目标函数
Lasso相当于带有L1正则化项的线性回归。先看下目标函数:RSS(w)+λ∥w∥1=∑Ni=0(yi−∑Dj=0wjhj(xi))2+λ∑Dj=0∣wj∣RSS(w)+λ∥w∥1=∑i=0N(yi−∑j=0Dwjhj(xi))2+λ∑j=0D∣wj∣ RSS(w)+lambda Vert wVert_1=sum_{i=0}^{N}(y_i-sum_{j=0}^D{w_jh_j(x_i)})^2+lambda sum_{j=0}^{D}|w_j| RSS(w)+λ∥w∥1=∑i=0N(yi−∑j=0Dwjhj(xi))2+λ∑j=0D∣wj∣
这个问题由于正则化项在零点处不可求导,所以使用非梯度下降法进行求解,如坐标下降法或最小角回归法。
坐标下降法
本文介绍坐标下降法。
坐标下降算法每次选择一个维度进行参数更新,维度的选择可以是随机的或者是按顺序。
当一轮更新结束后,更新步长的最大值少于预设阈值时,终止迭代。
下面分为两部求解
RSS偏导
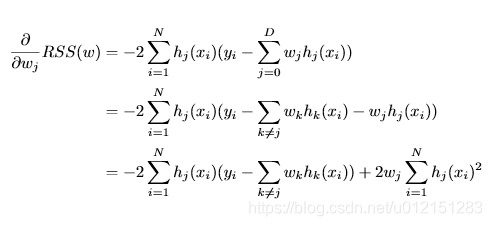
下面做一下标记化简
ρj=∑Ni=1hj(xi)(yi−∑k≠jwkhk(xi))ρj=∑i=1Nhj(xi)(yi−∑k≠jwkhk(xi))
ho_j=sum_{i=1}^Nh_j(x_i)(y_i-sum_{k
eq j }w_kh_k(x_i))
ρj=∑i=1Nhj(xi)(yi−∑k̸=jwkhk(xi))
zj=∑Ni=1hj(xi)2zj=∑i=1Nhj(xi)2 z_j=sum_{i=1}^N h_j(x_i)^2
zj=∑i=1Nhj(xi)2
上式化简为