---恢复内容开始---
一,re 正则模块
二、time datetime 时间模块
三、random 模块
四、OS模块
五、sys模块
六、shutil模块
七、json&pickle模块
一,正则模块re
一:什么是正则?
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。
import re
print(re.findall('w','egon 123 = — - +')) #w 匹配字母数字下划线
打印结果:['e', 'g', 'o', 'n', '1', '2', '3']
正则常用操作
# Author:land
#print(re.findall('w','egon 123 + _ - +')) #w 匹配字母数字下划线
#?: 代表?号左边的字符出现0次或者1次
#*: 代表*号左边的字符出现0次或者无穷次
#+: 代表+号左边的字符出现1次或者无穷次
#{m,n}: 代表号左边的字符出现0次或者无穷次
#.* 贪婪匹配
#.*? 非贪婪匹配 (用这个)
#re.search() #值匹配成功一次就返回
#re.match() #从开头取
import re
# print(re.findall('w','egon 123 = — - +')) #w 匹配字母数字下划线
# print(re.findall('W','egon 123 = — - +')) #w 匹配非字母数字下划线
# print(re.findall('s','egon 123 = — - +')) #s 匹配任意空白字符
# print(re.findall('S','egon 123 = — - +')) #S
#重复. * ? + {m,n}
# . 代表匹配任意一个字符
# print(re.findall('a.b','alb a b a-b aaaaab'))
# # a.b
#
# print(re.findall('a.b','alb a
b a-b aaaaab',re.DOTALL)) #匹配出
#? ?号代表她左边的字符出现0次或者1次
# print(re.findall('ab?','ab a b a-b abbbb'))
#* *号代表她左边的字符出现0次或者无穷次
# print(re.findall('ab*','ab a b a-b aabbbbb'))
#+ +号代表她左边的字符出现1次或者无穷次
# print(re.findall('ab+','ab a b a-b aabbbbb'))
# {m,n} 代表左边的字符出现m到n次
#print(re.findall('ab{1,3}','ab a b a-b aabbbbb'))
#.* 贪婪匹配
#print(re.findall('a.*b','ab jfnj cc xxxxaayyybbbbb'))
#.*? 非贪婪匹配 常用
#print(re.findall('a.*?b','ab jfnj cc xxxxaayyybbbbb'))
#| 或者
# print(re.findall('compla(y|ies)','too girl complay and complaies'))
# print(re.findall('compla(?:y|ies)','too complay and complaies'))
# print(re.findall(r'a\c','ac alc aBc')) #r的意思是不要做语法级别的转义 #不加r会报错
# print(re.findall('a\\c','ac alc aBc')) #不加r的时候
#[] 去[]号内任意一个字符
#re模块其他方法
#re.search() 只匹配成功一次就返回
# print(re.search('a[^-+*/]b','axb azb aAb alb a-b a+b'))
# print(re.search('a[*]b','axb azb aAb alb a-b a+b')) #没结果返回none
# print(re.search('a[0-9]b','axb azb aAb a2b a-b a+b').group())
#re.split() 以冒号分割
#print(re.split(':','root:x:0:0::/root:/bin/bash'))
#re.sub() 就替换的意思
print(re.sub('root','admin','root:x::0:0:/bin/bash')) #把root替换为admin
#re.compile()
二、time 时间模块
在Python中,通常有这几种方式来表示时间:
- 时间戳(timestamp):通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
- 格式化的时间字符串(Format String)
- 结构化的时间(struct_time):struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
# Author:land
import time
#print(time.time())
#print(time.localtime()) #结构化时间
#print(time.localtime().tm_mday)
#print(time.gmtime())
print(time.strftime('%Y-%m-%d %H:%M:%S'))
import datetime print(datetime.datetime.now()) print(datetime.datetime.fromtimestamp(2222222)) print(datetime.datetime.now()+datetime.timedelta(days=3)) #3天以后的时间 print(datetime.datetime.now()+datetime.timedelta(days=-3)) #3天以前的时间 print(datetime.datetime.now()+datetime.timedelta(hours=3)) #3小时以后的时间 print(datetime.datetime.now().replace(year=1999,hour=12))
三、random 模块
# Author:land
import random
# print(random.random()) #取0-1之间的小树
# print(random.randint(1,3))
# print(random.randrange(1,3))
# print(random.choice([1,'jdu','fg']))
#
# print(random.uniform(1,3))
#随机生成字母数字验证码
def mak_code(n):
res='' #定义一个空字符串
for i in range(n):
s1=str(random.randint(0,9)) #获取一盒随机整数 然后转换成字符
s2=chr(random.randint(65,90)) #获取A-Z的大写字母
res+=random.choice([s1,s2]) #然后随机选择一个进行相加n次
return res #返回res
print(mak_code(4))
四、OS模块
os模块是与操作系统交互的一个接口
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.curdir 返回当前目录: ('.')
os.pardir 获取当前目录的父目录字符串名:('..')
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/"
os.linesep 输出当前平台使用的行终止符,win下为"
",Linux下为"
"
os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
os.system("bash command") 运行shell命令,直接显示
os.environ 获取系统环境变量
os.path.abspath(path) 返回path规范化的绝对路径
os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
五、sys模块
1 sys.argv 命令行参数List,第一个元素是程序本身路径 2 sys.exit(n) 退出程序,正常退出时exit(0) 3 sys.version 获取Python解释程序的版本信息 4 sys.maxint 最大的Int值 5 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 6 sys.platform 返回操作系统平台名称
六、shutil模块
高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length])
将文件内容拷贝到另一个文件中
1 import shutil
2
3 shutil.copyfileobj(open('old.xml','r'), open('new.xml', 'w'))
shutil.copyfile(src, dst)
拷贝文件
1 shutil.copyfile('f1.log', 'f2.log') #目标文件无需存在
shutil.copymode(src, dst)
仅拷贝权限。内容、组、用户均不变
1 shutil.copymode('f1.log', 'f2.log') #目标文件必须存在
shutil.copystat(src, dst)
仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
1 shutil.copystat('f1.log', 'f2.log') #目标文件必须存在
shutil.copy(src, dst)
拷贝文件和权限
1 import shutil
2
3 shutil.copy('f1.log', 'f2.log')
shutil.copy2(src, dst)
拷贝文件和状态信息
1 import shutil
2
3 shutil.copy2('f1.log', 'f2.log')
shutil.ignore_patterns(*patterns)
shutil.copytree(src, dst, symlinks=False, ignore=None)
递归的去拷贝文件夹
1 import shutil
2
3 shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) #目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除
七、json&pickle模块
用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
为什么要序列化?
1:持久保存状态
需知一个软件/程序的执行就在处理一系列状态的变化,在编程语言中,'状态'会以各种各样有结构的数据类型(也可简单的理解为变量)的形式被保存在内存中。
内存是无法永久保存数据的,当程序运行了一段时间,我们断电或者重启程序,内存中关于这个程序的之前一段时间的数据(有结构)都被清空了。
在断电或重启程序之前将程序当前内存中所有的数据都保存下来(保存到文件中),以便于下次程序执行能够从文件中载入之前的数据,然后继续执行,这就是序列化。
具体的来说,你玩使命召唤闯到了第13关,你保存游戏状态,关机走人,下次再玩,还能从上次的位置开始继续闯关。或如,虚拟机状态的挂起等。
2:跨平台数据交互
序列化之后,不仅可以把序列化后的内容写入磁盘,还可以通过网络传输到别的机器上,如果收发的双方约定好实用一种序列化的格式,那么便打破了平台/语言差异化带来的限制,实现了跨平台数据交互。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
如何序列化之json和pickle:
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
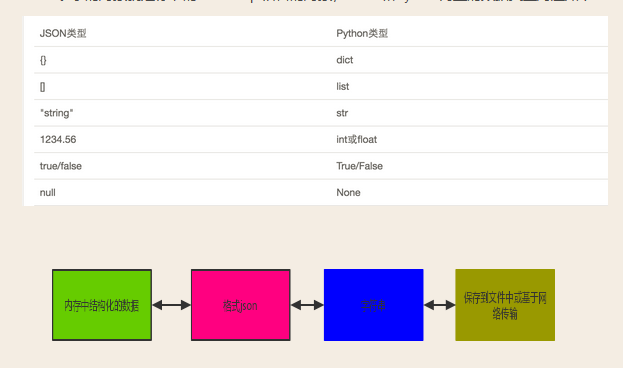
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
1 import json
2
3 dic={'name':'alvin','age':23,'sex':'male'}
4 print(type(dic))#<class 'dict'>
5
6 j=json.dumps(dic)
7 print(type(j))#<class 'str'>
8
9
10 f=open('序列化对象','w')
11 f.write(j) #-------------------等价于json.dump(dic,f)
12 f.close()
13 #-----------------------------反序列化<br>
14 import json
15 f=open('序列化对象')
16 data=json.loads(f.read())# 等价于data=json.load(f)
1 import pickle
2
3 dic={'name':'alvin','age':23,'sex':'male'}
4
5 print(type(dic))#<class 'dict'>
6
7 j=pickle.dumps(dic)
8 print(type(j))#<class 'bytes'>
9
10
11 f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
12 f.write(j) #-------------------等价于pickle.dump(dic,f)
13
14 f.close()
15 #-------------------------反序列化
16 import pickle
17 f=open('序列化对象_pickle','rb')
18
19 data=pickle.loads(f.read())# 等价于data=pickle.load(f)
20
21
22 print(data['age'])