原文链接:https://www.cnblogs.com/ftl1012/p/vmstat.html
常见命令展示
参数
-a:显示活跃和非活跃内存
-f:显示从系统启动至今的fork数量 。
-m:显示slabinfo
-n:只在开始时显示一次各字段名称。
-s:显示内存相关统计信息及多种系统活动数量。
delay:刷新时间间隔。如果不指定,只显示一条结果。
count:刷新次数。如果不指定刷新次数,但指定了刷新时间间隔,这时刷新次数为无穷。
-d:显示磁盘相关统计信息。
-p:显示指定磁盘分区统计信息
-S:使用指定单位显示。参数有 k 、K 、m 、M ,分别代表1000、1024、1000000、1048576字节(byte)。默认单位为K(1024 bytes)
-V:显示vmstat版本信息。
vmstat 5 5 【在5秒时间内进行5次采样】

字段说明:
Procs(进程):
- r:运行队列中进程数量,这个值也可以判断是否需要增加CPU,如果该值大于CPU的核数,例如2核,代表需要升级服务器,升级成4核或者8核,如果r经常大于4,id经常少于40,表示cpu的负荷很重。
- b:等待IO的进程数量,等待IO处理,等待内存交换等等,表示阻塞的进程
Memory(内存):
- swpd: 表示切换到内存交换区域的内存大小,通常来讲是虚拟内存的大小,如果不为0或者是比较大的时候,si,so长期为0正常,或者比较大,说明虚拟内存不正常。
- free: 可用内存大小,当前空闲物理内存的大小
- buff: 用作缓冲的内存大小,一般来说,块设备的读写才需要缓冲,不用太严密的监控
- cache: 用作缓存的内存大小,文件系统进行缓冲区域,频繁访问的文件会被缓存,如果cache非常大,说明我们的缓存文件比较多,结合io的bi来看,如果bi比较小,说明我们的文件系统效率非常高
Swap:
- si: 每秒从交换区写到内存的大小,由磁盘调入的内存的值,从我们内存进入虚拟内存的内存交换区的内存大小
- so: 每秒写入交换区的内存大小,内存进入磁盘的大小
- 一般情况下这两个值都是0,如果这两个值长期不为0,说明系统内存严重不足,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉
IO:(现在的Linux版本块的大小为1024bytes)
- bi: 每秒读取的块数,kb/s,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
- bo: 每秒写入的块数,kb/s
- 如果读写的和过大,并且cpu的wa的值比较大(不大不用考量),系统磁盘io存在瓶颈,应该提高磁盘读写性能
- 如果bi,bo长期不等于0,表示内存不足,bi和bo一般都要接近0,不然就是IO过于频繁,需要调整
system(系统):
- in: 每秒中断数,包括时钟中断。某个时间段内观察到每秒设备中断数【interrupt】
- cs: 每秒上下文切换数。 【count/second】例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
- 这两个值越大,表示内核的CPU就越多,不常监控
CPU(以百分比表示):
- us: 表示用户进程消耗CPU时间的百分比(user time),us的值越高,用户进程消耗的CPU越多,如果us的值长期大于50%,要考虑优化程序和算法,如果us的值长期大于80%,则表示产生了瓶颈(我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。)
- sy: 表示系统内核进程消耗的CPU时间的百分比(system time),如果这个值比较大,说明内核消耗的CPU比较多,应该小于80% 大于80%,有瓶颈
- id: 空闲时间(包括IO等待时间),中央处理器的空闲时间 。以百分比表示。
- wa: io等待的时间百分比,过大,磁盘大量读写或者磁盘控制器造成的
- st 不需要考量
显示活跃和非活跃内存
vmstat -a 2 5 【-a 显示活跃和非活跃内存,所显示的内容除增加inact和active】

显示从系统启动至今的fork数量
vmstat -f 【 linux下创建进程的系统调用是fork】

说明: 信息是从/proc/stat中的processes字段里取得的
查看内存使用的详细信息
vmstat -s 【显示内存相关统计信息及多种系统活动数量】

说明:这些信息的分别来自于/proc/meminfo,/proc/stat和/proc/vmstat
查看磁盘的读/写
vmstat -d 【查看磁盘的读写】

说明:这些信息主要来自于/proc/diskstats.
查看/dev/sda1磁盘的读/写
vmstat -p /dev/sda1 【显示指定磁盘分区统计信息】

说明:这些信息主要来自于/proc/diskstats.
reads:来自于这个分区的读的次数。
read sectors:来自于这个分区的读扇区的次数。
writes:来自于这个分区的写的次数。
requested writes:来自于这个分区的写请求次数。
查看系统的slab信息
vmstat -m
说明:这些信息主要来自于/proc/slabinfo
slab:由于内核会有许多小对象,这些对象构造销毁十分频繁,比如i-node,dentry,这些对象如果每次构建的时候就向内存要一个页(4kb),这样就会非常浪费,为了解决这个问题,就引入了一种新的机制来处理在同一个页框中如何分配小存储区,而slab可以对小对象进行分配,这样就不用为每一个对象分配页框,从而节省了空间,内核对一些小对象创建析构很频繁,slab对这些小对象进行缓冲,可以重复利用,减少内存分配次数。
查看进程路径
[root@localhost ~]# netstat -an | grep 2158
[root@localhost ~]# ll /proc/2158
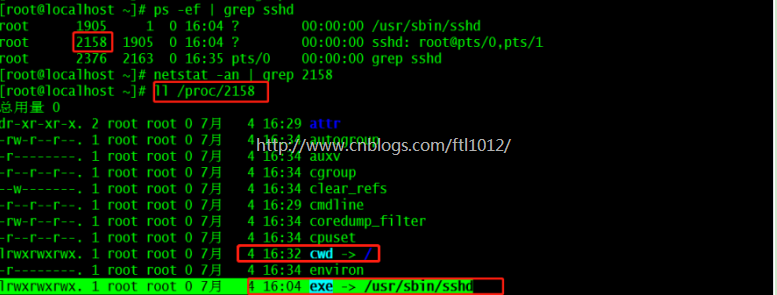
cwd符号链接的是进程运行目录;
exe符号连接就是执行程序的绝对路径;
cmdline就是程序运行时输入的命令行命令;
environ记录了进程运行时的环境变量;
fd目录下是进程打开或使用的文件的符号连接。
lsof -p 2158
