,拥有例如:lpush、lpop、rush、rpop等操作。在3.2版本之前,列表使用ziplist和linkedlist来实现。而在3.2版本之后,重新引入了一个quicklist的数据结构,列表的底层是由quicklist实现的,它结合了ziplist和linkedlist的优点。按照原文的解释是:【A doubly linked list of ziplist】。存。
在老版本中,当列表对象同时满足一下两个条件时,列表将使用ziplist编码:
列表对象保存的所有字符串元素长度都小于64字节;
列表对象保存的元素数量小于512个;
当有一个条件不满足时将进行一次转码,使用linkedlist。
ziplist
ziplist是一个经过特殊编码的双向链表,它设计的目的是为了提高存储的效率。一个普通的双向链表,链表中每一项都占用独立的一块内存,各项之间用地址指针(或引用)连接起来,但是这种方式会造成大量的内存碎片,而且地址指针也会占用额外的内存。
ziplist却是将表中每一项存放在前后连续的地址空间内,一个ziplist整体占用一大块内存。它是一个表(list),但其实不是一个链表(linked list)
ziplist作用:节省内存;
ziplist特点:数据存放在前后连续的地址空间内;
linkedlist
双向列表,插入和删除的效率高,但是查询的效率确实O(n)
quicklist
【A doubly linked list of ziplist】ziplist组成的双向链表。它宏观上就是一个链表结构,只不过每一个节点都是以ziplist来存储数据,而ziplist中又包含多个entry。也可以说quicklist节点保存的是一片数据
整体上quicklist是一个双向链表结构,和普通的链表操作一样,它的插入删除效率高,但是查询效率确实O(n),不过,这样链表访问两端的元素的时间复杂度都是O(1),故对list操作多数都是poll和push。
每个quicklist节点就是一个ziplist,具有压缩列表的特性。
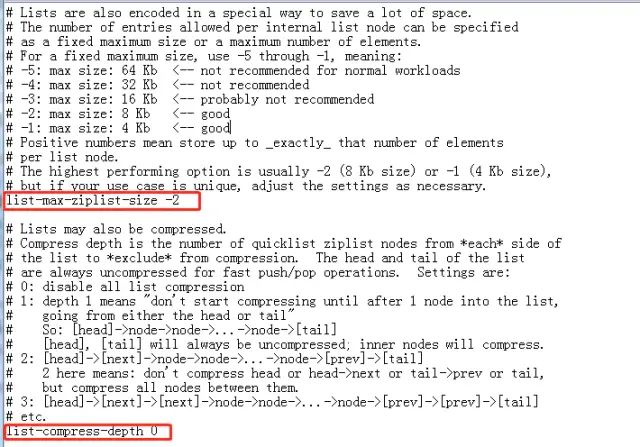
在redis.conf配置文件中,有两个参数可以优化:
list-max-ziplist-size表示每个quicklist节点的字节大小,默认为-2,表示8kb。
list-compress-depth:表示quicklist节点是否要压缩,0表示永不压缩。
3.HASH
3.1 结论
底层结构:ziplist或者hashtable
时间复杂度:O(1)
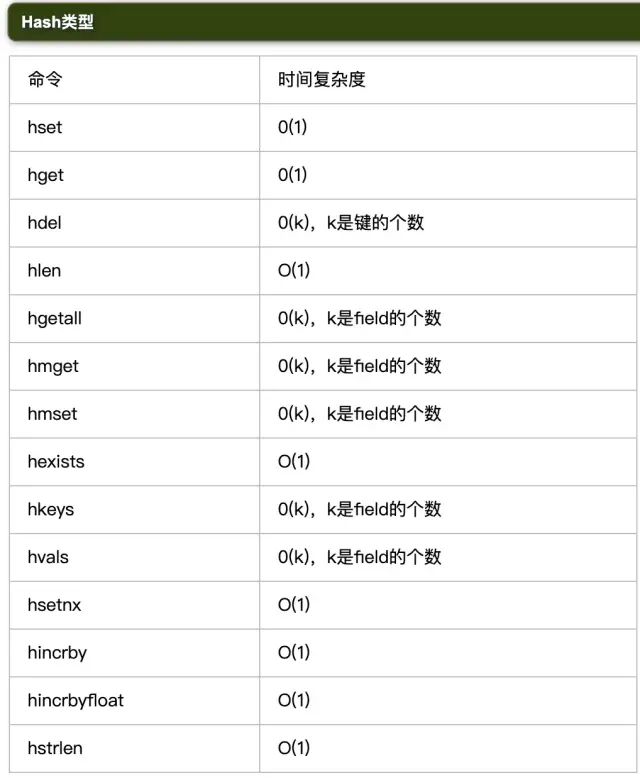
3.2 表格
3.3 原理
redis的散列可以存储多个键值对之间的映射。hash底层的数据结构实现其实有两种:
一种是ziplist(将键与值都压入链表中),当存储的数据超过配置的阈值时就会转化为hashtable结构,这种转换比较耗费时间,我们应该尽量避免这种转化操作,同时满足一下两个条件时才会使用这种结构:
当键的个数小于hash-max-ziplist-entries(默认512)
当所有值都小于hash-max-ziplist-value (默认64)
另一种就是hashtable,这种结构的时间复杂度为O(1),但是会消耗比较多的内存空间。
4. SET
4.1 结论
底层结构:整数集合(intset)或者字典(hashtable)
时间复杂度:O(1)
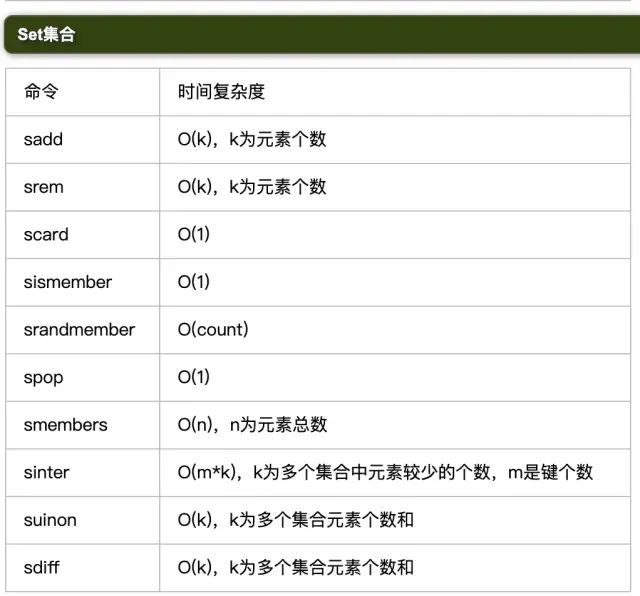
4.2 表格
4.3 原理
typedef struct intset{
//编码方式
uint32_t encoding;
//元素数量
uint32_t length;
//存储元素的数组
int8_t contents[];
}公众号:码农编程进阶笔记整数集合中的每个元素都是contents数组的一个数组项,各个项在数组中按值的大小进行有序排列,并且不包含重复的项。contents数组中的元素类型由encoding决定,没当加入新元素时,如果元素的编码大于contents数组元素的编码,则数组元素会整体升级,注意不会发生降级。公众号:码农编程进阶笔记
5. ZSET
底层结构:ziplist或者skiplist(跳表)
时间复杂度:O(log(n))
5.1 什么是跳表
力扣——1206. 设计跳表
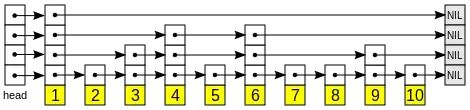
跳表设计思路和链表相似,跳表中有很多层,每一层是一个短的链表。在第一层的作用下,增删查的时间复杂度不超过O(n)。跳表的每一个操作平均时间复杂度为 O(log(n)),空间复杂度是 O(n)。
跳跃表是一种有序的数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。跳表的期望空间复杂度为O(n)O(n),跳表的查询,插入和删除操作的期望时间复杂度都为O(logn)O(logn)。
Redis内部数据结构详解之跳跃表(skiplist)
跳表是一种随机化数据结构,基于并联的链表。
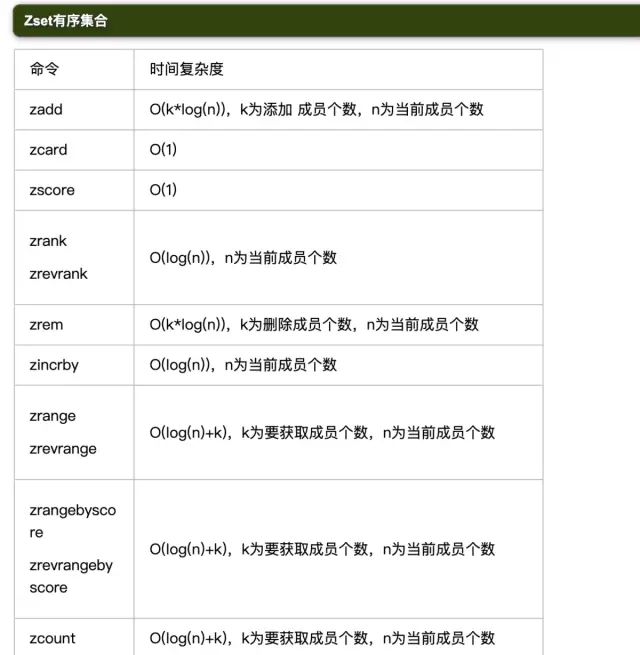
5.2 常用命令时间复杂度