1、词汇表征:
one-hot表征、词嵌入
2、学习词嵌入
word2vec:Word2vec算法是一种简单的计算更加高效的方式来实现对词嵌入的学习
Skip-gram:所做的是在语料库中选定某个词(Context),随后在该词的正负10个词距内取一些目标词(Target)与之配对,构造一个用Context预测输出为target的监督学习问题,训练一个如下图结构的网络:
o(c) -> E -> e(c) -> O(softmax) -> y_
softmax:输出context下target出现的条件概率:
p(t|c) = exp(θte(c))/∑exp()
Word2vec中还有一种CBOW模型,它的工作方式是采样上下文中的词来预测中间的词,与Skip-gram相反
负采样模型中构造了一个预测给定的单词是否为一对Context-target的新监督学习问题,网络结构可以是skip-gram或者cbow
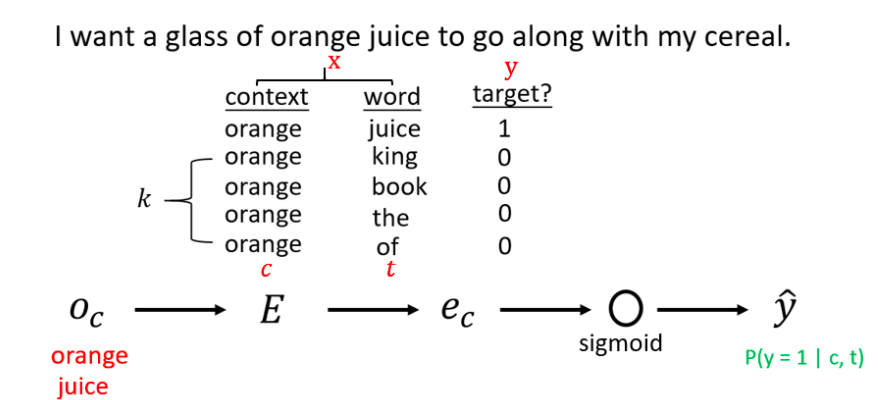
训练过程中,从预料库中选定Context,输入的词为一对Context-Target,则标签设置为1。另外任取k对非Context-Target,作为负样本,标签设置为0.只有较少的数据,k的取值5~20的话,能达到比较好的效果;拥有大量的训练数据,k的取值取2~5较为合适。原网络中的softmax变成多个Sigmoid单元,输出Context-Target(c,t)对为正样本(y=1)的概率

模型中一般采用以下公式来计算选择某个词作为负样本的概率:

其中 代表语料库中单词wi的出现的频率
代表语料库中单词wi的出现的频率
softmax:
将n维实值向量转化为取值范围在(0,1)之间的n维实值向量,且和为1,多用于表征函数,softmax(x) = softmax(x+c);