优势和劣势
使用Parallel.Invoke的优势就是使用它执行很多的方法很简单,而不用担心任务或者线程的问题。然而,它并不是适合所有的场景。Parallel.Invoke有很多的劣势
如果你使用它来启动那些需要执行很长时间的方法,它将会需要很长时间才能返回。这可能会导致很多的核心在很长时间都保持闲置。因此,使用这个方法的时候测量执行速度和逻辑核心使用率很重要。
它对并行的伸缩性有限制,因为它只能调用固定数目的委托。在前面的例子中,如果你在一个有16个核心的电脑上执行,它将只会并行启动四个方法。因此,12个逻辑核心仍然保持闲置。
每次使用这个方法执行并行方法之前都会增加额外的开销。
就像任何的并行代码,不同的方法之间存在内部依赖和难以控制的交互,会导致难以探测的并行bug和难以预料的副作用。然而,这个劣势是使用所有的并行代码,它并不是使用Parallel.Invoke是才存在的问题。
无法保证需要并行的方法的执行顺序;因此,Parallel.Invoke并不适合执行那些需要特定执行计划的复杂算法。
使用不同的并行执行计划启动的任何一个委托都可能抛出异常;因此,捕获和处理这些异常会比传统的串行代码更复杂。
交错并发和并发
正如你在前边例子和图片2-5中所看到的,交错并发和并发是不同的事情。
交错并发意味着在重叠的时间段内可以开始、执行和结束不同部分的代码。交错并发甚至可以运行在只有一个逻辑核心的电脑上。当很多的代码交错运行在只有一个逻辑核心的电脑上时,时间调度策略和快速的上下文切换提供了并行执行的假象。然而,使用这种硬件,交错执行这些代码比单独执行某一端独立的代码需要更多的时间,因为这些并发的代码是需要竞争硬件资源的。你可以讲交错并行想象成多辆卡车共享同一条车道。这也就是为什么交错并发也被定义为一种虚拟的并行。
并发意味着不同的代码可以同时执行,充分利用底层硬件的并发处理能力。真正的并发是不能发生在只有一个逻辑核心的计算机上。为了执行并行代码你至少需要两个逻辑核心。当真正的并发发生的时候是可以提升执行速度的,因为并行执行代码可以减少完成特定算法必须的时间开销。前边的图中提供了如下的可能的并发场景:
并发,四个逻辑核心的理想并行—在这种理想的情形下,四个方法的指令分别执行在一个不同的逻辑核心上。
结合交错并发和并发;并不完美的并行四个方法只能利用两个逻辑核心—有时,四个方法的执行并行运行在不同的逻辑核心上,有时它们必须等待它们的时间片。在这种情况下,交错并发结合了真正的并行。这是最普遍的情形,因为即使是在实时操作系统中,也确实很难实现完美的并行。

图 2-5
循序代码转化为并行代码
在过去十年,大多的C#编写的代码是顺序和同步执行的。因此,很多的算法的思想既没有并发也没有并行。大多的时间,你很难发现可以完整的转换成完全并行和完美伸缩性代码的方法。即使可以找到,但是这并不是最普遍的场景。
当你有并行代码并想利用潜在的并行来提升执行速度的时候,你必须找到可以并行的热点区域。然后,你可以将他们转化成并行代码,测试执行速度,确定潜在的伸缩性,并且确保在将现存顺序代码转换成并行代码的时候没有引入新的bug。
探测并行热点
列表2-3展示了一个例子,这是一个执行了如下两个顺序的方法的简单的控制台应用程序。
GenerateAESKeys—这个方法执行一个for循环,并根据指定的常量字段NUM_AES_KEYS产生相应数目的AES键。它使用System.Security.Cryptography.AesManaged类提供的GenerateKey方法。一旦产生了这个键,就会将这个byte数据转化成十六进制字符串形式,并将转换的结果保存在局部变量hexString里。
GenerateMD5Hashes—这个方法执行一个for循环,并使用md5算法根据给定的常量NUM_MD5_HASHES来产生相应数目的哈希值。它使用用户名作为参数调用System.Security.Cryptography.MD5类提供的ComputeHash方法。一旦产生了哈希值,就会将这个byte数组转换成十六进制的字符串形式,并使用局部变量hexString保存。

using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
// Added for the Stopwatch
using System.Diagnostics;
// Added for the cryptography classes
using System.Security.Cryptography;
// This namespace will be used later to run code in parallel
using System.Threading.Tasks;
namespace Listing2_3
{
class Program
{
private const int NUM_AES_KEYS = 800000;
private const int NUM_MD5_HASHES = 100000;
private static string ConvertToHexString(Byte[] byteArray)
{
// Convert the byte array to hexadecimal string
var sb = new StringBuilder(byteArray.Length);
for (int i = 0; i < byteArray.Length; i++)
{
sb.Append(byteArray[i].ToString("X2"));
}
return sb.ToString();
}
private static void GenerateAESKeys()
{
var sw = Stopwatch.StartNew();
var aesM = new AesManaged();
for (int i = 1; i <= NUM_AES_KEYS; i++)
{
aesM.GenerateKey();
byte[] result = aesM.Key;
string hexString = ConvertToHexString(result);
// Console.WriteLine(“AES KEY: {0} “, hexString);
}
Debug.WriteLine("AES: " + sw.Elapsed.ToString());
}
private static void GenerateMD5Hashes()
{
var sw = Stopwatch.StartNew();
var md5M = MD5.Create();
for (int i = 1; i <= NUM_MD5_HASHES; i++)
{
byte[] data =
Encoding.Unicode.GetBytes(
Environment.UserName + i.ToString());
byte[] result = md5M.ComputeHash(data);
string hexString = ConvertToHexString(result);
// Console.WriteLine(“MD5 HASH: {0}”, hexString);
}
Debug.WriteLine("MD5: " + sw.Elapsed.ToString());
}
static void Main(string[] args)
{
var sw = Stopwatch.StartNew();
GenerateAESKeys();
GenerateMD5Hashes();
Debug.WriteLine(sw.Elapsed.ToString());
// Display the results and wait for the user to press a key
Console.ReadLine();
}
}
}
方法GenerateAESKeys中的for循环在代码里没有使用它的控制变量i,因为它仅仅控制产生一个随机AES key的次数。然而,在方法GenerateMD5Hashes中将它的控制变量i添加到计算机用户名后边。然后,使用这个字符串作为调用产生哈希值的方法的输入数据,具体的代码如下代码所示
{
byte[] data = Encoding.Unicode.GetBytes(Environment.UserName + i.ToString());
byte[] result = md5M.ComputeHash(data);
string hexString = ConvertToHexString(result);
// Console.WriteLine(hexString);
}
清单2-3中的高亮代码行是测量每个方法执行的总时间。它通过在每个方法开始的时候调用StartNew方法来开始一个新的StopWatch,然后最终将消耗的时间写到Debug的输出中。
清单2-3中也展示了那些被注释掉的输出产生的key和哈希值的语句,因为这些操作会将字符串发送到控制台,这将会产生性能瓶颈影响时间测试的准确性。
图2-6展示了这个程序的顺序执行流程和在一个有双核微处理器的计算机上执行前边两个方法所分别使用的时间。
两个方法需要执行将近14秒。第一个方法执行8s,后一个需要6s。当然,这些消耗的时间会随底层的硬件配置产生很大的变化。这两个方法之间没有进行任何的交互;因此,他们之间是完全的相互独立的。就这样一个接着一个的顺序执行,是不能利用令外一个核心提供的并行处理能力的。因此,这两个方法就是一个并行的热区,在这里并行可以帮助我们完成一个重大的执行速度的提升。例如,你可以使用Parallel.Invoke并行的执行这两个方法。
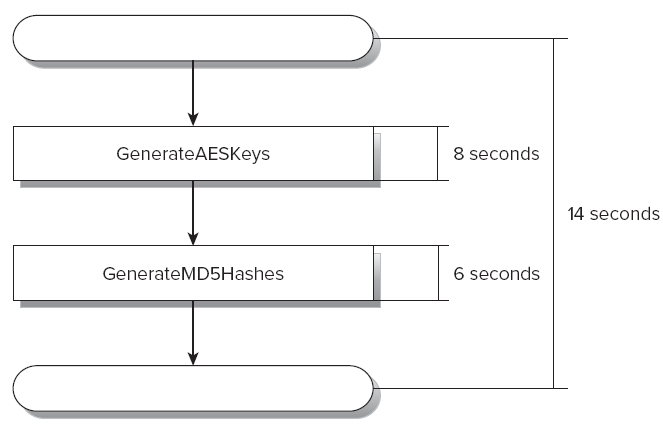
图 2-6
测量并行的执行速度提升
使用下边的新版本替换列表2-3中的Main方法,这里使用Parallel.Invoke来并行启动两个方法。
{
var sw = Stopwatch.StartNew();
Parallel.Invoke(
() => GenerateAESKeys(),
() => GenerateMD5Hashes());
Debug.WriteLine(sw.Elapsed.ToString());
// Display the results and wait for the user to press a key
Console.WriteLine(“Finished!”);
Console.ReadLine();
}
图2-7展示了这个程序的新版本的并行执行流程和两个方法在使用双核微处理器的计算机上执行消耗的时间。
现在两个方法执行将近9m,因为他们利用了微处理器提供的两个核心。因此,你可以使用下边的公式计算其可以实现的速度提升:
Speedup = (Serial execution time) / (Parallel execution time)
14 / 9 = 1.56x

图 2-7
正如你所看到的,GenerateAESKeys比GenerateMD5Hashes消耗了更长的时间:9:6。然而,如果所有的委托没有都执行结束,Parallel.Invoke是不会执行下边的代码的。因此,最后的3s,应用程序并没有利用每一个核心,存在一个load-imbalance的问题,如图2-8所示。
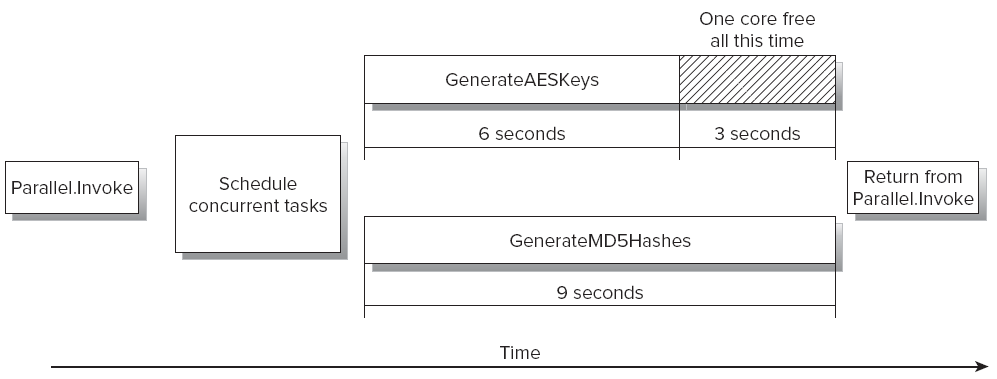
图 2-8
如果这个应用程序运行在一个有四核微处理器的计算机上,它的速度提升几乎是一样的,因为它不能调度使用底层硬件的另外两个核心。
在这个例子中,你检测并行的热点,并添加一些代码来测试执行特定方法消耗的时间。然后,你可以仅仅改变几行代码完成一个有趣的执行速度提升。当在数据并行场景中可用核心的数目增加时,你现在需要知道命令数据并行TPL结构来实现一个更好的结果并改善伸缩性。
理解并行执行
接下来,你需要解除在方法GenerateMD5Hashes和GenerateAESKeys中注释的有关向控制台输出的代码行:
Console.WriteLine(“AESKEY: {0} “, hexString);
Console.WriteLine(“MD5HASH: {0}”, hexString);
向控制台输出对并行执行会产生性能瓶颈。然而,这次,现在不需要测试准确的时间。相反,你也可以看到并行执行的两个方法的输出结果。列表2-4展示了这个程序产生的一个控制台输出的例子。列表中高亮的短十六进制字符串是相应的MD5哈希。其他的十六进制字符串展示的是AES key。每一个AES key消耗的时间比每个md5哈希要短。记住那段代码产生了800000 AES key和100000 MD5哈希。

List2-4
现在,注释掉这两个方法中那些输出结果到控制台的代码。