什么是监督学习?什么是无监督学习?
引入逻辑回归
逻辑回归主要用于二分类
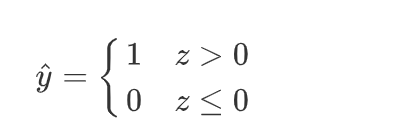
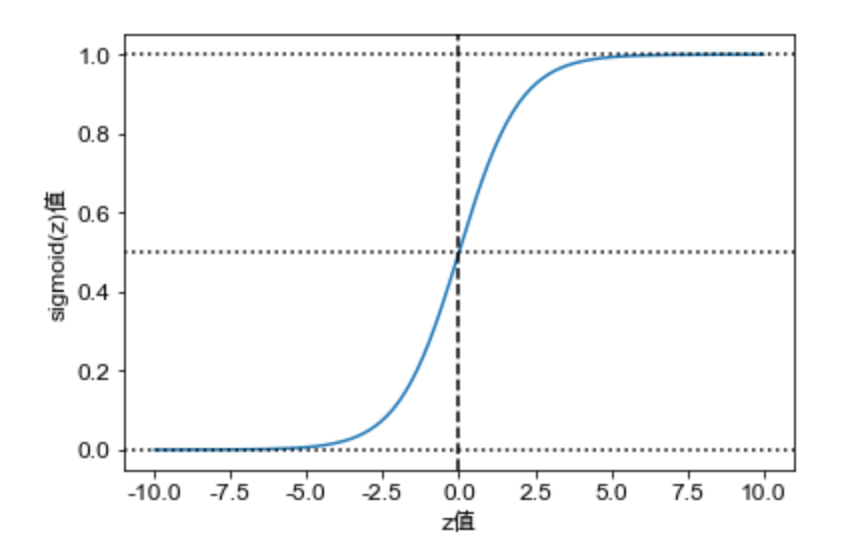
为了将Z值转换为有界的概率值,我们引入sigmoid函数。
sigmoid函数
sigmoid函数也叫S型函数
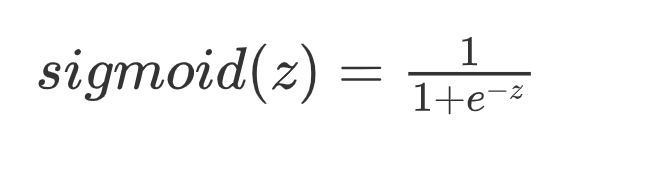
当z=0时,p=sigmoid(z)=0.5,因此上式y预测值还可表示为
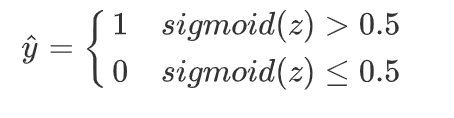
转为概率:
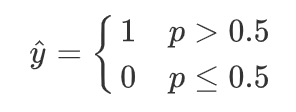
图形为:
计算时,正例的概率为sigmoid(z),负例的概率为1-sigmoid(z).
样本概率:p(y=1|x;w)=S(z)
p(y=0|x;w)=1-S(z)
w的含义:以w作为参数
两式子综合即一个样本的概率:p(y|x;w)=S(z)y(1-S(z))1-y
那么要求解能够使所有样本联合概率密度最大的w值,根据最大似然估计,所有样本的联合概率密度函数(似然函数)为:
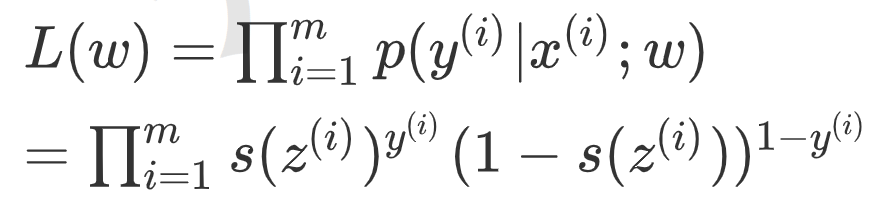
左右取对数:
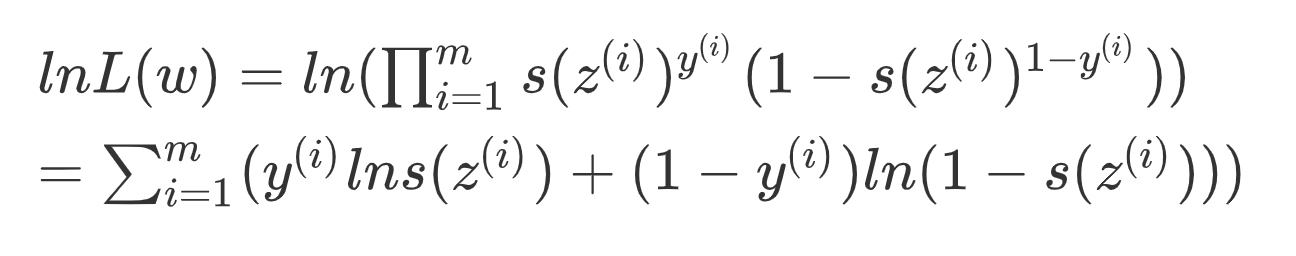
上式最大即相反数最小,引入损失函数
逻辑回归的损失函数(对数损失函数)
![]()
可采用梯度下降求解参数w,即对w求偏导
除以m这一因子并不改变最终求导极值结果,通过除以m可以得到平均损失值,避免样本数量对于损失值的影响
下图用θ表示w:
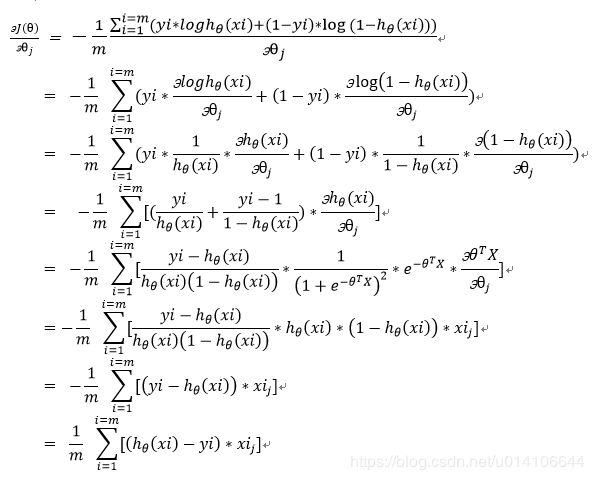
对数损失函数来历总结:样本概率-->联合概率密度--> 取对数-->取相反数
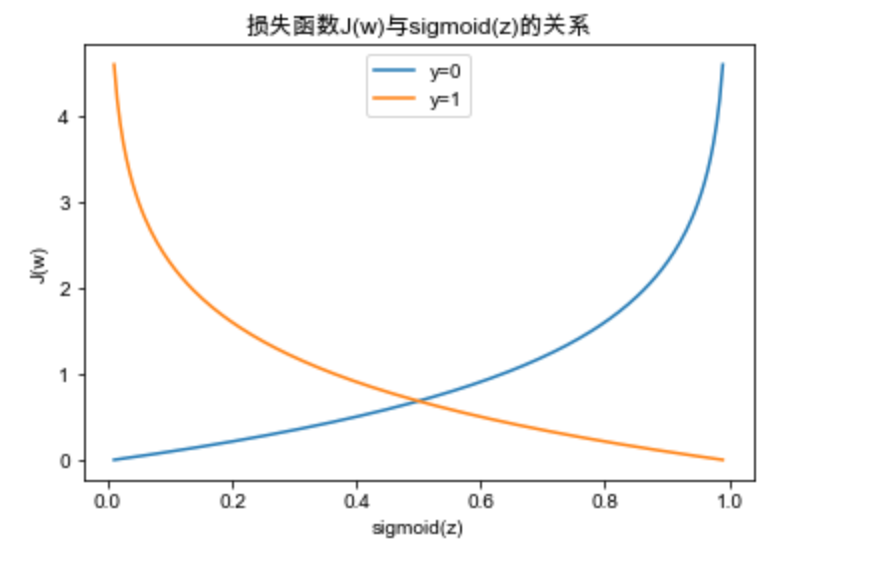
损失函数与sigmoid的关系
当数据为类别1时,我们应当让的值尽可能大,反之,当数据为类别0时,我们应当让的值尽可能小,即1 - 的值尽可能大
逻辑回归实现二分类
以下以鸢尾花数据集为例
# LogisticRegression:逻辑回归的类 from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.datasets import load_iris import warnings warnings.filterwarnings("ignore") iris = load_iris() X, y = iris.data, iris.target # 因为鸢尾花具有三个类别(y=0,1,2),4个特征(列),此处仅使用其中两个特征,并且移除一个类别(类别0)。 X = X[y != 0, 2:] y = y[y != 0] # 此时,y的标签为1与2,我们这里将其改成0与1。(仅仅是为了习惯而已) y[y == 1] = 0 y[y == 2] = 1 # 切分训练集跟测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=2) # 创建逻辑回归对象 lr = LogisticRegression() # 训练集进行训练 确定w和b的值 lr.fit(X_train, y_train) # 将测试集放到模型中得到预测的结果 y_hat = lr.predict(X_test) print("权重:", lr.coef_) print("偏置:", lr.intercept_) print("真实值:", y_test) print("预测值:", y_hat)

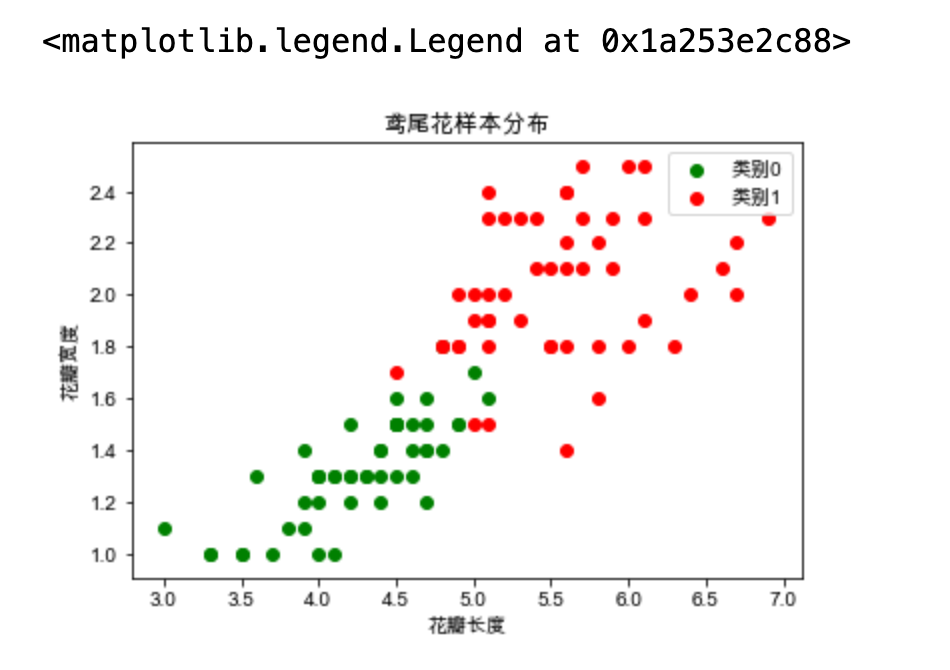
对分类结果进行可视化
# 对分类的结果进行可视化 c1 = X[y == 0] c2 = X[y == 1] plt.scatter(x=c1[:, 0], y=c1[:, 1], c="g", label="类别0") plt.scatter(x=c2[:, 0], y=c2[:, 1], c="r", label="类别1") plt.xlabel("花瓣长度") plt.ylabel("花瓣宽度") plt.title("鸢尾花样本分布") plt.legend()
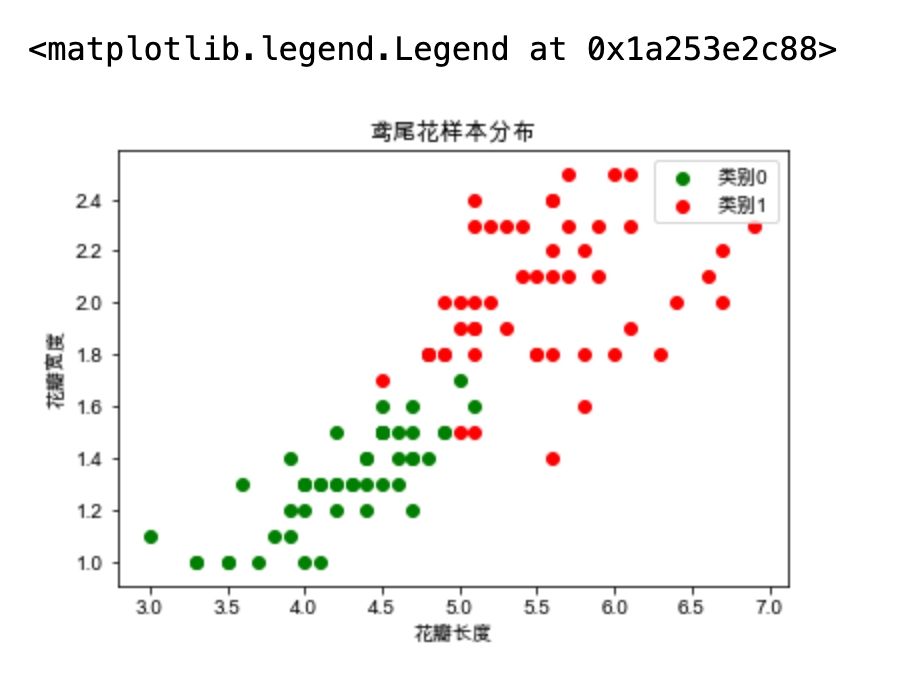
对分类结果进行可视化
# 对分类的结果进行可视化 c1 = X[y == 0] c2 = X[y == 1] plt.scatter(x=c1[:, 0], y=c1[:, 1], c="g", label="类别0") plt.scatter(x=c2[:, 0], y=c2[:, 1], c="r", label="类别1") plt.xlabel("花瓣长度") plt.ylabel("花瓣宽度") plt.title("鸢尾花样本分布") plt.legend()
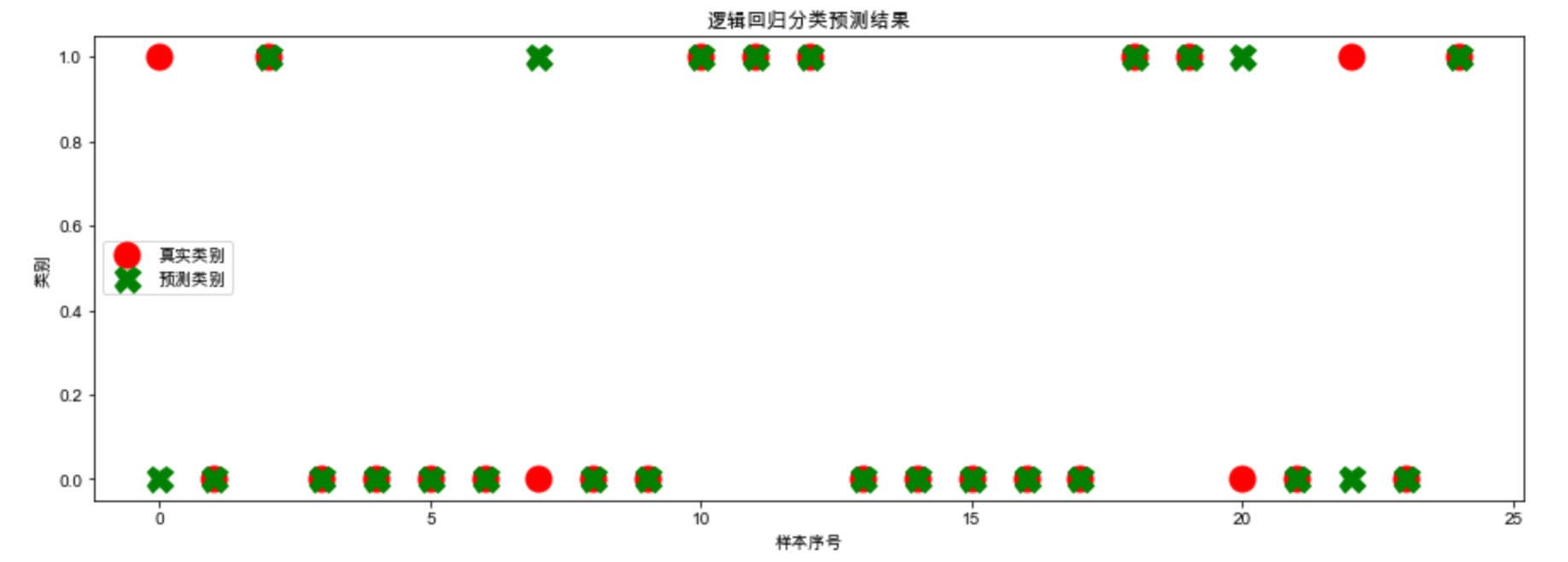
样本的真实类别与预测类别
plt.figure(figsize=(15, 5)) plt.plot(y_test, marker="o", ls="", ms=15, c="r", label="真实类别") plt.plot(y_hat, marker="X", ls="", ms=15, c="g", label="预测类别") plt.legend() plt.xlabel("样本序号") plt.ylabel("类别") plt.title("逻辑回归分类预测结果") plt.show()
计算概率值
# 打分 # 获取预测的概率值,包含数据属于每个类别的概率。返回的概率是通过sigmoid函数计算的(二分类下 ) probability = lr.predict_proba(X_test) # 展示前五行数据的概率值 display(probability[:5]) # 从索引的角度查看最大值,axis=1:只看列索引 display(np.argmax(probability, axis=1)) # 产生序号,用于可视化的横坐标。 index = np.arange(len(X_test))
# 提取0,1的概率 pro_0 = probability[:, 0] pro_1 = probability[:, 1] tick_label = np.where(y_test == y_hat, "O", "X") plt.figure(figsize=(15, 5)) # 绘制堆叠图 plt.bar(index, height=pro_0, color="g", label="类别0概率值") # bottom=x,表示从x的值开始堆叠上去。 # tick_label 设置标签刻度的文本内容。 plt.bar(index, height=pro_1, color='r', bottom=pro_0, label="类别1概率值", tick_label=tick_label) # 图例位置可试着调整,放在图外 plt.legend(loc="best", bbox_to_anchor=(1, 1)) plt.xlabel("样本序号") plt.ylabel("各个类别的概率") plt.title("逻辑回归分类概率") plt.show()

模型lr.predict_proba方法返回的概率:会返回属于样本的每一个概率;是通过sigmoid(z)函数计算的(二分类下)。
绘制决策边界
# 绘制决策边界 # 传入颜色 from matplotlib.colors import ListedColormap # 定义函数,用于绘制决策边界。 # model:模型 比如逻辑回归模型 # X:传入的数据集 (样本集) # y:传入的类别 def plot_decision_boundary(model, X, y): # 定义了三种颜色和标记 color = ["r", "g", "b"] marker = ["o", "v", "x"] # y一共有几个类别 这里只有0,1 class_label = np.unique(y) # ListedColormap定义不同的颜色图 # len :有几个类别取几个颜色 cmap = ListedColormap(color[: len(class_label)]) # x1和x2取不同的值 进行笛卡尔积 x1_min, x2_min = np.min(X, axis=0) x1_max, x2_max = np.max(X, axis=0) # 在最小最大值的基础上加减1是为了绘图时不在边界上,取值间隔为0.02 x1 = np.arange(x1_min - 1, x1_max + 1, 0.02) x2 = np.arange(x2_min - 1, x2_max + 1, 0.02) # 扩展x1,x2以便meshgrid生成笛卡尔积 x1行扩展,x2列扩展 (想象成坐标格子) X1, X2 = np.meshgrid(x1, x2) # print("X1:{} X2:{}".format(X1,X2)) # ravel把二维的X1 X2 拉成一维 # Z的形状要跟X1的形状一致 Z为预测值0,1 Z = model.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape) # print("Z:",Z[0:5,:]) # contourf绘制使用颜色填充的等高线。--不同的值画不同的颜色 画底板颜色 # X1, X2, Z的形状必须相同 # alpha=0.5给一个透明度 让样本看得见 plt.contourf(X1, X2, Z, cmap=cmap, alpha=0.5) # enumerate 函数用于遍历序列中的元素以及它们的下标:返回index,value # 绘制样本颜色 一共两种颜色 一次性先绘制为0的颜色,再绘制为1的颜色 for i, class_ in enumerate(class_label): # print("i:",i) # print("class_:",class_) plt.scatter(x=X[y == class_, 0], y=X[y == class_, 1], c=cmap.colors[i], label=class_, marker=marker[i]) plt.legend() plt.show()
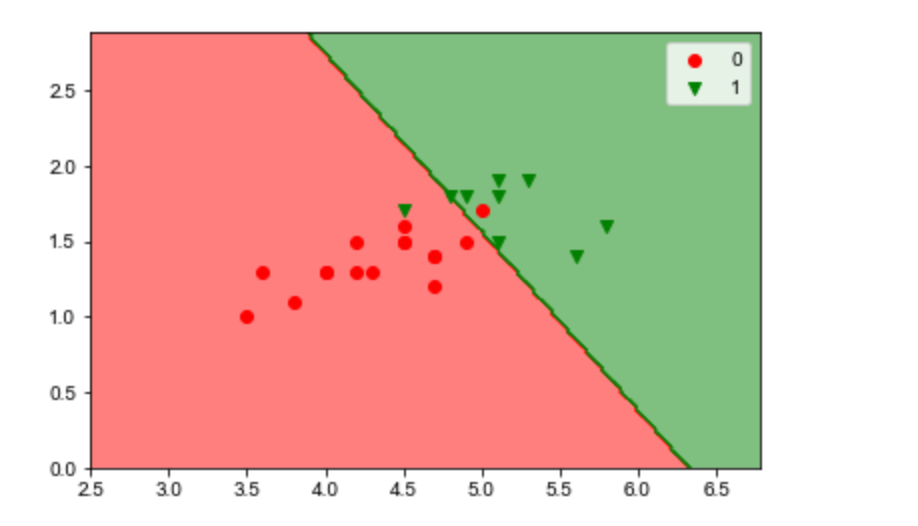
训练集的划分效果
# 训练集的划分效果 plot_decision_boundary(lr, X_train, y_train) # 决策边界的几何意义:W*X=0就是那条决策线,>0就划分为1,<0就划分为0

训练集的划分效果
# 测试集的划分效果 plot_decision_boundary(lr, X_test, y_test)
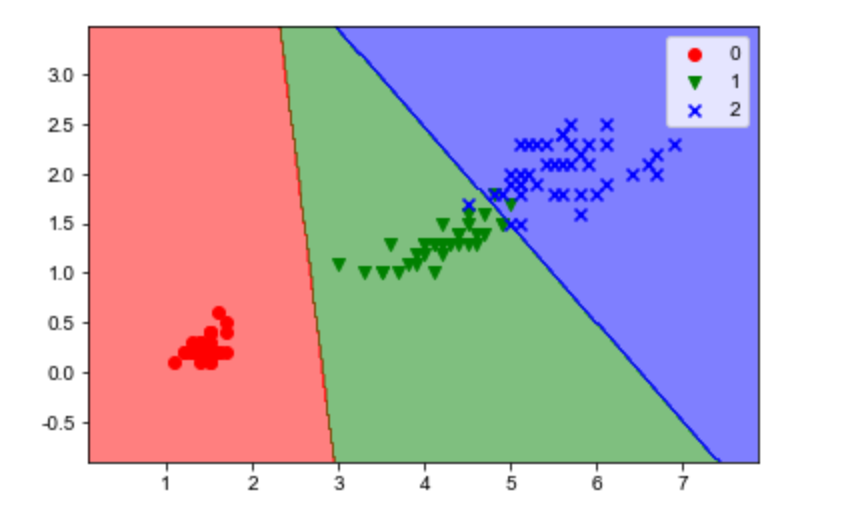
逻辑回归实现多分类
# 逻辑回归实现多分类 是指y值有多个类 # 不把y==2的值踢出去 iris = load_iris() X, y = iris.data, iris.target # 仅使用其中的两个特征。 X = X[:, 2:] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=0) # sklearn中不同版本默认值可能不一样 # multi_class参数,从0.22版本起,默认值从“ovr”变成“auto”。auto的意思为自动选择,如果是二分类,就使用ovr,如果是多分类,就使用“multinomial”。 # solver参数,从0.22版本起,默认值由“liblinear”改为“lbfgs”。solver控制的是优化策略,也就是求解参数w时候的优化方案。 # 第一种 二分类 # lr = LogisticRegression(multi_class="ovr", solver="liblinear") # 第二种 n分类(n>2) # lr = LogisticRegression(multi_class="multinomial", solver="lbfgs") lr = LogisticRegression() lr.fit(X_train, y_train) y_hat = lr.predict(X_test) print("分类正确率:", np.sum(y_test == y_hat) / len(y_test))
分类正确率: 0.9736842105263158
训练集决策边界
# 训练集决策边界 plot_decision_boundary(lr, X_train, y_train)
测试集决策边界
plot_decision_boundary(lr, X_test, y_test)

补充
用于多分类的还有:
- 多项式(multinomial):z有正有负,用ez,它一定大于0,技巧:ez1/( ez1+ ez2+ ez3)
- 一对多(one versus rest) A B C ,是A,不是A;是B,不是B;是C,不是C。
完结散花
参考文献:https://blog.csdn.net/u014106644/article/details/83660226,开课吧
