参考自:https://blog.csdn.net/lcx543576178/article/details/45892839
程序稍作修改,如下:
#include<iostream> using namespace std; #include<mpi.h> int main(int argc, char * argv[] ){ double start, stop; int *a, *b, *c, *buffer, *ans; int size = 1000; int rank, numprocs, line; MPI_Init(NULL,NULL); MPI_Comm_rank(MPI_COMM_WORLD, &rank); MPI_Comm_size(MPI_COMM_WORLD, &numprocs); line = size/numprocs; b = new int [ size * size ]; ans = new int [ size * line ]; start = MPI_Wtime(); if( rank ==0 ){ a = new int [ size * size ]; c = new int [ size * size ]; for(int i=0;i<size; i++) for(int j=0;j<size; j++){ a[ i*size + j ] = i*j; b[ i*size + j ] = i + j; } for(int i=1;i<numprocs;i++){// send b MPI_Send( b, size*size, MPI_INT, i, 0, MPI_COMM_WORLD ); } for(int i=1;i<numprocs;i++){// send part of a MPI_Send( a + (i-1)*line*size, size*line, MPI_INT, i, 1, MPI_COMM_WORLD); } for(int i = (numprocs-1)*line;i<size;i++){// calculate block 1 for(int j=0;j<size;j++){ int temp = 0; for(int k=0;k<size;k++) temp += a[i*size+k]*b[k*size+j]; c[i*size+j] = temp; } } for(int k=1;k<numprocs;k++){// recieve ans MPI_Recv( ans, line*size, MPI_INT, k, 3, MPI_COMM_WORLD, MPI_STATUS_IGNORE); for(int i=0;i<line;i++){ for(int j=0;j<size;j++){ c[ ((k-1)*line + i)*size + j] = ans[i*size+j]; } } } FILE *fp = fopen("c.txt","w"); for(int i=0;i<size;i++){ for(int j=0;j<size;j++) fprintf(fp,"%d ",c[i*size+j]); fputc(' ',fp); } fclose(fp); stop = MPI_Wtime(); printf("rank:%d time:%lfs ",rank,stop-start); delete [] a,c; } else{ buffer = new int [ size * line ]; MPI_Recv(b, size*size, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE); MPI_Recv(buffer, size*line, MPI_INT, 0, 1, MPI_COMM_WORLD, MPI_STATUS_IGNORE); for(int i=0;i<line;i++) for(int j=0;j<size;j++){ int temp=0; for(int k=0;k<size;k++) temp += buffer[i*size+k]*b[k*size+j]; ans[i*size+j] = temp; } MPI_Send(ans, line*size, MPI_INT, 0, 3, MPI_COMM_WORLD); delete [] buffer; delete [] ans; } delete [] b; MPI_Finalize(); return 0; }
线程 0 发送矩阵 b,以及 a 的分块矩阵给其他线程,然后自己做一部分矩阵乘法,然后接收其他线程的结果,然后输出最终答案。
2. 用 MPI_Scatter 和 MPI_Gather,代码同样参考自 https://blog.csdn.net/lcx543576178/article/details/45892839
稍作修改,如下:
#include<iostream> using namespace std; #include<mpi.h> int main(){ int my_rank; int num_procs; int size = 1000; double start, finish; MPI_Init(NULL,NULL); MPI_Comm_rank(MPI_COMM_WORLD, &my_rank); MPI_Comm_size(MPI_COMM_WORLD, &num_procs); int line = size / num_procs; cout<<" line = "<<line<<endl; int * local_a = new int [ line * size ]; int * b = new int [ size * size ]; int * ans = new int [ line * size ]; int * a = new int [ size * size ]; int * c = new int [ size * size ]; if( my_rank == 0 ){ start = MPI_Wtime(); for(int i=0;i<size;i++){ for(int j=0;j<size;j++){ a[ i*size + j ] = i*j; b[ i*size + j ] = i + j; } } MPI_Scatter(a, line * size, MPI_INT, local_a, line * size, MPI_INT, 0, MPI_COMM_WORLD ); MPI_Bcast(b, size*size, MPI_INT, 0, MPI_COMM_WORLD); for(int i= 0; i< line;i++){ for(int j=0;j<size;j++){ int temp = 0; for(int k=0;k<size;k++) temp += a[i*size+k] * b[k*size + j]; ans[i*size + j ] = temp; } } MPI_Gather( ans, line * size, MPI_INT, c, line * size, MPI_INT, 0, MPI_COMM_WORLD ); for(int i= num_procs *line; i< size;i++){ for(int j=0;j<size;j++){ int temp = 0; for(int k=0;k<size;k++) temp += a[i*size+k] * b[k*size + j]; c[i*size + j ] = temp; } } FILE *fp = fopen("c2.txt","w"); for(int i=0;i<size;i++){ for(int j=0;j<size;j++) fprintf(fp,"%d ",c[i*size+j]); fputc(' ',fp); } fclose(fp); finish = MPI_Wtime(); printf(" time: %lf s ", finish - start ); } else{ int * buffer = new int [ size * line ]; MPI_Scatter(a, line * size, MPI_INT, buffer, line * size, MPI_INT, 0, MPI_COMM_WORLD ); MPI_Bcast( b, size * size, MPI_INT, 0, MPI_COMM_WORLD ); /* cout<<" b:"<<endl; for(int i=0;i<size;i++){ for(int j=0;j<size;j++){ cout<<b[i*size + j]<<","; } cout<<endl; } */ for(int i=0;i<line;i++){ for(int j=0;j<size;j++){ int temp = 0; for(int k=0;k<size;k++) temp += buffer[i*size+k] * b[k*size + j]; //cout<<"i = "<<i<<" j= "<<j<<" temp = "<<temp<<endl; ans[i*size + j] = temp; } } /* cout<<" ans:"<<endl; for(int i=0;i<line;i++){ for(int j=0;j<size;j++){ cout<<ans[i*size + j]<<","; } cout<<endl; } */ MPI_Gather(ans, line*size, MPI_INT, c, line*size, MPI_INT, 0, MPI_COMM_WORLD ); delete [] buffer; } delete [] a, local_a, b, ans, c; MPI_Finalize(); return 0; }
进程 0 向所有进程(包括自己)分发(MPI_Scatter)a 矩阵的各个分块矩阵,并广播(MPI_Bcast)b 矩阵。其他进程接收 a 的分块矩阵与 b 矩阵,做乘法,并返回结果(MPI_Gather)。进程 0 收集所有结果(包括自己的)(MPI_Gather),如果 a 矩阵分块有剩余,进程 0 就做掉相关乘法,最后输出所有结果。
3. 测时间。下图为上面两种方法的耗时,
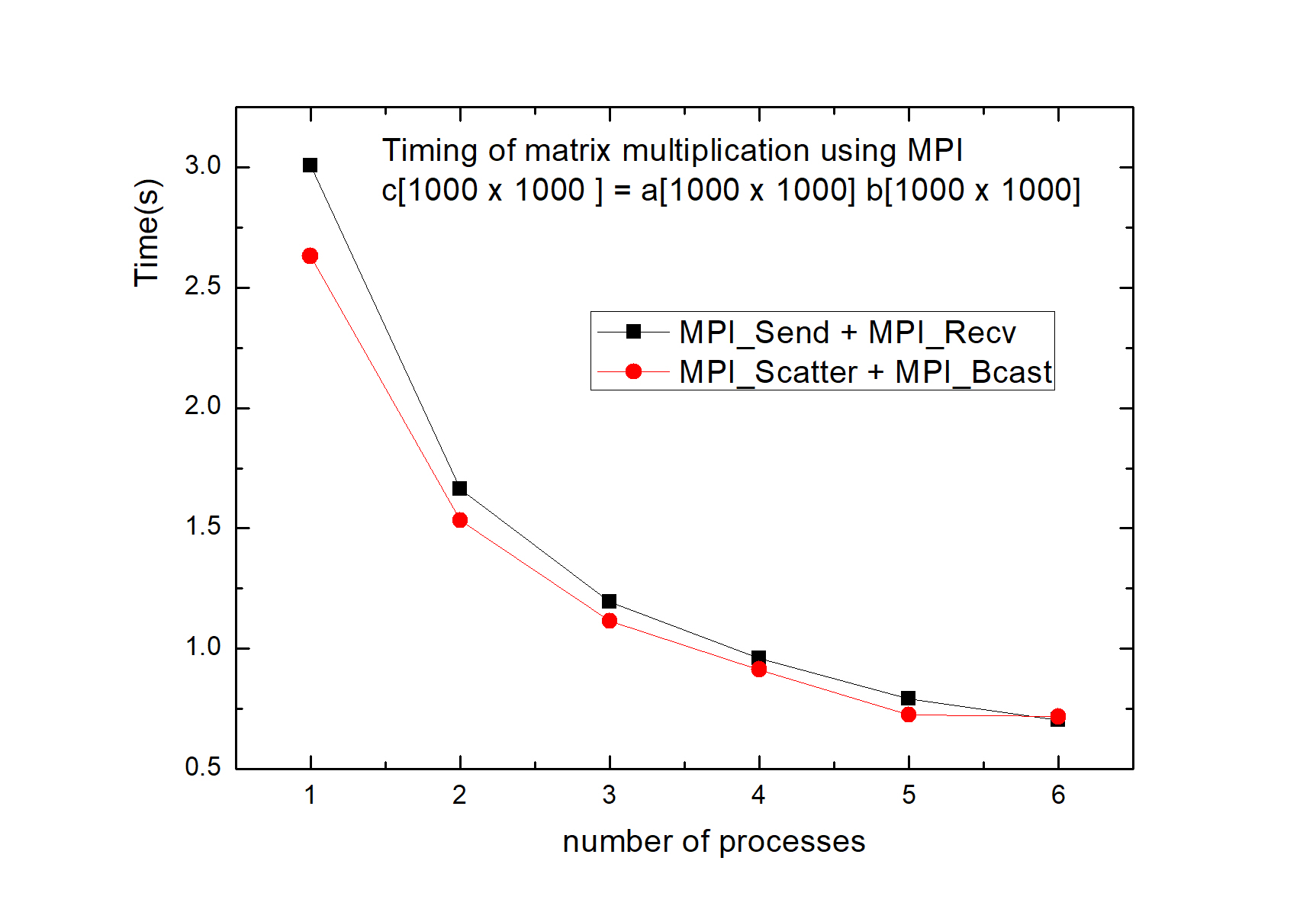
4. 总结:①确实进程越多,耗时越少。
②由于消息传递需要成本,而且不是每个进程都同时开始和结束,所以随着进程数的上升,平均每进程的效率下降。