sqoop 大概样例
sqoop import --connect jdbc:oracle:thin:@//XXXX.XXXX.XXXX.XXXX:1531/BDC --username DATAREPORT --password datareport --table NW_AGG_FLIGHT_ALL_DATE --hbase-create-table --hbase-table TEST_LAB:NW_AGG_FLIGHT_ALL_DATE --column-family CF --hbase-row-key "FLIGHT_DT,ORI_ENG,DES_ENG,CARRIER,FLIGHT_NO" --split-by flight_dt -m 4 --where " flight_dt = '2017-01-01'"
连接串servicename 用/ SID用: 用户名,表名,ROW-KEY的字段名(不含null)等用大写
相关参数说明
--connect:数据库连接串
--username:用户名
--password :密码
--P:交互式输入密码
--table:表名
-m:并行执行sqoop导入程序的map task的数量,在不指定的情况下默认启动4个map
--split-by:并行导入过程中,各个map task根据哪个字段来划分数据段,该参数最好指定一个能相对均匀划分数据的字段,比如创建时间、递增的ID
--query :使用查询语句代替--table,有where条件是必须增加 AND $CONDITIONS"
其他参数说明
--hbase-table:hbase中接收数据的表名
--hbase-create-table:如果指定的接收数据表在hbase中不存在,则新建表
--column-family:列族名称,所有源表的字段都进入该列族
--hbase-row-key:如果不指定则采用源表的key作为hbase的row key。可以指定一个字段作为row key,或者指定组合行键,当指定组合行键时,用双引号包含多个字段,各字段用逗号分隔
-D sqoop.hbase.add.row.key :是否将rowkey相关字段写入列族中,默认为false,默认情况下你将在列族中看不到任何row key中的字段。注意,该参数必须放在import之后。
--target-dir :HDFS目录路径
--hive-table :HIVE表名
具体参数参考http://sqoop.apache.org/
kettle中sqoop 应用 在job中
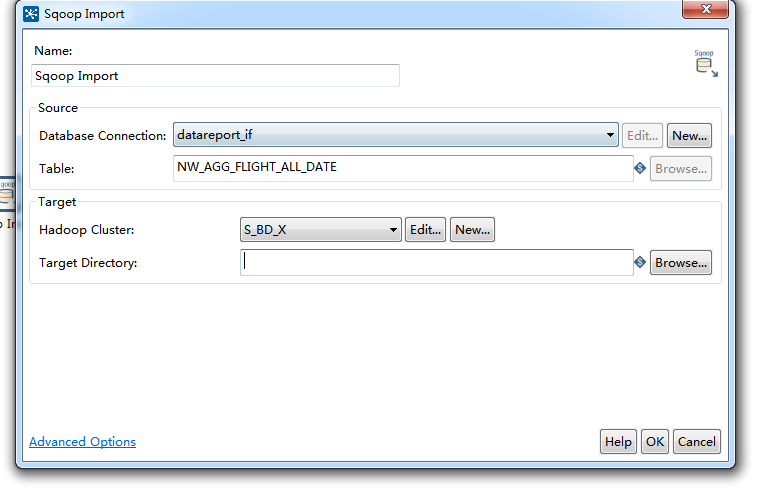
具体设置可以在Advanced Options中选择填写,能够生成相关的命令行
kettle执行 会遇到跨平台错误
需要在D:Program Fileskettle710data-integrationpluginspentaho-big-data-pluginhadoop-configurationscdh57中的mapred-site.xml里增加跨平台支持
<property>
<name>mapreduce.app-submission.cross-platform</name>
<value>true</value>
</property>