文章作者:luxianghao
文章来源:http://www.cnblogs.com/luxianghao/p/9010748.html 转载请注明,谢谢合作。
免责声明:文章内容仅代表个人观点,如有不当,欢迎指正。
---
一 引言
2016年2月Google宣布将Beam(原名Google DataFlow)贡献给Apache基金会孵化,成为Apache的一个顶级开源项目。
Beam是一个统一的编程框架,支持批处理和流处理,并可以将用Beam编程模型构造出来的程序,在多个计算引擎(Apache Apex, Apache Flink, Apache Spark, Google Cloud Dataflow等)上运行。
大数据起源于Google 2003年发布的三篇论文GoogleFS、MapReduce、BigTable,史称三驾马车,可惜Google在发布论文后并没有公布其源码,但是Apache开源社区蓬勃发展,先后出现了Hadoop,Spark,Apache Flink等产品,而Google内部则使用着闭源的BigTable、Spanner、Millwheel,但他们殊途同归,这次Google没有发一篇论文后便销声匿迹,而是高调的开源了Beam,所谓“一流公司定标准”,开源的好处也是相当的多,如提高公司影响力,集思广益,共同维护等。
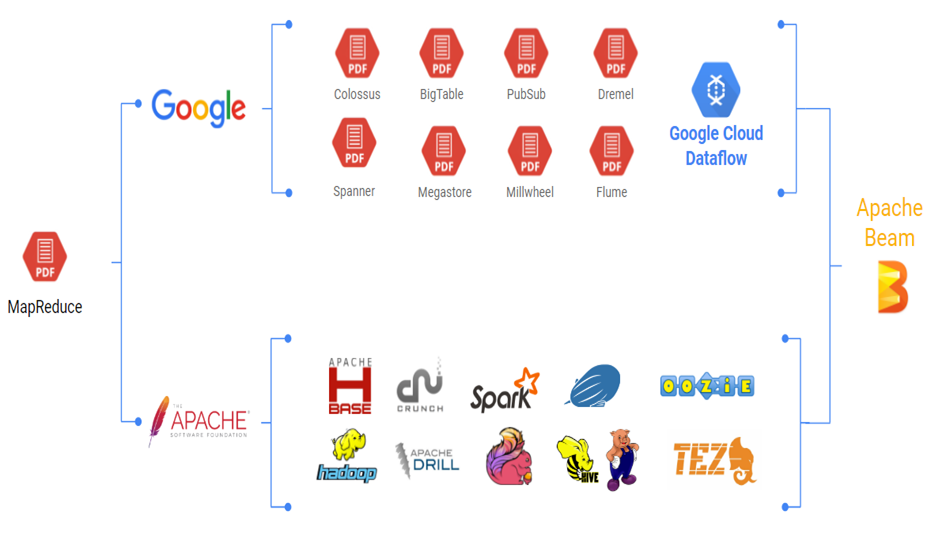
二 Beam优势
1 统一
Beam提供统一的编程模型,编程指导可以参考官方的programming-guide ,通过quickstart-java和wordcount-example入门。
2 可移植
编程人员coding的时候基本不需要关注将来代码会运行到Spark、Flink或者其他计算平台上,coding完成后再通过命令行选择计算平台。
3 可扩展
如在2 可移植中所写,已经展示了DirectRunner和SparkRunner,在Beam中,Runner,IO链接器,转换操作库,甚至SDK都是可以自己定制的,具有高度的扩展性。
4 支持批处理和流处理
不管将来编程人员用Beam写的程序是用于批处理还是流处理,用于有限的数据集还是无限的数据集,用Beam写的程序都可以不修改的执行。(Beam通过引入triggering,windows的概念来解决这个问题)
5 高度抽象
Beam用DAG(directed acyclic graph)进行了高度的抽象,编程人员不需要将其代码强制构造成Map-Shuffle-Reduce的形式,可以直接进行更高级别的操作,如counting, joining, projecting。
6 多语言支持
目前官方支持了Java和Python,后面会有更多语言的SDK开发出来
三 Beam构成
先来一个整体框架图
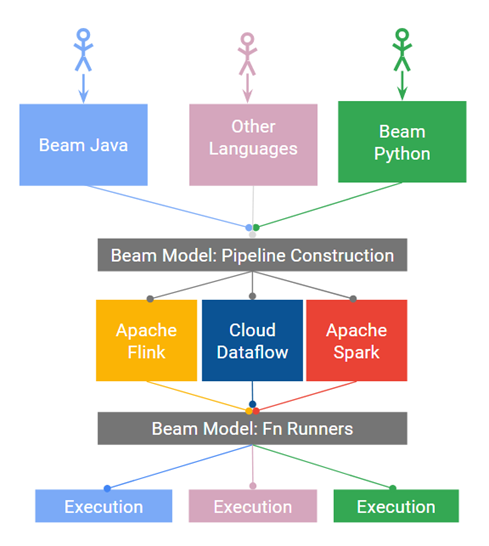
1 Beam编程模型
Beam的编程模型是Google的工程师从MapReduce, FlumeJava, 和Millwheel等多个大数据处理项目中抽象出来的,如果想详细了解可以参考相关的报考和论文,Streaming 101,Streaming 102 和VLDB 2015 paper.。这个编程模型主要包括如下几个核心概念:
- PCollection:数据集,代表了将要被处理的数据集合,可以是有限的数据集,也可以是无限的数据流。
- PTransform:计算过程,代表了将输入数据集处理成输出数据集中间的计算过程,
- Pipeline:管道,代表了处理数据的执行任务,可视作一个有向无环图(DAG),PCollections是节点,Transforms是边。
- PipelineRunner:执行器,指定了Pipeline将要在哪里,怎样的运行。
其中PTransform还包括很多操作,如:
- ParDo:通用的并行处理的PTranform, 相当于Map/Shuffle/Reduce-style 中的Map,可用于过滤 、类型转换 、抽取部分数据 、 对数据中的每一个元素做计算等
- GroupByKey:用来聚合key/value对,相当于Map/Shuffle/Reduce-style中的Shuffle, 聚合那些拥有同一个key的value
- CoGroupByKey:用来聚合多个集合,功能和GroupByKey类似
- Combine:处理集合里的数据,如sum, min, and max(sdk预定义),也可以自建新类
- Flatten:用来把多个数据集合并成一个数据集
- Partition:用来把一个数据集分割成多个小数据集
此外还有一些核心概念,如:
- Windowing:把PCollections数据集中元素通过时间戳分成多个子集
- Watermark:标记了多久时间后的延迟数据直接抛弃
- Triggers:用来决定什么时候发送每个window的聚合结果
Beam的编程模型可简单概括为
[Output PCollection] = [Input PCollection].apply([Transform])

Google工程师还把做Beam编程时的场景抽象成四个问题,就是WWWH

即做什么计算,对应的抽象概念为PTransform

即在哪个时间范围内计算,对应的抽象概念为Window

即在何时输出计算结果,对应的抽象概念为Watermarks和Triggers

即怎么提取相关的数据,对应的抽象概念为Accumulation
备注:此处的翻译是参考Streaming 102得来的,可能单纯按照字面翻译并不能达到预期的效果,如有不合适的地方欢迎指正。
2 SDK
Beam支持用多种语言的SDK来构造Pipeline,当前已经支持Java和Python,相对而言,对Java的SDK支持会更好一些。
3 Runner
Beam支持将Pipeline运行在多个分布式后端,目前支持如下的PipelineRunners:
- DirectRunner: 在本地执行Pipeline
- ApexRunner:在Yarn集群(或者用embeded模式)上运行Pipeline
- DataflowRunner:在Google Cloud Dataflow上运行Pipleine
- FlinkRunner:在Flink集群上运行Pipeline
- SparkRunner:在Spark集群上运行Pipeline
- MRRunner:目前在Beam的github主分支上还没提供,不过有mr-runner分支,具体还可参考BEAM-165
四 例子
通过官方的wordcount的例子来实际体验下Beam,详细可参考quickstart-java和wordcount-example。
1 获取相关代码
mvn archetype:generate -DarchetypeGroupId=org.apache.beam -DarchetypeArtifactId=beam-sdks-java-maven-archetypes-examples -DarchetypeVersion=2.1.0 -DgroupId=org.example -DartifactId=word-count-beam -Dversion="0.1" -Dpackage=org.apache.beam.examples -DinteractiveMode=false
2 相关文件
$ cd word-count-beam/ $ ls pom.xml src $ ls src/main/java/org/apache/beam/examples/ DebuggingWordCount.java WindowedWordCount.java common MinimalWordCount.java WordCount.java
3 使用DrectRunner执行
mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount -Dexec.args="--inputFile=pom.xml --output=counts" -Pdirect-runner -Xdebug
4 提交到Spark
方式1
mvn compile exec:java -Dexec.mainClass=org.apache.beam.examples.WordCount -Dexec.args="--runner=SparkRunner --inputFile=pom.xml --output=counts" -Pspark-runner
方式2
spark-submit --class org.apache.beam.examples.WordCount --master local target/word-count-beam-bundled-0.1.jar --runner=SparkRunner --inputFile=pom.xml --output=counts
方式3
spark-submit --class org.apache.beam.examples.WordCount --master yarn --deploy-mode cluster word-count-beam-bundled-0.1.jar --runner=SparkRunner --inputFile=/home/yarn/software/java/LICENSE --output=/tmp/counts
SparkRunner详情参考这里,其中方式3读取HDFS文件的时候会有些问题,这个问题我们在这里会讲到,上面的例子里可以写物理机上实际存在的文件,这样可以保证相关程序正常运行。
五 参考资料
编程指南 https://beam.apache.org/documentation/programming-guide
例子 https://beam.apache.org/get-started/wordcount-example/
Javadoc https://beam.apache.org/documentation/sdks/javadoc/2.1.0/
streaming-101 https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-101
streaming-102 https://www.oreilly.com/ideas/the-world-beyond-batch-streaming-102