
我的博客:https://www.luozhiyun.com/archives/215
context.Context类型
Context类型可以提供一类代表上下文的值。此类值是并发安全的,也就是说它可以被传播给多个 goroutine。
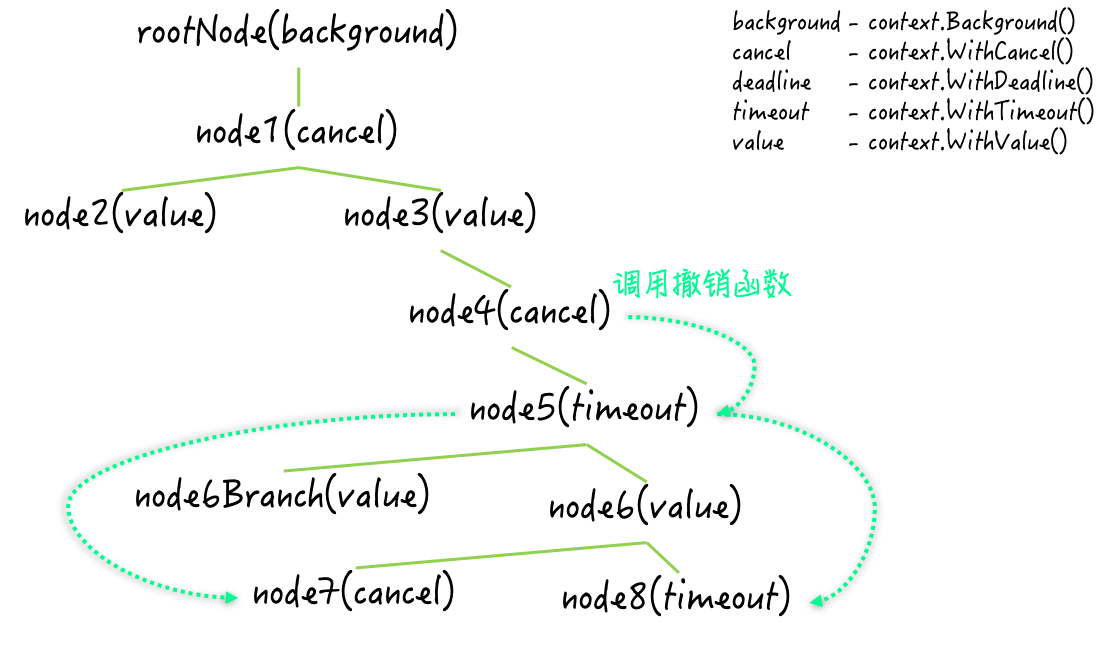
Context类型的值(以下简称Context值)是可以繁衍的,这意味着我们可以通过一个Context值产生出任意个子值。这些子值可以携带其父值的属性和数据,也可以响应我们通过其父值传达的信号。
context包中还包含了四个用于繁衍Context值的函数,即:WithCancel、WithDeadline、WithTimeout和WithValue。
所有的Context值共同构成了一颗代表了上下文全貌的树形结构。通过调用context.Background函数就可以得到上下文根节点,然后通过根节点可以产生子节点。如下:
rootNode := context.Background()
node1, cancelFunc1 := context.WithCancel(rootNode)
在上面的例子中,初始化了一个撤销节点,这个节点是可以给它所有子节点发送撤销信号的,如下:
cxt, cancelFunc := context.WithCancel(context.Background())
//发送撤销信号
cancelFunc()
//接受撤销信号
<-cxt.Done()
在撤销函数被调用之后,对应的Context值会先关闭它内部的接收通道,也就是它的Done方法会返回的那个通道。
然后,它会向它的所有子值(或者说子节点)传达撤销信号。这些子值会如法炮制,把撤销信号继续传播下去。最后,这个Context值会断开它与其父值之间的关联。
WithValue携带数据
WithValue函数在产生新的Context值(以下简称含数据的Context值)的时候需要三个参数,即:父值、键和值。
在我们调用含数据的Context值的Value方法时,它会先判断给定的键,是否与当前值中存储的键相等,如果相等就把该值中存储的值直接返回,否则就到其父值中继续查找。
如:
node2 := context.WithValue(node1, 20, values[0])
node3 := context.WithValue(node2, 30, values[1])
fmt.Printf("The value of the key %v found in the node3: %v
",
keys[0], node3.Value(keys[0]))
fmt.Printf("The value of the key %v found in the node3: %v
",
keys[1], node3.Value(keys[1]))
fmt.Printf("The value of the key %v found in the node3: %v
",
keys[2], node3.Value(keys[2]))
fmt.Println()
最后,提醒一下,Context接口并没有提供改变数据的方法。
对象池sync.Pool
sync.Pool类型只有两个方法——Put和Get。Put 用于在当前的池中存放临时对象,它接受一个interface{}类型的参数;Get方法可能会从当前的池中删除掉任何一个值,然后把这个值作为结果返回。如果没有那么会使用当前池的New字段创建一个新值,并直接将其返回。
如下:
var ppFree = sync.Pool{
New: func() interface{} { return new(pp) },
}
Go 语言运行时系统中的垃圾回收器,所以在每次开始执行之前,都会对所有已创建的临时对象池中的值进行全面地清除。
临时对象池数据结构
在临时对象池中,有一个多层的数据结构。这个数据结构的顶层,我们可以称之为本地池列表。
在本地池列表中的每个本地池都包含了三个字段(或者说组件),它们是:存储私有临时对象的字段private、代表了共享临时对象列表的字段shared,以及一个sync.Mutex类型的嵌入字段。
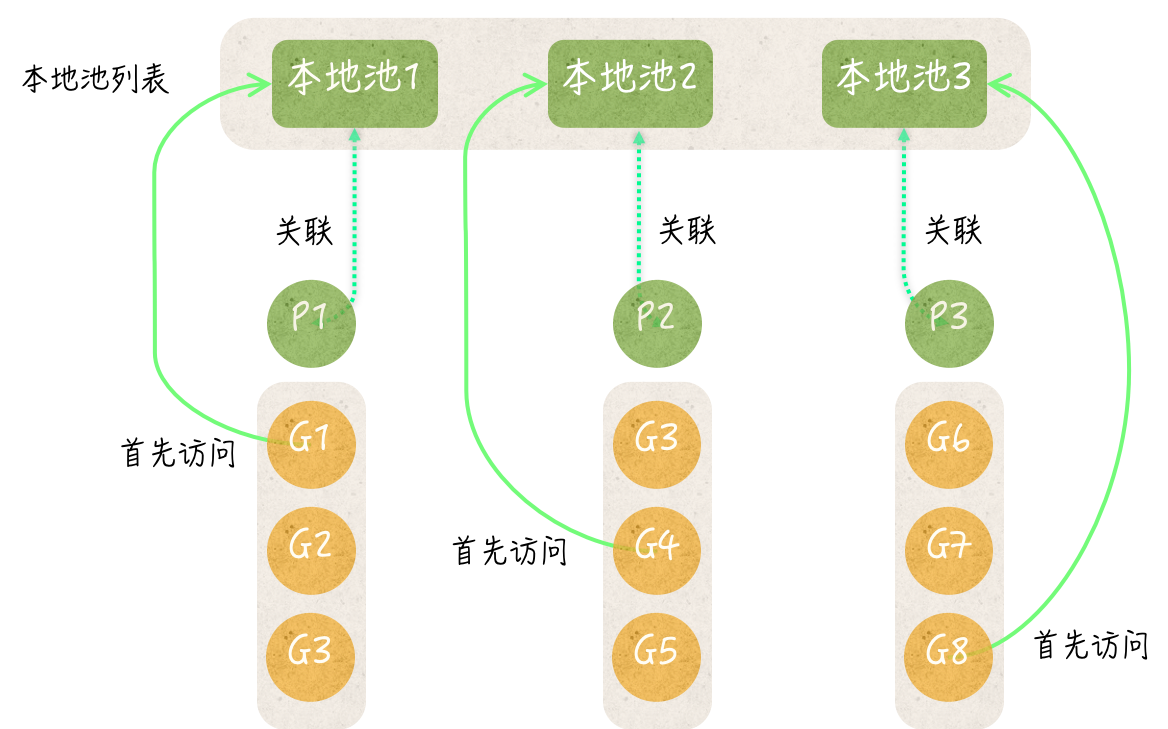
临时对象池的Put方法总会先试图把新的临时对象,存储到对应的本地池的private字段中,只有当这个private字段已经存有某个值时,该方法才会去访问本地池的shared字段。
Put方法会在互斥锁的保护下,把新的临时对象追加到共享临时对象列表的末尾。
临时对象池的Get方法,总会先试图从对应的本地池的private字段处获取一个临时对象。只有当这个private字段的值为nil时,它才会去访问本地池的shared字段。
Get方法也会在互斥锁的保护下,试图把该共享临时对象列表中的最后一个元素值取出并作为结果。
并发安全字典sync.Map
键的实际类型不能是函数类型、字典类型和切片类型。由于这些键值的实际类型只有在程序运行期间才能够确定,所以 Go 语言编译器是无法在编译期对它们进行检查的,不正确的键值实际类型肯定会引发 panic。
也是因为Go没有类似java的泛型,所以我们通常要自己做类型限制,如下:
type IntStrMap struct {
m sync.Map
}
func (iMap *IntStrMap) Delete(key int) {
iMap.m.Delete(key)
}
func (iMap *IntStrMap) Load(key int) (value string, ok bool) {
v, ok := iMap.m.Load(key)
if v != nil {
value = v.(string)
}
return
}
func (iMap *IntStrMap) LoadOrStore(key int, value string) (actual string, loaded bool) {
a, loaded := iMap.m.LoadOrStore(key, value)
actual = a.(string)
return
}
func (iMap *IntStrMap) Range(f func(key int, value string) bool) {
f1 := func(key, value interface{}) bool {
return f(key.(int), value.(string))
}
iMap.m.Range(f1)
}
func (iMap *IntStrMap) Store(key int, value string) {
iMap.m.Store(key, value)
}
在IntStrMap类型的方法签名中,明确了键的类型为int,且值的类型为string。这些方法在接受键和值的时候,就不用再做类型检查了。
或者可以用反射来做类型校验,如下:
type ConcurrentMap struct {
m sync.Map
keyType reflect.Type
valueType reflect.Type
}
func NewConcurrentMap(keyType, valueType reflect.Type) (*ConcurrentMap, error) {
if keyType == nil {
return nil, errors.New("nil key type")
}
if !keyType.Comparable() {
return nil, fmt.Errorf("incomparable key type: %s", keyType)
}
if valueType == nil {
return nil, errors.New("nil value type")
}
cMap := &ConcurrentMap{
keyType: keyType,
valueType: valueType,
}
return cMap, nil
}
func (cMap *ConcurrentMap) Load(key interface{}) (value interface{}, ok bool) {
if reflect.TypeOf(key) != cMap.keyType {
return
}
return cMap.m.Load(key)
}
func (cMap *ConcurrentMap) Store(key, value interface{}) {
if reflect.TypeOf(key) != cMap.keyType {
panic(fmt.Errorf("wrong key type: %v", reflect.TypeOf(key)))
}
if reflect.TypeOf(value) != cMap.valueType {
panic(fmt.Errorf("wrong value type: %v", reflect.TypeOf(value)))
}
cMap.m.Store(key, value)
}