数据类型存储
JavaScript中存在两大数据类型:
- 基本类型
- 引用类型
基本类型:基本类型值在内存中占据固定大小,数据保存在栈内存中
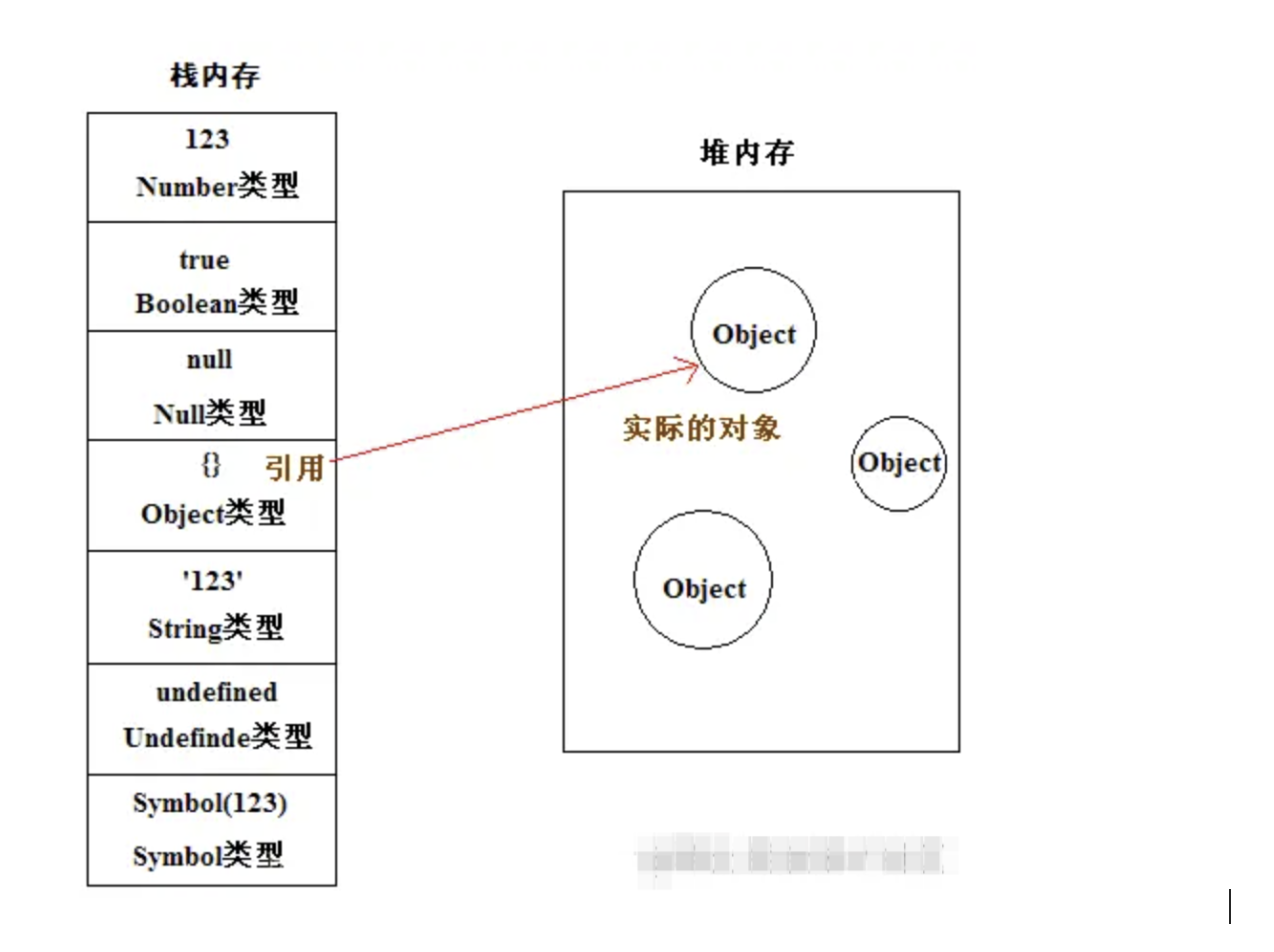
引用类型:引用类型的值是对象,保存在`堆内存`中。而栈内存存储的是对象的变量标识符以及对象在堆内存中的存储地址(引用),引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址。当解释器寻找引用值时,会首先检索其在栈中的地址,取得地址后从堆中获得实体。
浅拷贝
它会创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值;如果属性是引用类型,拷贝的就是内存地址 ,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。
简单来说可以理解为浅拷贝只解决了第一层的问题,拷贝第一层的基本类型值,以及第一层的引用类型地址。
普通一维数组_赋值
const a = [1, 2, 3]; const b = a; a[0] = 9; console.log(a); // [9, 2, 3] console.log(b); // [9, 2, 3]
对象一维数组_赋值
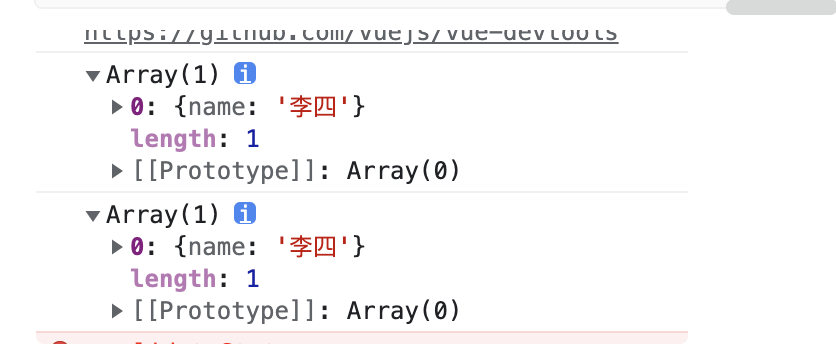
const a = [{ name: "章三" }];
const b = a;
a[0].name = '李四';
console.log(a); // [{ name: "李四" }]
console.log(b); // [{ name: "李四" }]
循环遍历
function cloneData(obj) { if (typeof obj !== 'object') return; const newObj = []; for(let key in obj) { if (obj.hasOwnProperty(key)) { newObj[key] = obj[key]; } } return newObj; } const a = [{name:'张三'}]; const b = cloneData(a); a[0].name = '李四'; console.log(a); // [{name: "李四"}] console.log(b); // [{name: "李四"}]
const a = [{name:'小明'},1];
const b = deepCopy(a);
function deepCopy(arr) {
let newArr = [];
for (let i = 0; i < a.length; i++) {
newArr.push(arr[i]);
}
return newArr;
};
a[0].name= '小王';
a[1]=2;
console.log(a); // [{name:'小王'}, 2]
console.log(b); // [{name:'小王'}, 1]
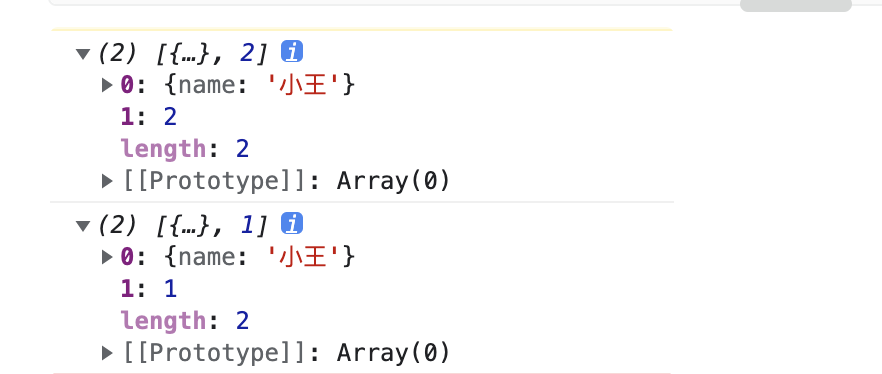
从输出结果可以看出,浅拷贝后,数组中对象的属性会根据修改而改变,说明浅拷贝的时候拷贝的已存在对象的属性引用
ES6 扩展运算符
const a = [{ name: "张三" }];
const b = [...a];
a[0].name = '李四';
console.log(a); // [{ name: "李四" }]
console.log(b); // [{ name: "李四" }]
扩展运算符也是浅拷贝,对于值是对象的属性无法完全拷贝成2个不同对象
Array的slice和concat方法
var a = [1, 3, 5, { x: 1 }]; var b = Array.prototype.slice.call(a); b[0] = 2; b[3].x = 9; console.log(a); // [ 1, 3, 5, { x: 9 } ]; console.log(b); // [ 2, 3, 5, { x: 9 } ];

从输出结果可以看出,浅拷贝后,数组a[0]并不会随着b[0]改变而改变,说明a和b在栈内存中引用地址并不相同。数组中对象的属性会根据修改而改变,说明浅拷贝的时候拷贝的已存在对象的对象的属性引用
map-复杂结构
const a = [{ name: "zhangsan", age: 1 }, { name: "lisi", age: 2 ,obj:{
title:'11111'
}}];
const b=a.map(val=>{
return {...val}
})
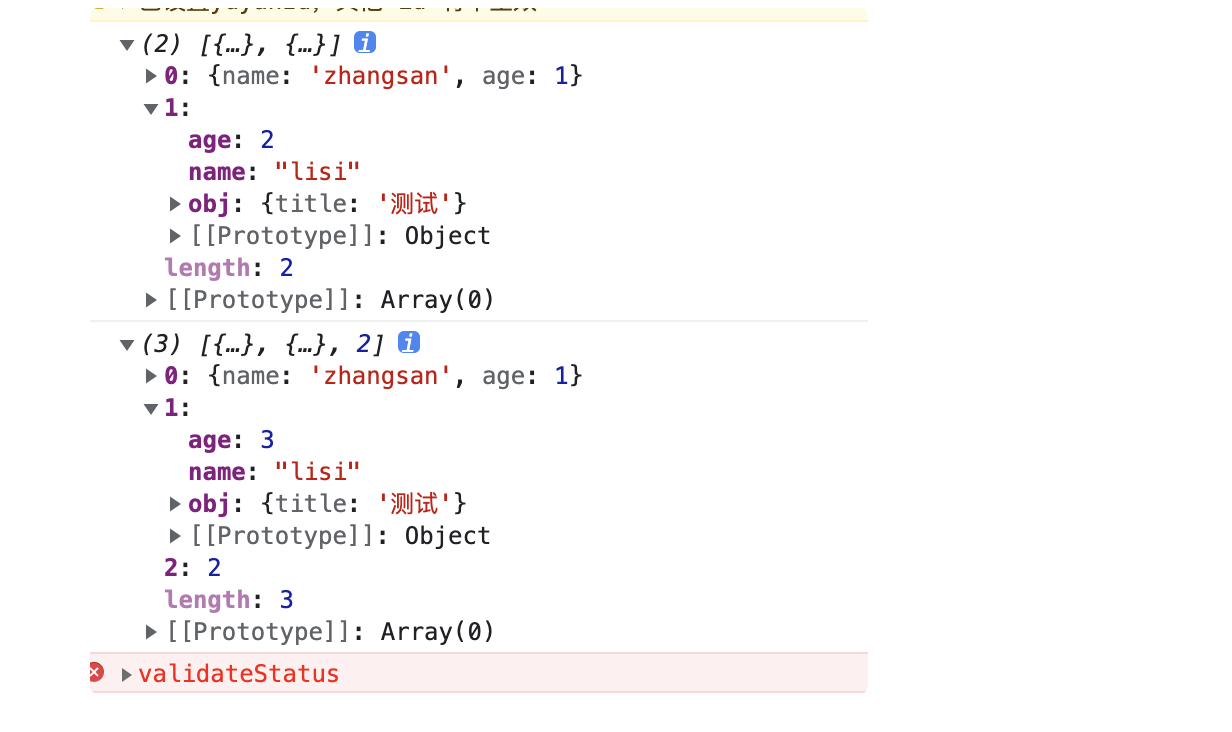
b[1].age = 3;
b[1].obj.title = '测试';
b[2] = 2;
console.log(a);
console.log(b);
深拷贝
深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。
JSON.stringify()
只限于处理可被 JSON.stringify() 编码的值,包含 Boolean Number String 对象 数组。其他任何内容都将被特殊处理。Function Symbol Infinity undefined NaN 会变成 null,Date 对象会被转化为 String,可以调用 toISOString() 方法将其转为字符串。
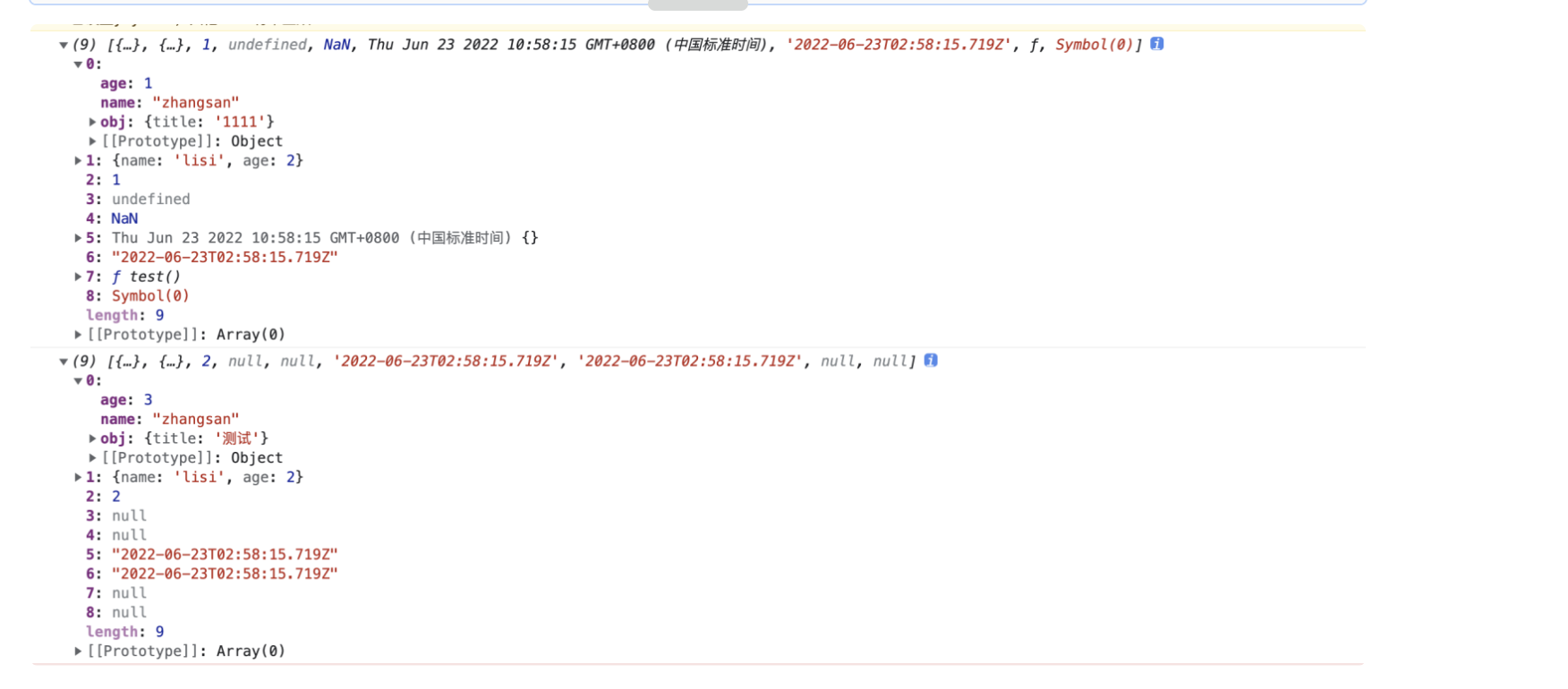
const a = [ { name: 'zhangsan', age: 1,obj:{title:'1111'} }, { name: 'lisi', age: 2 }, 1, undefined, NaN, new Date(), new Date().toISOString(), function test() {}, Symbol('0'), ]; const b = JSON.parse(JSON.stringify(a)); b[0].age = 3; b[0].obj.title = '测试'; b[2] = 2; console.log(a); console.log(b);
循环递归调用(适用于对象和数组)
function deepCopy(target) {
if (typeof target === 'object') {
let cloneTarget = Array.isArray(target) ? [] : {};
for (const key in target) {
if (target.hasOwnProperty(key)) {
cloneTarget[key] = deepCopy(target[key]);
}
}
return cloneTarget;
} else {
return target;
}
};
const a = [{name:'张三'},1];
const b = deepCopy(a);
a[0].name='李四';
a[1]=2;
const c= {age:1};
const d = deepCopy(c);
c.age = 2;
console.log(a); // [{name:'李四'}, 2]
console.log(b); // [{name:'张三'}, 1]
console.log(c); // {age: 2}
console.log(d); // {age: 1}
结论一基本数据类型
在栈内存中的数据发生数据变化的时候,系统会自动为新的变量分配一个新的值在栈内存中,两个变量相互独立,互不影响的。
结论二引用类型
引用类型的复制,同样为新的变量b分配一个新的值,保存在栈内存中,不同的是这个变量对应的具体值不在栈中,栈中只是一个地址指针。两个变量地址指针相同,指向堆内存中的对象,因此b.x发生改变的时候,a.x也发生了改变