字符流
使用的原因
1、如果读取文件中的信息是纯英文,可以一次读取一个字节
2、如果文件中的信息是纯中文的,可以一次读取三个或者两个
3、如果文件中的信息是中英文混杂,每次读取几个,不确定容易出现乱码
小知识补充:
在utf-8或者gbk的编码格式中,如果存储的是英文字符,该字符对应的字节肯定是正 数
如果存储的字符是中文字符,那么该在字符的第一个直接肯定是负数
4、如果想要写出一个字符串信息到指定文件中,可以将字符串转为字节数6组,但是比较麻烦,而且浪费内存。
概述
1、字符流:可以以字符为单位操作数据的输入和输出的对象所属的类型
2、分类:
字符输入流 Reader
字符输出流 Writer
Reader
1、字符输入流,也是一个抽象父类,不能直接创建对象
2、方法:
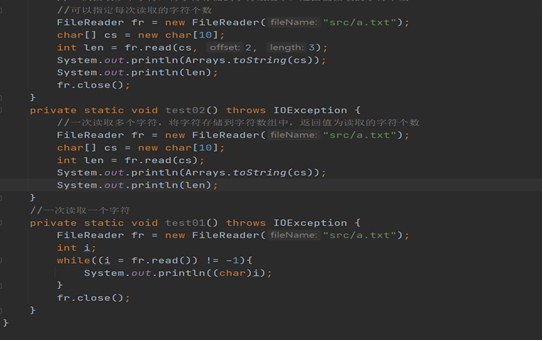
read() :读取一个字符信息,将读到的信息进行返回
read(char[] c) :读取c.length个字符到数组中,返回的是读取的字符个数
read(char[] c,in t offset,int len):读取一部分字符到数组中
close() :关闭流资源
3、使用子类创建对象:FileReader
FileReader(File file)
FileReader(String fileName)
Writer
1、字符输出流,是一个抽象父类,不能直接创建对象
2、方法:
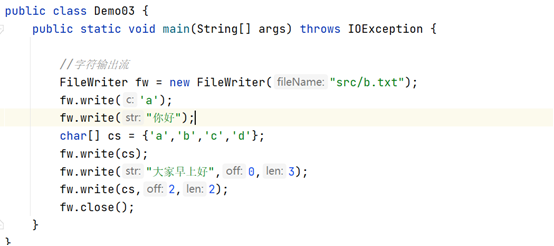
write(int c) :写出一个字符
write(String str) :写出一个字符串
write(char[] cbuf) :写出一个数组中的字符
write(char[] cbuf, int off, int len) :写出数组的一部分到目标文件
write(String str, int off, int len) :写出字符串的一部分
close()
3、FileWriter:文件字符输出流
FileWriter(File file)
FileWriter(String fileName)
4、补充:
在创建输入流的对象时,可以指定一个布尔参数:如果参数为false或者没有写,都是替换写出信息;如果参数为true的,表示追加写出信息(之前的数据不会被替换)
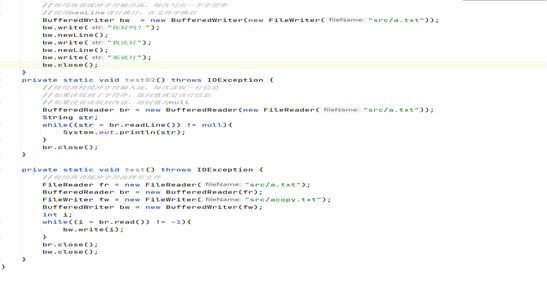
字符流拷贝
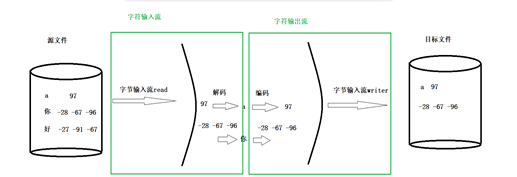
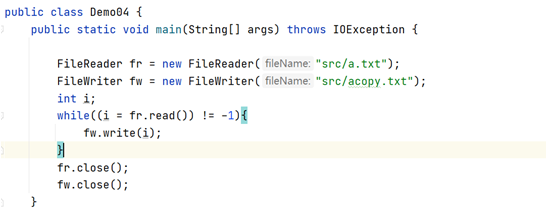
1、原理:
先使用字符输入流读取每个字符,然后使用字符输出流将读取的字符写出到另外一个文 件即可。
2、图示:
3、总结:
如果需要拷贝一个文件,使用哪一个流?
使用字节流去拷贝
如果需要读取文件的信息查看,或者需要将信息写出,使用哪一个流?
使用字符流
使用字符流拷贝非纯文本文件
1、纯文本文件:文件中的信息表示方式都以字符表示
2、非纯文本文件:文件中的信息不是以字符方式表示
比如:图片 视频 音频
3、结论:不能使用字符流拷贝非纯文本文件
4、原因:
因为非纯文本文件底层的每个字节在编码表中可能没有对应的字符;如果读取文件中的 某个字节之后,在解码的时候没有一个字符与之对应,那么就会使用一个?来代替,一 旦使用?代替之后,表示数据已经发生了改变,那么再写出信息时,写出的是?对应的 字节,就导致读取的字节和写出的字节不一致。然后目标文件中的数据就拷贝失败。
高效缓冲字符流
1、类型:BufferedReader和BufferedWriter
2、概述:都是包装类型,需要对基础的字符流对象进行包装。包装之后,一次也可以读取多个字 符,可以写出多个字符。
3、构造:BufferedReader(Reader in)
方法:readLine() :一次可以从输入流中读取一行信息
返回值就是读取的这一行数据,如果到达文件的末尾,返回null
4、构造:BufferedWriter(Writer out)
方法:newLine() :表示在文件中进行换行
转换流
1、在不同的编码表中,不同的字符占用的字节不同
2、在utf-8编码表中,一个英文占用一个字节,一个中文占用三个字节
3、在gbk编码表中,一个英文占用一个字节,一个中文占用两个字节
转换输入流和转换输出流
1、OutputStreamWriter:转换输出流,在输出数据时,可以指定编码格式
构造方法:
OutputStreamWriter(OutputStream in, String cs) :使用基础的输出流对象,指定以cs编码格式来写出信息
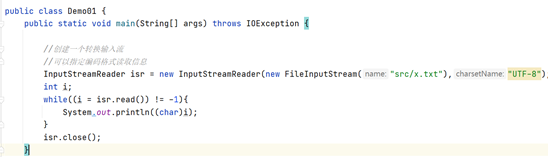
2、InputStreamReader:转换输入流,在输入数据时,可以指定编码格式
InputStreamReader(InputStream in, String cs) :使用基础的输入流对象,指定以cs编码格式读取信息
3、总结:
(1)在读取信息时,以源文件的编码格式读取信息
(2)在写出信息时,以目标文件的编码格式写出信息
(3)使用前提:当读取或者写出信息时,文件的格式和当前代码文件格式不对应时
(4)转换流属于字符流

对象序列化流
1、相关概念:
(1)数据的状态:
游离态:在运行内存中的运行的数据。随着程序的结束,数据也会被回收。
持久态:在磁盘中进行保存的数据。随着程序的结束,随着计算机的关机和开机,数据并不会消失。
(2)序列化:(输出)
将数据从运行内存中 ===> 到磁盘中
数据从游离态===>持久态
(3)反序列化:(输入)
将数据从磁盘中 ===> 到运行内存中
持久态===>游离态
2、对象序列化流的使用:
构造方法:
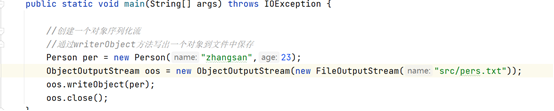
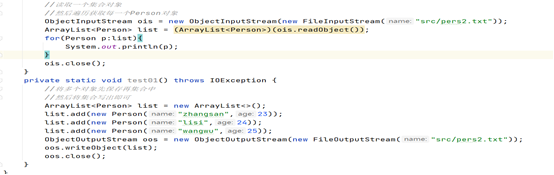
ObjectOutputStream(OutputStream out):将一个输出流,封装为一个对象序列化流
序列化对象方法:
writeObject(Object obj):将指定对象写出到流中传输
注意:
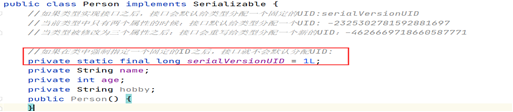
(1)如果某个类型的对象想要实现序列化或者反序列化,那么该类型需要实现Serializable接口,否则无法完成输入和输出。
(2)Serializable属于一个标记型接口,该接口中没有任何抽象方法需要重写,就是用来标记该类型可以实现序列化和反序列的操作。
(3)序列化一个对象之后,该对象在文件中保存的内容看不懂。
3、反序列化流的使用:
构造方法:
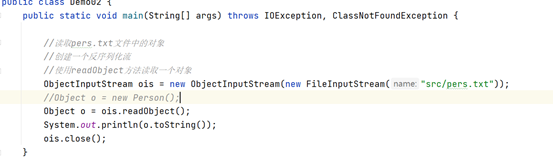
ObjectInputStream(InputStream inp):将一个输入流,封装为一个对象序列化流
反序列化对象方法:
readObject():将对象从文件中读取到内存中
补充
1、如果再读取对象的时候,文件中已经没有数据,还继续读取,就会出现一个异常:
java.io.EOFException 文件到达末尾异常
2、如果需要写出多个对象时,一般情况将多个对象保存再一个集合中,将集合对象写出一次即可,因为只写出一个集合对象,以后再读取时,也只需要读取一次即可,再遍历集 合就可以获取每一个对象了。
3、问题:在写出一个对象之后,将对象所属的类型进行了修改,然后就不能继续使用该类型接收文件中的对象了。
解决:在写出对象之前,在类型中给定一个固定的UID:serialVersionUID
一旦给定一个固定的id之后,类型随意修改,都可以接收对象
代码
transient关键字
1、在实现对象的序列化和反序列化时,如果某些特定的属性不需要参与,就可以通过关键字:transient来修饰该属性,一旦属性被关键字修饰之后,就不参与读取和写出。
