顺序查找:就是从第一个元素开始,按索引顺序遍历待查找序列,直到找出给定目标或者查找失败
缺点:效率低 -- 需要遍历整个待查序列
二分法查找:也称为折半法,是一种在有序数组中查找特定元素的搜索算法。
1:首先,从数组的中间元素开始搜索,如果该元素正好是目标元素,则搜索过程结束,否则执行下一步。
2:如果目标元素大于/小于中间元素,则在数组大于/小于中间元素的那一半区域查找,然后重复步骤1的操作。
3:如果某一步数组为空,则表示找不到目标元素
树的概念
树:连通无回路的无向图是一棵树.
根:树中的根是树的一个节点,任意节点都可以为根,根据不同问题可以选择树的一个顶点为根.
子节点&父节点:树根为0层,直接和树根相连的节点为根节点的子节点,根节点为其父节点,根节点的子节点为树的1层.对于除了根节点以外的节点u来说,直接与其相连的节点中,除了一个父节点以外的所有节点都是u的子节点,u节点的子节点的层数为u节点的层数加1.
子树:对于树中的一个节点u来说,包含其一个儿子节点以及儿子节点的所有后辈节点的树称为节点u的子树.
兄弟节点:同一父节点的子节点.
叶子节点:没有子节点的节点称为叶子节点.
分支节点:除了根节点和叶子节点之外的所有节点都称为分支节点.
树高:树的总层数.
树的种类
无序树:任意子节点之间没有顺序关系,也称自由树
有序树:任意节点的子节点之间有顺序关系,如下:
二叉树:如果每个节点的儿子节点不多于两个,则称这棵树为二叉.每个父节点的子节点用左右儿子节点来加以区分,以左儿子节点为根的子树称为左子树,以右儿子节点为根的树称为右子树.
满二叉树:如果一个二叉树的任何节点或者树叶,或者恰好有两颗非空子树,则此二叉树称为满二叉树.
完全二叉树:如果一棵二叉树最多只有最下面的两次节点度数小于2,并且最下面一层的节点都集中在该层的最左边的连续位置,成称其实完全二叉树.
平衡二叉树(Balanced Binary Tree)又被称为AVL树(有别于AVL算法),且具有以下性质:它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树.
储存:链式储存。
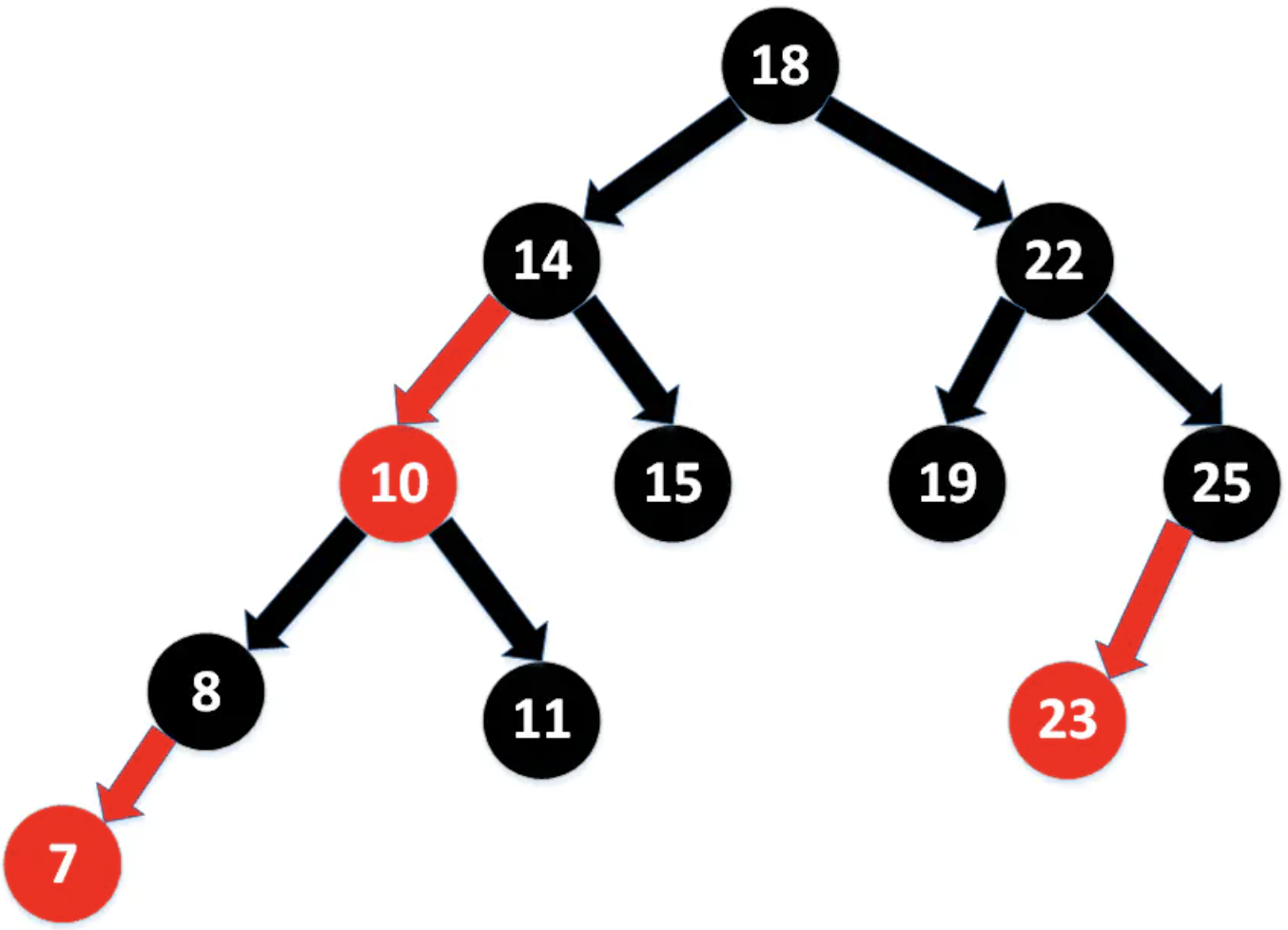
二叉树特点:查找速度和比较次数最小,但是磁盘IO,当数据量过大的时候,索引大小可能有几个G,不可能全都加载到内存
引出下面的树更稳
B树与B+树
B树 、B - 树都读B树。
B树与B+树区别:
B树每个节点都存储数据,所有节点组成这棵树。B+树只有叶子节点存储数据(B+数中有两个头指针:一个指向根节点,另一个指向关键字最小的叶节点),叶子节点包含了这棵树的所有数据,所有的叶子结点使用链表相连,便于区间查找和遍历,所有非叶节点起到索引作用。
B树中叶节点包含的关键字和其他节点包含的关键字是不重复的,B+树的索引项只包含对应子树的最大关键字和指向该子树的指针,不含有该关键字对应记录的存储地址。
B树中每个节点(非根节点)关键字个数的范围为[m/2(向上取整)-1,m-1](根节点为[1,m-1]),并且具有n个关键字的节点包含(n+1)棵子树。B+树中每个节点(非根节点)关键字个数的范围为[m/2(向上取整),m](根节点为[1,m]),具有n个关键字的节点包含(n)棵子树。
B+树中查找,无论查找是否成功,每次都是一条从根节点到叶节点的路径。
B树的优点:
b+树的中间节点不保存数据,能容纳更多节点元素。
B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。
M阶B+数特点
有n棵子树的非叶子结点中含有n个关键字(b树是n-1个),这些关键字不保存数据,只用来索引,所有数据都保存在叶子节点(b树是每个关键字都保存数据)。
所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接(叶子节点组成一个链表)。
所有的非叶子结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
通常在b+树上有两个头指针,一个指向根结点,一个指向关键字最小的叶子结点。
同一个数字会在不同节点中重复出现,根节点的最大元素就是b+树的最大元素。
B树和B+树的共同优点
考虑磁盘IO的影响,它相对于内存来说是很慢的。数据库索引是存储在磁盘上的,当数据量大时,就不能把整个索引全部加载到内存了,只能逐一加载每一个磁盘页(对应索引树的节点)。所以我们要减少IO次数,对于树来说,IO次数就是树的高度,而“矮胖”就是b树的特征之一,m的大小取决于磁盘页的大小。
虽然查询次数比二叉树多,尤其当单一节点元素多时,但是相比磁盘IO速度,内存中的比较耗时几乎可以忽略
所以只要树的高度是够低,IO次数是足够少,就可以提升查找性能
IO:每一次读取的数据称之为一页.
B树与B+树比较:
- 同样大小的磁盘页B+树可以容纳更多的节点元素,也就意味着B+树更矮胖,查询时IO次数更少;
- B+树的查询必须最终是叶子节点,而B-树只要找到匹配元素即可,因此,B+树查找性能稳定,B树不稳定;
- 范围查询简便,所有的叶子结点使用有序链表相连,便于区间查找和遍历.
B树示意图: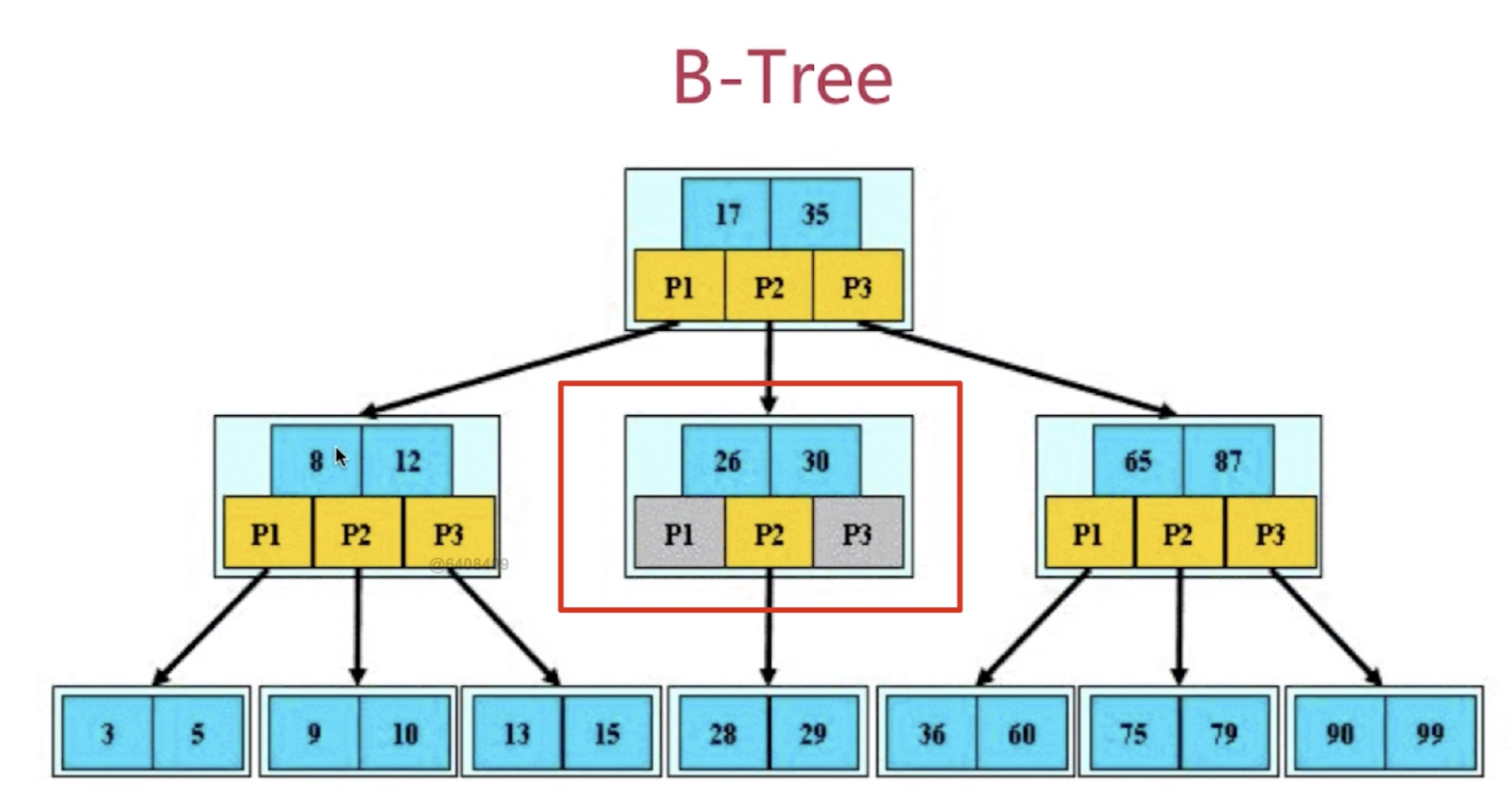
以下为 B+树示意图:


存储引擎: MyISAM和InnoDB
在MySQL中,最常用的两个存储引擎是MyISAM和InnoDB,它们对索引的实现方式是不同的
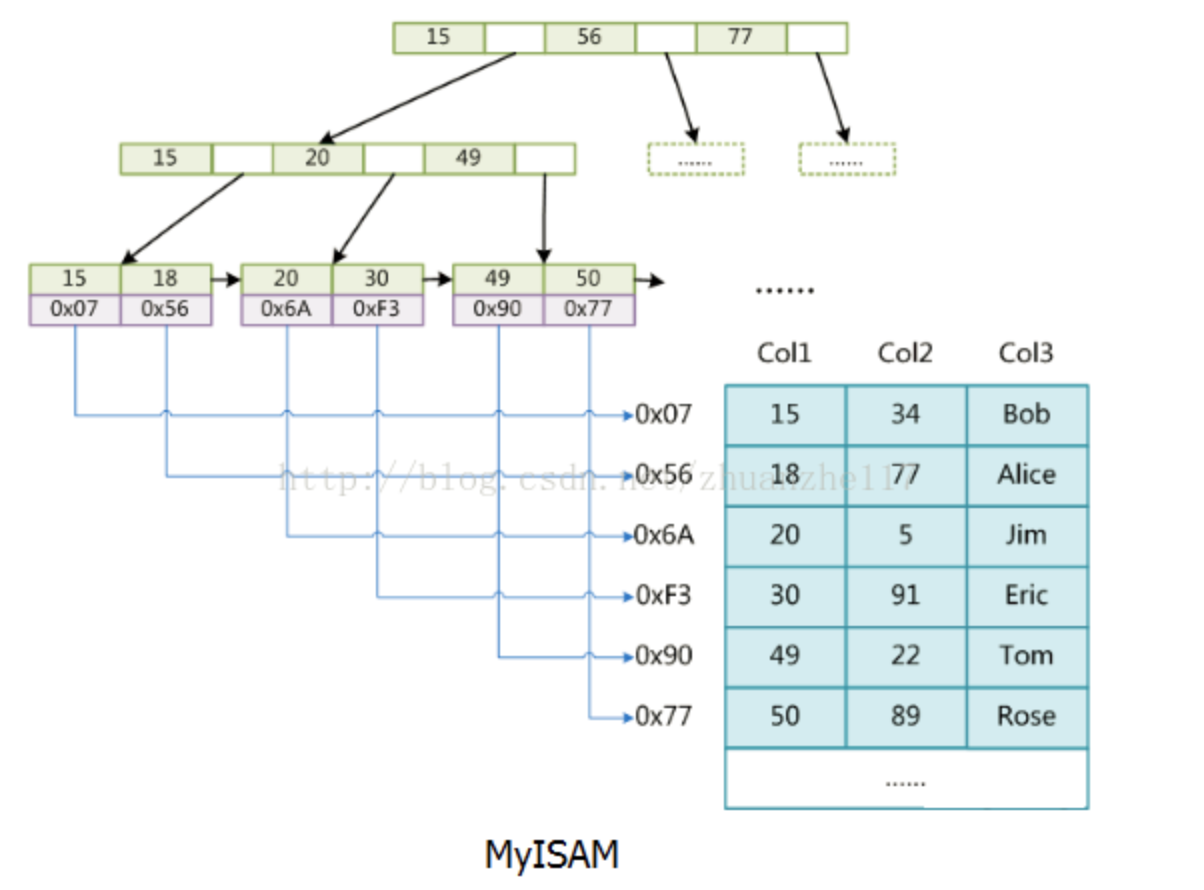
MyISAM : data存的是数据地址。索引是索引,数据是数据。索引放在XX.MYI文件中,数据放在XX.MYD文件中,所以也叫非聚集索引
InnoDB: data存的是数据本身。索引也是数据。数据和索引存在一个XX.IDB文件中,所以也叫聚集索引。
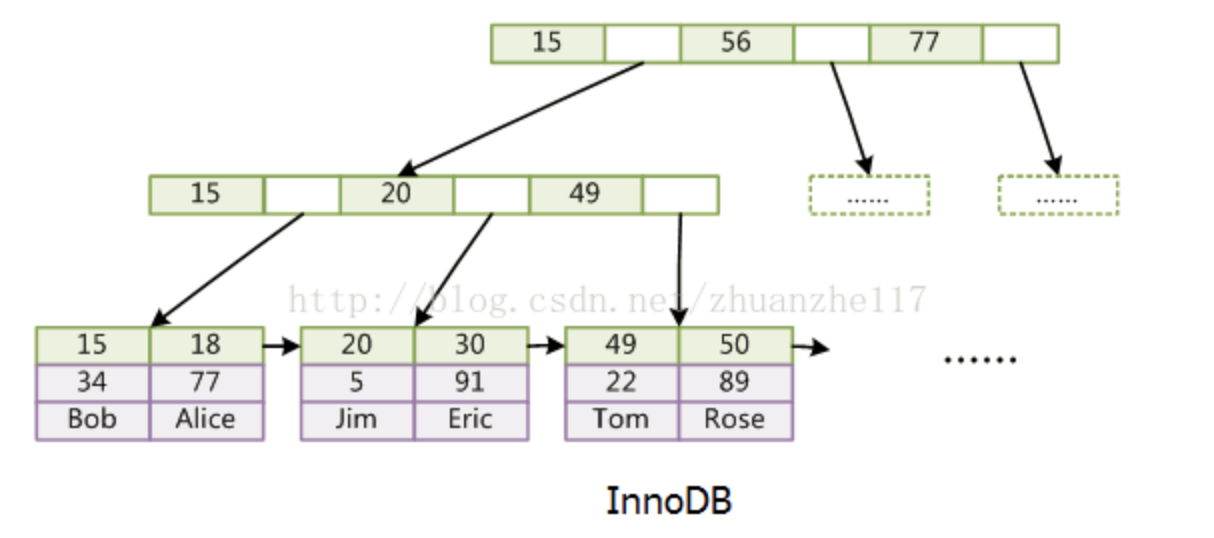
我们的Mysql数据库用的InnoDB。
了解了数据结构再看索引,一切都不费解了,只是顺着逻辑推而已。另加两种存储引擎的区别:
1、MyISAM是非事务安全的,而InnoDB是事务安全的
2、MyISAM锁的粒度是表级的,而InnoDB支持行级锁
3、MyISAM支持全文类型索引,而InnoDB支持全文索引
4、MyISAM相对简单,效率上要优于InnoDB,小型应用可以考虑使用MyISAM
5、MyISAM表保存成文件形式,跨平台使用更加方便
6、MyISAM管理非事务表,提供高速存储和检索以及全文搜索能力,如果在应用中执行大量select操作可选择
7、InnoDB用于事务处理,具有ACID事务支持等特性,如果在应用中执行大量insert和update操作,可选择。
https://www.cnblogs.com/daguozb/p/8665506.html
https://www.cnblogs.com/Ash-ly/p/5459688.html
https://www.jianshu.com/p/f456d7c80ffb
https://blog.csdn.net/weixin_42228338/article/details/97684517
https://blog.csdn.net/zhuanzhe117/article/details/78039692