事务管理(ACID)
前言
数据库事务可以被定义为: 一个或者几个数据库允许的操作的集合。这个集合需要支持ACID特性。
在ACID特性中,隔离性(isolation)指的是不同事务在提交的时候,最终呈现出来的效果是串行的,换句话说,既是不同事务,按照提交的先后顺序执行,再换句话说,对于事务本身来说,它所感知的数据库,应该只有它自己在操作。那么最简单的方法,我们按照定义来实现数据库事务的隔离性即可,很明显这在同时并发有多个事务要执行的环境下是没有执行效率的,一个事务的执行,必然会阻塞其他事务的执行。所以SQL的标准制定者对此作出妥协,提出隔离性的四个等级,其中最高级隔离等级才是串行执行。在没有到达串行执行等级的情况下,事务又是并发执行的,总是或多或少会存在问题,这在下面会讲到。
谈到事务一般都是以下四点:
- 原子性(Atomicity)
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
- 一致性(Consistency)
是指应用层系统从一种正确的状态,在事务成功后,达成另一种正确的状态。比如:A、B账面共计100W,A向B转账,加上事务控制,转成功后,他们账户总额应还是100W,事务应保持这种应用逻辑正确一致。还有,转账(事务成功)前后,数据库内部的数据结构--比如账户表的主键、外键、列必须大于0、Btree、双向链表等约束需要是正确的,和原来一致的。
- 隔离性(Isolation)
隔离是指当多个事务提交时,让它们按顺序串行提交,每个时刻只有一个事务提交。但隔离处理并发事务,效率很差。所以SQL标准制作者妥协了,提出了4种事务隔离等级(1,read-uncommited 未提交就读,可能产生脏读 2,read-commited 提交后读 可能产生不可重复读 3,repeatable-read 可重复读 可能产生幻读 4,serializable 序列化,最高级别,按顺序串行提交)
- 持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响
举个简单的例子理解以上四点
原子性(Atomicity)
针对同一个事务
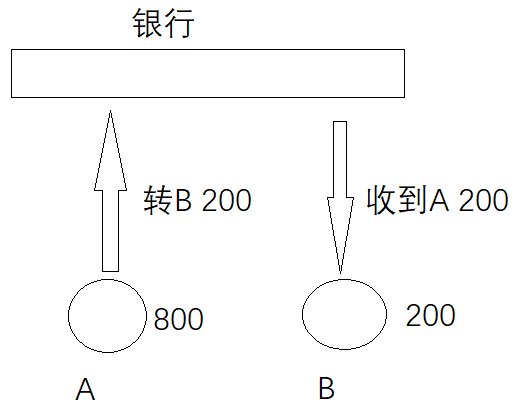
这个过程包含两个步骤
A: 800 - 200 = 600
B: 200 + 200 = 400
原子性表示,这两个步骤一起成功,或者一起失败,不能只发生其中一个动作
一致性(Consistency)
针对一个事务操作前与操作后的状态一致
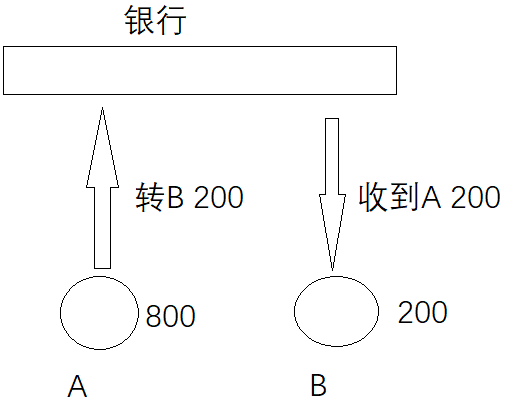
操作前A:800,B:200
操作后A:600,B:400
一致性表示事务完成后,符合逻辑运算
持久性(Durability)
表示事务结束后的数据不随着外界原因导致数据丢失
操作前A:800,B:200
操作后A:600,B:400
如果在操作前(事务还没有提交)服务器宕机或者断电,那么重启数据库以后,数据状态应该为
A:800,B:200
如果在操作后(事务已经提交)服务器宕机或者断电,那么重启数据库以后,数据状态应该为
A:600,B:400
隔离性(Isolation)
针对多个用户同时操作,主要是排除其他事务对本次事务的影响
不同的事务并发操作相同的数据时,每个事务都有各自完成的数据空间,即一个事务内部的操作及使用的数据对其他并发事务时隔离的,并发执行的各个事务之间不能相互干扰。
事务的隔离级别
1.未提交读:(Read Uncommited)
未提交就读,可能产生脏读;
指一个事务读取了另外一个事务未提交的数据。
这个等级是最低等级,也可以认为,事务之间完全不隔离,事务A开始一个事务,接着事务B开始,事务B对数据C继续update,这时候,A读取了B未提交(commit)的数据,这种情况叫做脏读(dirty read)。这个时候要是事务B遇到错误必须rollback,那么A读取的数据就完全是错的。可以想象这样完全不隔离的状态下,我们相对于数据库的业务方程序员写的一个sql,提交个db的执行引擎,返回的结果是多么不可确定啊。
2.提交读:(Read Commited)
提交后读 可能产生不可重复读;
导致不可重复读原因:
B事务在A事务的两次读取之间修改了A事务读取的数据,且A事务采用了低于“可重复读”隔离级别的事务,最终导致同一个事务下面两次读取结果不一样。
按照我们之前所说,我们的目标是:对于一个事务本身来说,它所感知的数据库,应该只有它自己在操作,那么事务A会觉得自己并没有更新数据啊,怎么数据突然变了,再也不能重复读到最开始的那个数据值了,此为不可重复读;
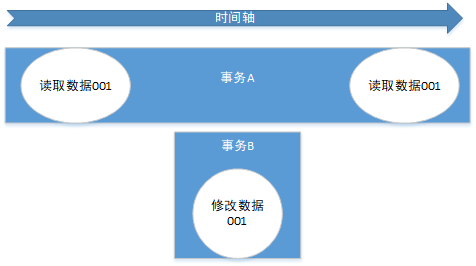
在某些情况下,不可重复读并不是问题,比如我们多次查询某个数据当然以最后查询得到的结果为主。但在另一些情况下就有可能发生问题,例如对于同一个数据A和B依次查询就可能不同,A和B就可能打起来了……
例如:
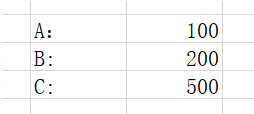
页面统计查询值
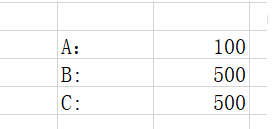
点击生成报表的时候,B有人转账进来300(事务已经提交)
代码演示(spring):
@Transactional(isolation = Isolation.READ_COMMITTED) public Object listForIllusionRead() {//会话1 List<Map<String,Object>> map = jdbcTemplate.queryForList("select * from tao"); try { Thread.sleep(10000);//会话1堵塞 } catch (InterruptedException e) { e.printStackTrace(); } List<Map<String,Object>> map2 = jdbcTemplate.queryForList("select * from tao"); Map<String,Object> res = new HashMap<String, Object>(); res.put("before", map); res.put("after", map2); return res; } public void updateForNoRepeat () {//会话2 jdbcTemplate.execute("update tao set col2 = 'e'"); }
会话1执行→第一次读→会话1sleep阻塞→会话2执行update有效会话操作→会话1第二次读→会话1返回{ "before":[ { "col1":1, "col2":"d" } ], "after":[ { "col1":1, "col2":"e" } ]}
结论:与理论相符,两次读取不一样
3.可重复读:(Repeatable Read)
可重复读 可能产生幻读;
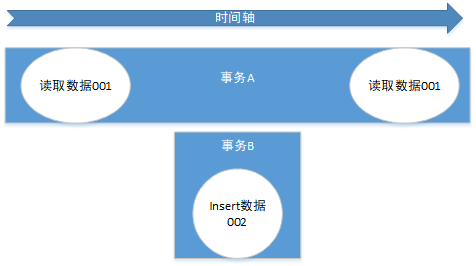
(一般是行影响,多了一行)
可重复读,即是在上一个级别(提交读)的基础上,SQL机制强行让A仍然读之前读到的数据值,保证在一个事务内两次select同一条数据不会出现变化,即是别的事务对你select的对象进行update操作不会影响,这就是可重复读。但是,如果是insert操作,在这个隔离级别还是会受到影响。事务A开启事务,并select一段有范围的数据,然后事务B开启事务,在先前A事务select的那段有范围的数据中insert一条数据,然后提交事务,接着事务A再select出来这段数据,发现数据多了一条,这种情况叫幻读(Phantom Read)
关于幻读的深入学习可以参考:https://www.cnblogs.com/luzhanshi/p/13407465.html
4.串行化:(Serializable)
是最严格的事务隔离级别,它要求所有事务被串行执行,即事务只能一个接一个的进行处理,不能并发执行。
5.隔离性总结
| 设置 | 描述 |
| Serializable | 可避免脏读、不可重复读、虚读情况的发生。(串行化) |
| Repeatable read(可重复读) | 可避免脏读、不可重复读情况的发生。 可能产生幻读; |
| Read committed (提交后读) | 可避免脏读情况发生(读已提交)。 可能产生不可重复读; |
| Read uncommitted (读未提交) | 最低级别,以上情况均无法保证。可能产生脏读; |
以上四种隔离级别最高的是Serializable级别,最低的是Read uncommitted级别,隔离级别越高,越能保证数据的完整性和一致性,但是执行效率就越低,对并发性能的影响也越大。
6.不同数据库隔离级别
MySQL数据库中,支持上面四种隔离级别,默认的为Repeatable read (可重复读);
Oracle数据库中,只支持Serializable (串行化)级别和Read committed (读已提交)这两种级别,其中默认的为Read committed级别。
大多数的数据库默认隔离级别为 Read Commited,比如 SqlServer、Oracle
少数数据库默认隔离级别为:Repeatable Read 比如: MySQL InnoDB
java代码设置隔离级别
如果是使用JDBC对数据库的事务设置隔离级别的话,也应该是在调用Connection对象的setAutoCommit(false)方法之前。调用Connection对象的setTransactionIsolation(level)即可设置当前链接的隔离级别,至于参数level,可以使用Connection对象的字段:
Connection conn=null;
Statement st=null;
ResultSet rs=null;
try{ conn=JdbcUtils.getConnection(); //设置该链接的隔离级别 conn.setTransactionIsolation(Connection.TRANSACTION_SERIALIZABLE);
conn.setAutoCommit(false);//开启事务
Connection字段对应各个级别说明:
| 设置 | 描述 |
| TRANSACTION_NONE | 指示事务不受支持的常量 |
| TRANSACTION_SERIALIZABLE | 指示不可以发生脏读、不可重复读和虚读的常量。 |
| TRANSACTION_REPEATABLE_READ | 指示不可以发生脏读和不可重复读的常量;虚读可以发生。 |
| TRANSACTION_READ_UNCOMMITTED | 指示可以发生脏读 (dirty read)、不可重复读和虚读 (phantom read) 的常量。 |
| TRANSACTION_READ_COMMITTED | 指示不可以发生脏读的常量;不可重复读和虚读可以发生。 |
mysql测试事务隔离性
SELECT @@session.tx_isolation; SELECT @@tx_isolation; SET SESSION TRANSACTION ISOLATION LEVEL read uncommitted; SET SESSION TRANSACTION ISOLATION LEVEL read committed; SET SESSION TRANSACTION ISOLATION LEVEL repeatable read; SET SESSION TRANSACTION ISOLATION LEVEL serializable; start transaction; --建表 drop table AMOUNT; CREATE TABLE `AMOUNT` ( `id` varchar(10) NULL, `money` numeric NULL ) ; --插入数据 insert into amount(id,money) values('A', 800); insert into amount(id,money) values('B', 200); insert into amount(id,money) values('C', 1000); --测试可重复读,插入数据 insert into amount(id,money) values('D', 1000); --设置事务 SET SESSION TRANSACTION ISOLATION LEVEL read uncommitted; SELECT @@tx_isolation; --开启事务 start transaction; --脏读演示,读到其他事务未提交的数据 --案列1,事务一:A向B转200,事务二:查看B金额变化,事务一回滚事务 update amount set money = money - 200 where id = 'A'; update amount set money = money + 200 where id = 'B'; --不可重复读演示,读到了其他事务提交的数据 --案列2,事务一:B向A转200,事务二:B向C转100 SET SESSION TRANSACTION ISOLATION LEVEL read committed; --开启事务 start transaction; --两个事务都查一下数据(转账之前需要,查一下金额是否够满足转账) select * from amount; --事务一:B向A转200 update amount set money = money - 200 where id = 'B'; update amount set money = money + 200 where id = 'A'; commit; --事务二:B向C转100 update amount set money = money - 100 where id = 'B'; update amount set money = money + 100 where id = 'C'; commit; --从事务二的角度来看,读到了事务一提交事务的数据,导致金额出现负数 --幻读演示 --案列3,事务一:B向A转200,事务二:B向C转200转100 SET SESSION TRANSACTION ISOLATION LEVEL repeatable read; --开启事务 start transaction; --两个事务都查一下数据(转账之前需要,查一下金额是否够满足转账) select * from amount; --事务一:B向A转200 update amount set money = money - 200 where id = 'B'; update amount set money = money + 200 where id = 'A'; commit; --事务二:B向C转200转100 update amount set money = money - 100 where id = 'B'; update amount set money = money + 100 where id = 'C'; commit; --从事务二的角度来看,读到了事务一提交事务的数据,导致金额出现负数
- serializable事务二会一直等着事务一提交再操作
补充内容(隔离实现机制)
隔离性的实现
我们知道,如果要实现数据库事务最高隔离性,也就是最安全的隔离性,有个显而易见的实现就是当一个事务在执行的时候,其他全部事务都阻塞,等待这个事务执行完再执行,这在现代多核CPU环境下显然非常浪费计算资源。为了充分利用资源,必须支持并发,这里就涉及并发控制(Concurrency control)
这是一个非常大的主题,关系到数据库,有两个比较重要的方法,一个是用锁(lock),一个是称为多版本并发控制(MVCC)的方法。
通过锁的方式来实现隔离性
读写锁
读写锁的概念很平常,当你在读取数据的时候,应该先加读锁,读取完之后的某个时间再解开读锁,那么加了读锁的数据,应该需要有什么特性呢,应该只能读,不能写,因为加了读锁,说明有事务准备读取这个数据,如果被别的事务重写这个事务,那数据就不准确了。所以一个事务给这个数据加了读锁,别的事务也可以对这个数据加读锁,因为大家都是只读不写。
写锁则具有排他性(exclusive lock),当一个事务准备对一个数据进行写操作的时候,先要对数据加写锁,那么数据就是可变的,这时候,其他事务就无法对这个数据加读锁了,除非这个写锁释放。
两端式提交锁(Two-phase locking)
两段式提交分为两步:
1. 这个阶段只加锁,或者释放锁(读写锁)
2. 这个阶段只会释放锁
下面对应于不同隔离级别对加锁方式进一步分析:
* 未提交读(read uncommitted):这个级别加锁,其实并不需要用两端式加锁,每一个具体操作执行完,锁就可以释放了。
* 提交读(read committed):这个阶段其实也可以按照每个操作执行前加锁,执行之后释放锁的方式。
* 可重复读(repeatable read) : 这个级别,就要求读锁必须,到事务结束前最后时刻才能释放,这样才能保证读取到数据是不可变的,可重复读的。但是这样会阻塞其他事务对加锁的数据的写操作。
* 序列化读(serializable):这个级别要求,两段式提交的第一步,要在事务开始的时候,原子性的把需要的锁全部加好(这显然很难估算,除非很大力度的锁),在事务结束前最后时刻,把全部锁一次性释放。这样做的结果就是使很多数据在事务执行期能都被加锁,无法被其他事务所使用。
使用多版本并发控制(MVCC)
加锁的方式处理事务一个比较大的问题就是会造成死锁(dead lock),原因就是一个事务加锁的数据并不止只有一行。事务A对行C加写锁,事务B对行D加写锁,接着事务希望获取行D的锁,事务B希望获取行C的锁,这样很容就死锁了。
使用MVCC就可以避免很多情况下的加锁操作,使用数据冗余的方式来实现事务隔离(这真是个很好的设计啊)
什么是MVCC
MVCC提供的只是一种思路,具体的实现比较多样化。大体的思路是每一行保存冗余数据,读写的时间戳,也可以称为版本号,在对某一行数据继续update或者delete的时候,并不直接操作,而是复制多一份副本进行操作,这个就是所谓多版本(multiversion)
mysql innodb对于MVCC的实现
innodb对每一行保存两个系统版本号,一个更新操作的版本号,一个删除操作的版本号,这两个版本号的来源是事务的ID(transaction id),也就是说,当某个事务对这一行数据进行update,或者删除的时候,相应会把它的事务ID写入这行数据的更新操作的版本号,删除操作的版本号中。
事务ID是随时间推移而增长,而且不可重复的。一个事务打开之后:
* 对于select操作:每次只会select具有比当前事务ID更小的更新操作版本号的数据,而且这些数据要保证删除版本号为空,或者删除版本号大于当前事务ID。
* 对于update操作:对该行数据复制出一份副本,同时在更新操作版本号写入当前事务ID,同时把当前事务ID写入之前的删除操作的版本号中。
* 对于insert操作:写入新行,同时在更新操作版本号写入当前事务ID
* 对于delete操作:在删除操作版本号写入当前事务ID
mysql官方innodb的实现是用MVCC,官方声称默认的innodb的隔离级别是可重复读。看了不少资料说无法测试出这种级别下的幻读,实际上不对的,只是不能用之前加锁情况下举例的那个例子。用如下方式可以实现幻读:事务A开启,事务B接着开启,事务B select一段数据,接着事务A 在这段数据中间insert一条数据,接着事务B再select一次,就出现幻读了。
mysql官方文档提到串行隔离级别要在原来的基础说对每一个select操作执行[SELECT ... LOCK IN SHARE MODE](13.2.9 SELECT Syntax)
这样就可以读取的数据加读锁了,那么其他试图写入数据都必须阻塞。那么就可以实现序列化串行了。
可重复读,即是在上一个级别的基础上,保证不会在一个事务内两次select同一条数据会出现变化,即是别的事务对你select的对象进行update操作不会影响。但是,如果是insert操作,在这个隔离级别还是会受到影响。事务A开启事务,并select一段有范围的数据,然后事务B开启事务,在先前A事务select的那段有范围的数据中insert一条数据,然后提交事务,接着事务A再select出来这段数据,发现数据多了一条,这种情况叫幻读(Phantom Read)