1,beautifulsoup的中文文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/
2,
from bs4 import BeautifulSoup html_doc = """ <html><head><title>The Dormouse's story</title></head> <body> <p class="title"><b>The Dormouse's story</b></p> <p class="story">Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>, <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>; and they lived at the bottom of a well.</p> <p class="story">...</p> """; soup = BeautifulSoup(html_doc); print(soup.prettify())
1)soup.prettify()的作用是把html格式化输出
2)在输出是会发出警告:No parser was explicitly specified, so I'm using the best available HTML parser for this system。这是因为没有解析器。所以需要安装解析器。如下图:
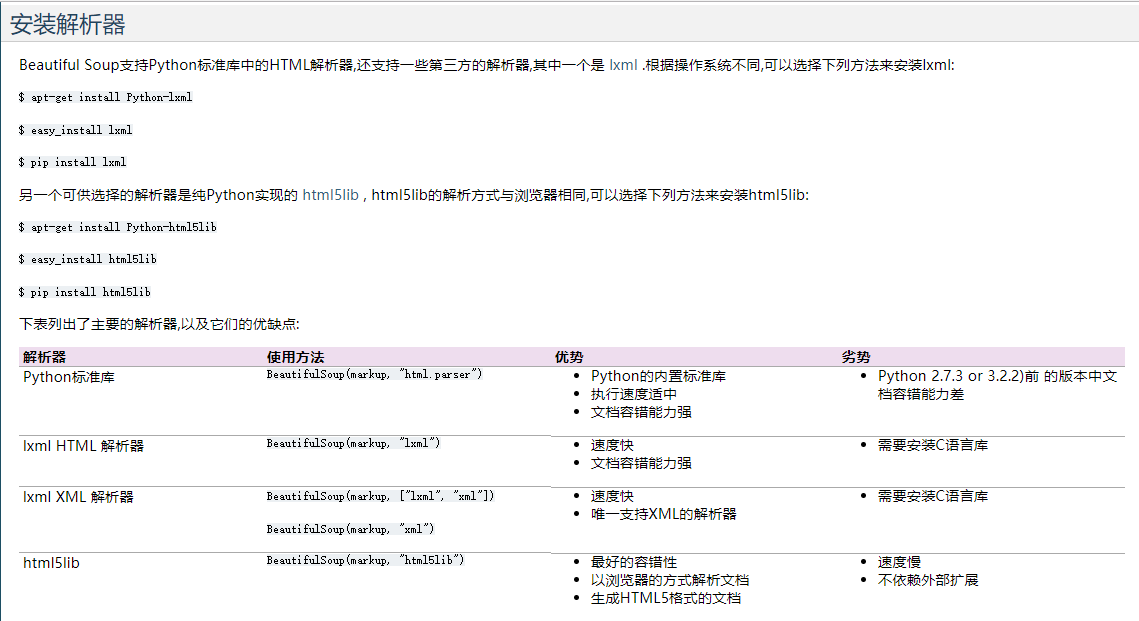
3)soup = BeautifulSoup(html_doc,"html.parser");//这个就可以加入解析器
print(soup.prettify())
4)soup.title #获取title内容<title>The Dormouse's story</title>
soup.标签名 #获取对应的标签。(系统当前第一个)
soup.find_all('a') #打印出所有‘a’标签 返回的是一个数组
soup.find(id="link3") #打印出对应id页面
for link in soup.find_all('a'): #这个用来遍历 print(link.get('id'))
#在遍历class时候返回的是一个数组
print(link.get('class'))
#['sister1']
#['sister2']
#['sister3']
soup.get_text() #这个是用来获取所有的文字
soup.find('p',{'class':'story'})) #这个里面是获取p标签下的class=story所有信息 注:这里因为class是关键字所以不能使用find('class':'story')
soup.find('p',{'class':'story'}).string) # 结果为none
5)可以通过政策表达式来 match() 来匹配内容.下面例子中找出所有以b开头的标签,这表示<body>和<b>标签都应该被找到:
import re for tag in soup.find_all(re.compile("^b")): print(tag.name)
(5.1),python的正则表达式
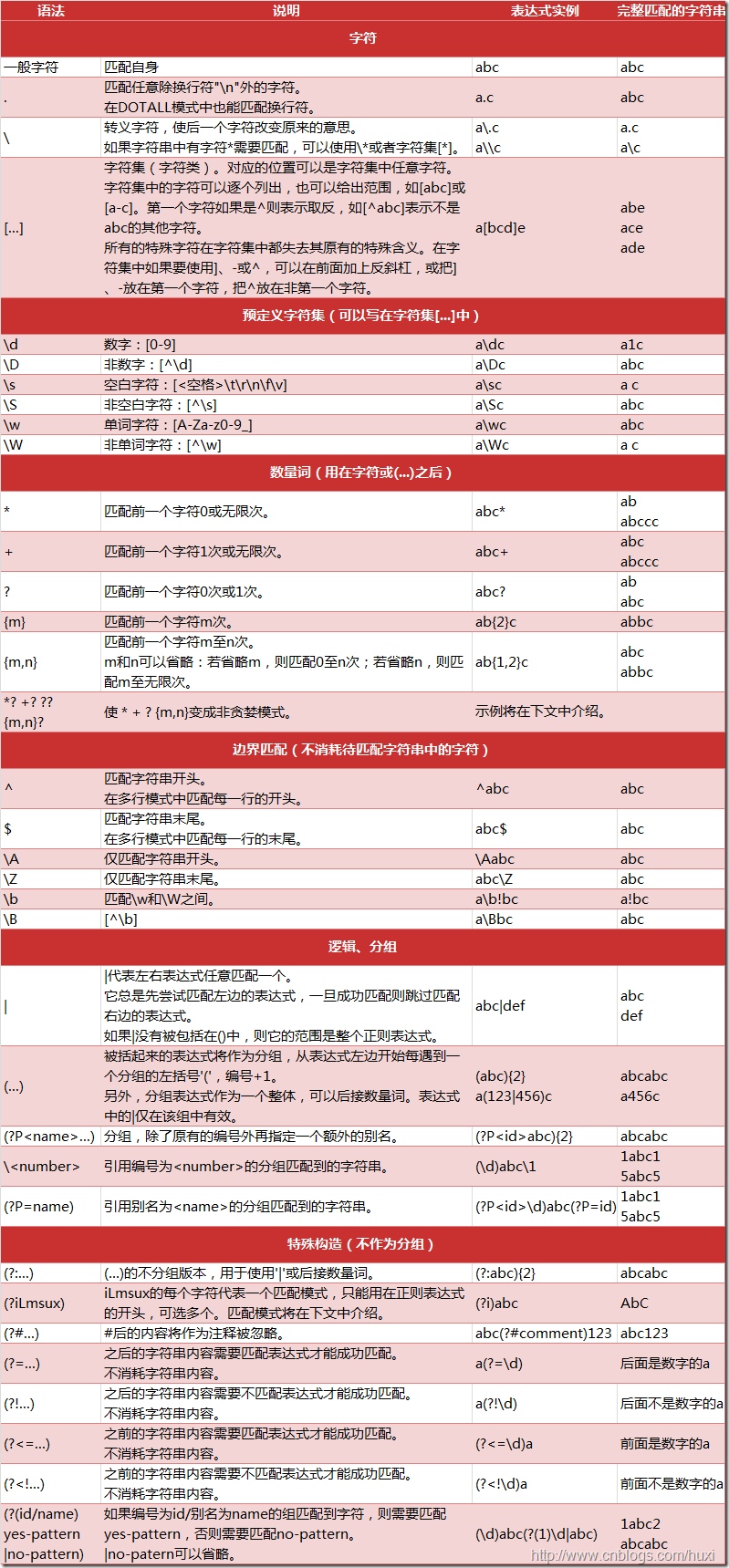
(注:图片来源https://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html)