一、封装spark的处理类
SparkSession:
其为用户提供了一个统一的切入点来使用Spark的各项功能,并且允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序。
SparkSession: SparkSession实质上是SQLContext和HiveContext的组合(未来可能还会加上StreamingContext),所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。
(如果需要支持Hive(HiveContext):enableHiveSupport() )
##创建一个SparkSession
spark=SparkSession.builder .master('spark://master:7077') .appName("just-test") .config("spark.executor.memory", '4g') .getOrCreate()
关于配置SparkConf:
from pyspark import SparkContext, SparkConf from pyspark.sql import SparkSession def create_sc(): sc_conf = SparkConf() sc_conf.setMaster('spark://master:7077') sc_conf.setAppName('my-app') sc_conf.set('spark.executor.memory', '2g') #executor memory是每个节点上占用的内存。每一个节点可使用内存 sc_conf.set("spark.executor.cores", '4') #spark.executor.cores:顾名思义这个参数是用来指定executor的cpu内核个数,分配更多的内核意味着executor并发能力越强,能够同时执行更多的task sc_conf.set('spark.cores.max', 40) #spark.cores.max:为一个application分配的最大cpu核心数,如果没有设置这个值默认为spark.deploy.defaultCores sc_conf.set('spark.logConf', True) #当SparkContext启动时,将有效的SparkConf记录为INFO。 print(sc_conf.getAll()) sc = SparkContext(conf=sc_conf) return sc
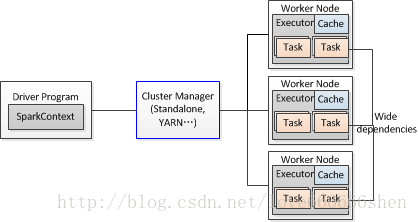
框架图:
addFile(path, recursive=False)
把文件分发到集群中每个worker节点,然后worker会把文件存放在临时目录下,spark的driver和executor可以通过pyspark.SparkFiles.get()方法来获取文件的路径,从而能够保证driver和每个worker都能正确访问到文件。因此,比较适合用于文件比较小,但是每个worker节点都需要访问的情况,文件比较大的情况下网络传送的消耗时间会比较长。
path:可以是单个本地文件,HDFS文件,或者HTTP地址,HTTPS地址,FTP URI。要在spark job中获取文件,使用pyspark.SparkFiles.get(filename),通过指定文件名filename获取文件路径。
>>> from pyspark import SparkFiles >>> path = os.path.join(tempdir, "test.txt") >>> sc.addFile(path) >>> res_rdd = sc.textFile(SparkFiles.get(path))
addPyFile(path)
为SparkContext上执行的所有任务增加.py或者.zip文件依赖。path可以是本地文件,HDFS文件,或者HTTP地址,HTTPS地址,FTP URI。
程序示例:
from pyspark.sql import SparkSession from pyspark import HiveContext import os import datetime class sparkTask: def __init__(self, app_name="pickup_scene_order"): self.ss = SparkSession.builder.appName("hankaiming_" + app_name) .config("spark.dynamicAllocation.enabled", "true") .config("spark.dynamicAllocation.maxExecutors", 150) .enableHiveSupport() .config("spark.executor.cores", 2) .config("spark.executor.memory", "13g") .getOrCreate() self._addPyFile() print "current time: %s" % str(datetime.datetime.now()) def getSparkContext(self): return self.ss.sparkContext def getHiveContext(self): return HiveContext(self.getSparkContext()) def getSparkSession(self): return self.ss def _addPyFile(self): current_path = os.getcwd() current_file_name = os.getcwd().split("/")[-1] while current_file_name != "pickup_log_order" : current_path = os.path.abspath(os.path.join(current_path, "..")) print current_path if current_file_name == "": raise Exception("project file name error : %s" % "pickup_log_order") current_file_name = current_path.split("/")[-1] self._sendFilesUnderPath(self.getSparkContext(), current_path) return def _sendFileToSpark(self, sc, path): if path.endswith('.py') or path.endswith('-remote') or path.endswith('.ini'): sc.addPyFile(path) print 'spark add file : %s' % path.split("/", 4)[-1] return def _sendFilesUnderPath(self, sc, root): if os.path.isfile(root): self._sendFileToSpark(sc, root) return if os.path.isdir(root): path_list = os.listdir(root) for path in path_list: if path in ["pickup_recommend", "pickup_recall"]: continue path = os.path.join(root, path) self._sendFilesUnderPath(sc, path) return def stop(self): print "stop time: %s" % str(datetime.datetime.now()) self.getSparkSession().stop()
# /usr/bin/env python # encoding=utf-8 import sys sys.path.append('./utils') sys.path.append('./gen-py') from spark_utils import sparkTask import logger_utils from conf_utils import DataConf #从py文件conf_utils.py里面引入了DataConf类 import date_utils import macro_utils as macro from point_utils import Point import json import time import gc import requests import sys import redis reload(sys) sys.setdefaultencoding("utf-8") purging_logger = logger_utils.Logger().logger def trans_pid(pid): return pid | 1 << 48 class orderPurging: def __init__(self, st, start_date, end_date, country_code): self.st = st self.start_date = start_date self.end_date = end_date self.country_code = country_code def loadOrder(self, order_path): #处理下要生成的数据格式 内部函数 def parse_line(info): #如果订单起点与计费点距离 < 30m,返回none,代表丢弃掉 Point.getSphericalDistanceOnFloat distance_cal = Point(1,1) distance_rsp = distance_cal.getSphericalDistanceOnFloat(info.starting_lng, info.starting_lat, info.begun_lng, info.begun_lat) if distance_rsp > 30: return None order_id = str(info.order_id) call_time = info.a_birth_time starting_pos = ",".join([str(info.starting_lng), str(info.starting_lat)]) origin_aboard_pos = ",".join([str(info.begun_lng), str(info.begun_lat)]) passenger_id = str(trans_pid(int(str(info.passenger_id)))) start_poi_id = info.starting_poi_id country_code = info.country_code #(passenger_id, start_poi_id) 用户id+起点id作为key return (passenger_id, start_poi_id), (order_id, call_time, starting_pos, origin_aboard_pos, country_code) def formatJson(line): (passenger_id, start_poi_id), (order_id, call_time, starting_pos, origin_aboard_pos, country_code) = line rt = json.loads("{}") rt["key"] = "_".join([passenger_id, start_poi_id]) rt["value"] = "1" return json.dumps(rt, ensure_ascii=False, sort_keys=True) #需要从hive表提取的字段 table_fields = [ "order_id", "passenger_id", "starting_lng", "starting_lat", "a_birth_time", "begun_lng", "begun_lat", "starting_poi_id", "dt", "country_code" ] #hive表执行sql sql = ( "select %s from %s " "where dt BETWEEN %s and %s " "and is_carpool=0 and is_td_finish=1 and country_code = '%s'" ) % (",".join(table_fields), order_path, self.start_date, self.end_date, self.country_code) #跑spark任务,订单起点与计费点距离 < 30m,该用户的订单起点有重复poi_id的,只取最新的那个 #(ele[1]代表用value第二个字段,也就是按照call_time进行升序排序)(-1代表升序后取最后一个) order_rdd = self.st.getHiveContext().sql(sql).rdd.map(parse_line).filter(lambda x: x is not None).groupByKey() .mapValues(lambda a: sorted(list(a), key=lambda ele: ele[1])[-1]).map(formatJson) purging_logger.info("order_rdd.count: %d" % order_rdd.count()) #数据文件中每一行都是一个json字符串,需要转成{"value":"1","key": "passenger_id_start_poi_id"} return order_rdd def runJob(self, output_path, country_code): #hive表名称 order_path = "map_bi.dwd_intl_order_tablename" #获取到了spark从hive表中生产好的的弹性分布式数据集rdd order_rdd = self.loadOrder(order_path) #打印日志 print "after map order_rdd: %d" % order_rdd.count() print "order_rdd.first: %s" % str(order_rdd.first()) purging_logger.info("after map order_rdd count is %d" % order_rdd.count()) purging_logger.info("order_rdd.first is %s" % str(order_rdd.first())) pid_count = order_rdd.count() if pid_count > 0: #生成需要存储的hdfs地址 sample_output_path_prefix = "/user/prod_international_map/map-arch/qiujinhan/poi_api" output_path = "/".join([sample_output_path_prefix, country_code, self.end_date]) tmp_count = order_rdd.count() purging_logger.info("%s count: %d, path: %s" % (country_code, tmp_count, output_path)) #最后的数据,存储到hdfs地址上 order_rdd.repartition(100).saveAsTextFile(output_path) return def main(): spark = sparkTask() todyDate = date_utils.getNowDate() #取最近三十天的数据 start_date = date_utils.getDateByDelta(todyDate, -3) end_date = date_utils.getDateByDelta(todyDate, -1) #存在到hdfs的地址 output_path = "/user/prod_international_map/map-arch/XXX/poi_api/" + start_date +"_"+ end_date print start_date print end_date print output_path #需要跑的6个国家 country_codes = "JP;MX;AU;CL;CO;BR" #打印一些日志 purging_logger.info("= * 30") purging_logger.info("start_date = %s" % start_date) purging_logger.info("end_date = %s" % end_date) purging_logger.info("country_codes = %s" % country_codes) purging_logger.info("output_path = %s" % output_path) purging_logger.info("=" * 30) #对6个国家循环的取spark跑数据 country_list = country_codes.split(";") for country_code in country_list: purging_logger.info("begin country %s ,start_date=%s, end_date=%s " % (str(country_code), start_date, end_date)) #去orderPurging类的runJob函数进行处理 purging_process = orderPurging(spark, start_date, end_date, country_code) purging_process.runJob(output_path, country_code) purging_logger.info("end country %s group,start_date=%s, end_date=%s " % (str(country_code), start_date, end_date)) spark.stop() #当哪个py文件被直接执行时,该py文件的“__name__”的值就是“__main__”,if下面的代码块就会被执行 if __name__ == "__main__": main()