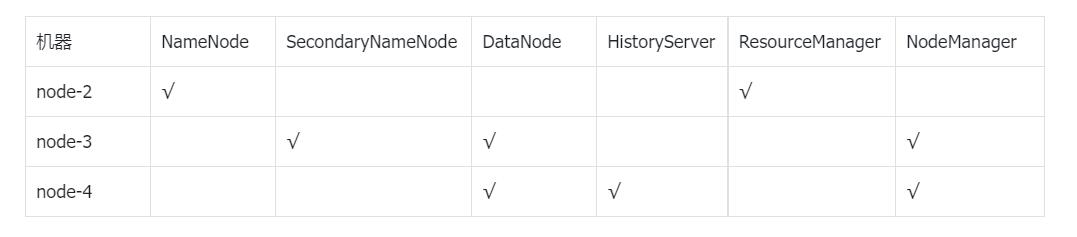
机器规划
环境准备
安装JDK
1. 在所有机器上安装jdk8
2. 配置好环境变量
vi /etc/profile
JAVA_HOME=/usr/local/jdk1.8.0_152
PATH=$PATH:$JAVA_HOME/bin
export JAVA_HOME
export PATH
source /etc/profile
配置免密登录
1)首先在node-2机器上操作
2)生成密钥对 ssh-keygen -t rsa
3)进入/root/.ssh目录,将公钥复制到其他机器
ssh-copy-id node-2
ssh-copy-id node-3
ssh-copy-id node-4
4) 在node-3和snode-4上分别执行上述步骤
关闭防火墙和selinux
1)关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
2)关闭selinux
vi /etc/selinux/config 设置SELINUX=disabled
3)重启系统 reboot
4)在每台机器执行上述操作
安装Hadoop
1.创建目录,在node-2、node-3、node-4上创建下述目录
/mnt/data/hadoop/pid
/mnt/data/hadoop/tmp
/mnt/data/hadoop/dfs/name
/mnt/data/hadoop/dfs/data
/mnt/data/hadoop/dfs/namesecondary
/mnt/data/hadoop/dfs/edits
/mnt/data/hadoop/logs
2.将 hadoop-3.2.2.tar.gz解压到 /opt/software/hadoop-3.2.2
3.配置Hadoop环境变量, 在node-2、node-3、node-4上分别执行下述配置
vi /etc/profile 追加以下内容
HADOOP_HOME=/opt/software/hadoop-3.2.2
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
HADOOP_CLASSPATH=`hadoop classpath`
PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_CONF_DIR
export HADOOP_CLASSPATH
export HADOOP_HOME
export PATH
使配置生效 source /etc/profile
4.配置hadoop-env.sh
export JAVA_HOME=/opt/software/jdk1.8.0_152
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_PID_DIR=/mnt/data/hadoop/pid
export HADOOP_LOG_DIR=/mnt/data/hadoop/logs
5.配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node-2:9870</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/data/hadoop/tmp</value>
</property>
</configuration>
6.配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node-3:9868</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/mnt/data/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/mnt/data/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>/mnt/data/hadoop/dfs/namesecondary</value>
</property>
<property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>/mnt/data/hadoop/dfs/edits</value>
</property>
<property>
<name>dfs.datanode.handler.count</name>
<value>30</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>30</value>
</property>
</configuration>
7.配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
8.配置yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node-2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node-2:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node-2:8032</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://node-4:19888/jobhistory/logs</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/yarn</value>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir-suffix</name>
<value>logs</value>
</property>
</configuration>
9.配置workers
vi workers
node-3
node-4
10.配置log4j.properties
hadoop.log.dir=/mnt/data/hadoop/logs
11.复制 /opt/software/hadoop-3.2.2 到node-3和node-4
scp -r /opt/software/hadoop-3.2.2 root@node-3:/opt/software/hadoop-3.2.2
scp -r /opt/software/hadoop-3.2.2 root@node-4:/opt/software/hadoop-3.2.2
格式化和启动Hadoop
1.格式化,在node-2上执行
bin/hdfs namenode -format
2.启动hdfs, 在node-2上执行
sbin/start-dfs.sh
停止命令:sbin/stop-dfs.sh
3.启动yarn, 在node-2上执行
sbin/start-yarn.sh
停止命令:sbin/stop-yarn.sh
- 启动jobhistory,在node-4上执行
bin/mapred --daemon start historyserver
停止命令:bin/mapred --daemon stop historyserver
页面访问
-
HDFS NameNode: http://node-2:9870/
-
YARN ResourceManager: http://node-2:8088/
-
MapReduce JobHistory Server: http://node-4:19888/