10 Exploring Temporal Information for Dynamic Network Embedding 5
Abstract
本文提出了一种名为DTINE的无监督深度学习模型,该模型探索了时间信息,以进一步增强动态网络中节点表示的鲁棒性。为了保持网络的拓扑结构,设计了一种时间权值和采样策略来从邻居中提取特征。将注意力机制应用于RNN,以衡量历史信息的贡献,捕捉网络的演化。
Conclusion
本文讨论了在网络嵌入中引入时间信息的影响。提出了一种新的无监督模型DTINE,该模型通过提取邻域特征来保持动态拓扑结构,并通过LSTM层学习网络演化。未来工作:引入更多的信息,如节点标签和节点属性,以丰富节点表示,并在更大的网络上运行。此外,将图卷积应用到模型中,以便在聚合信息时学习更多的潜在特征。
Figure and table
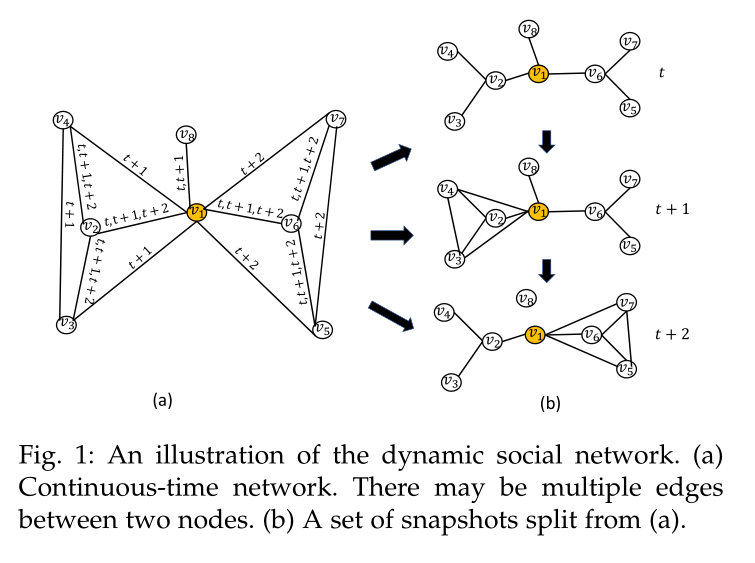
图1 动态图举例,(a)表示为连续时间动态图,(b)表示为一个从(a)分割出来的快照集,即离散时间动态图
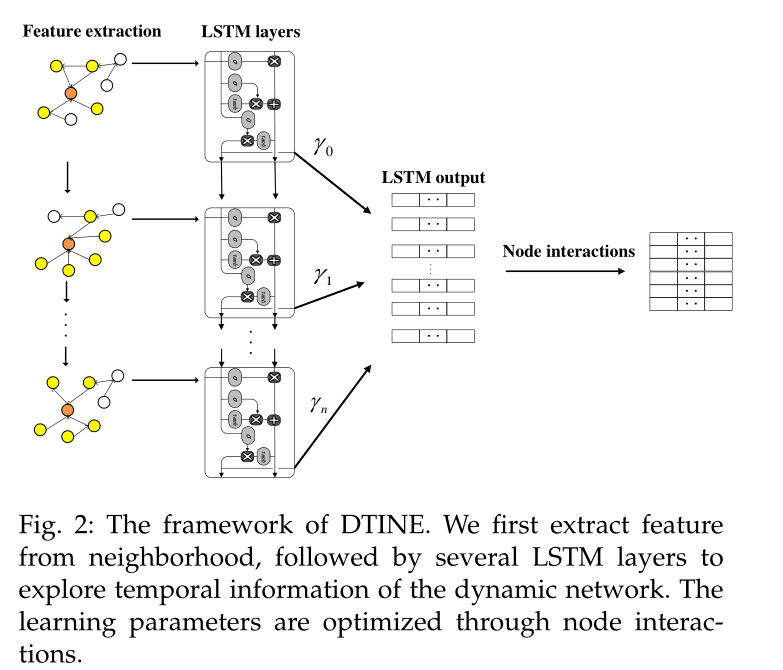
图2:DTINE框架。我们首先从邻居中提取特征,然后通过多个LSTM层来探索动态网络的时间信息。通过节点交互优化学习参数。
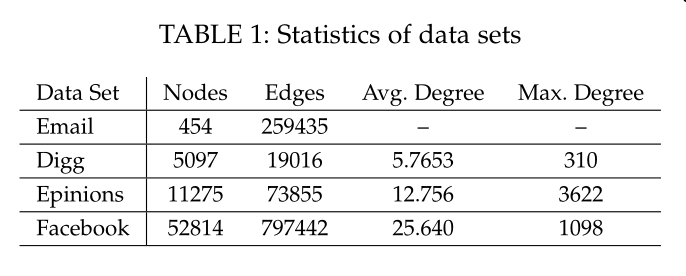
表1 数据集参数
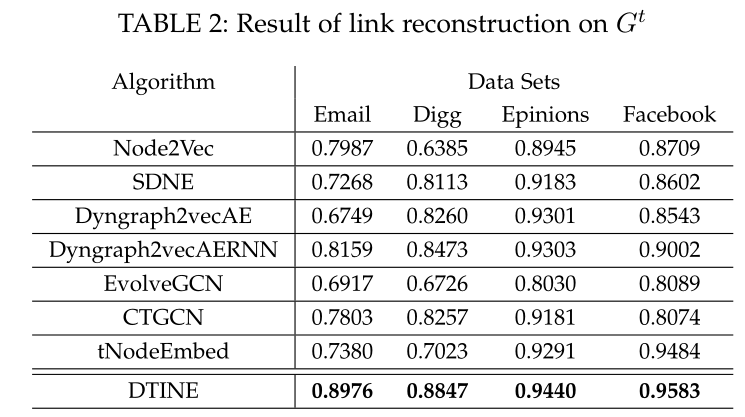
表2 在\(t\)时刻的图重构对比
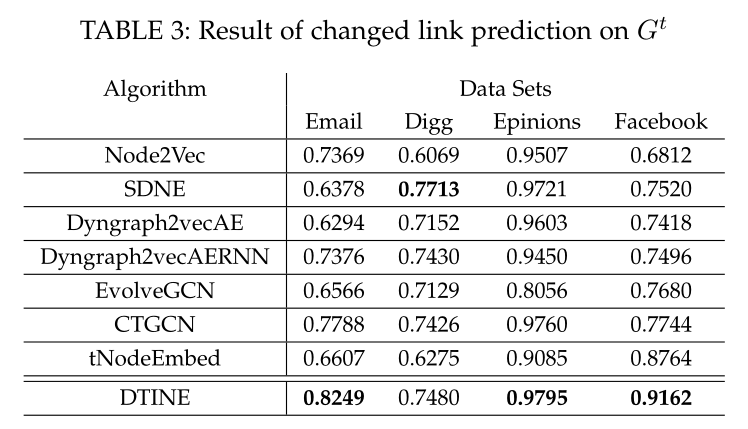
表3 在\(t\)时刻的链接预测对比
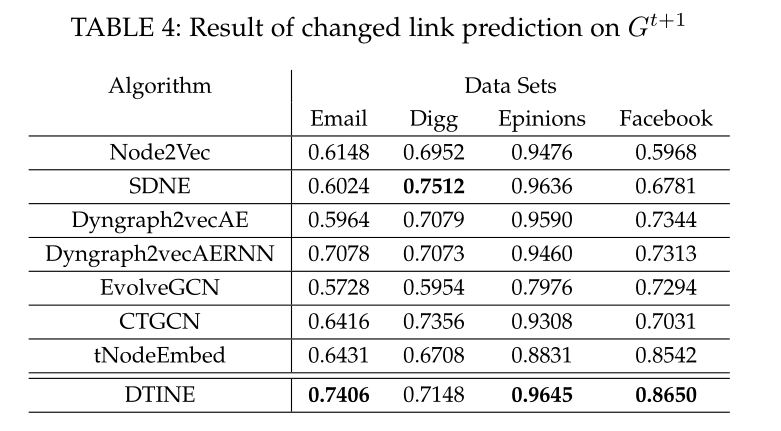
表4 在\(t+1\)时刻的链接预测对比
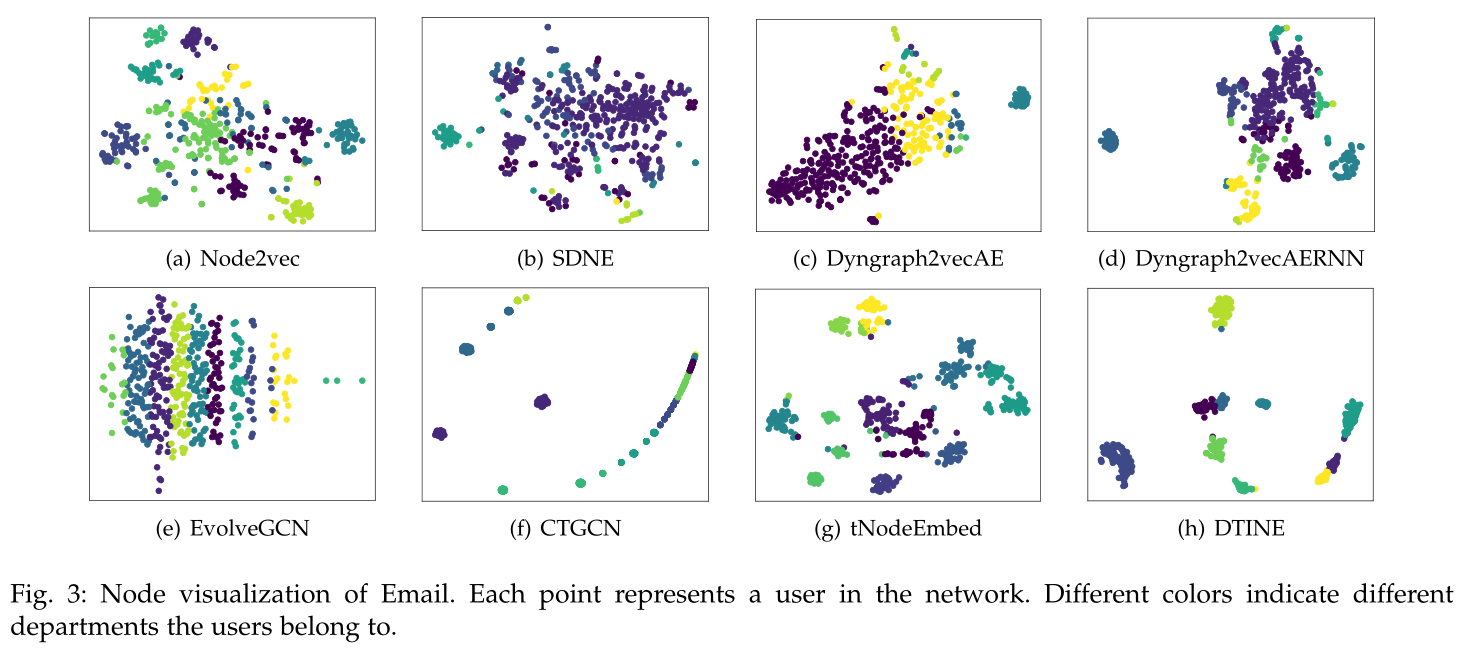
图三 数据集Email的节点可视化,每个节点代表一个用户,颜色代表用户分类。
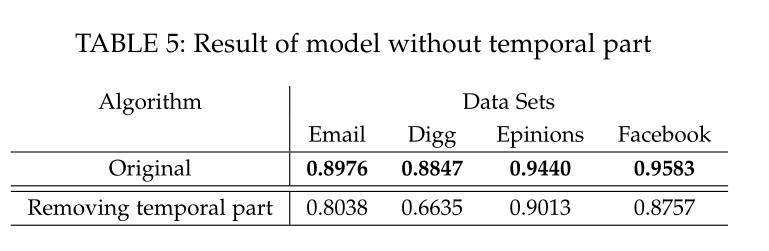
表5 时序信息对于模型的的影响
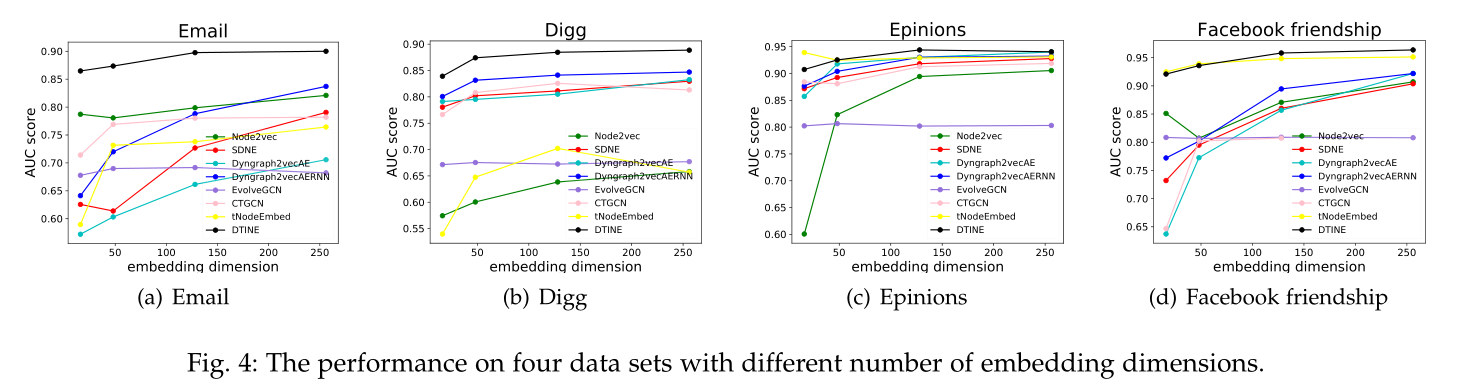
图4 不同嵌入维度对于各模型和各数据集的影响
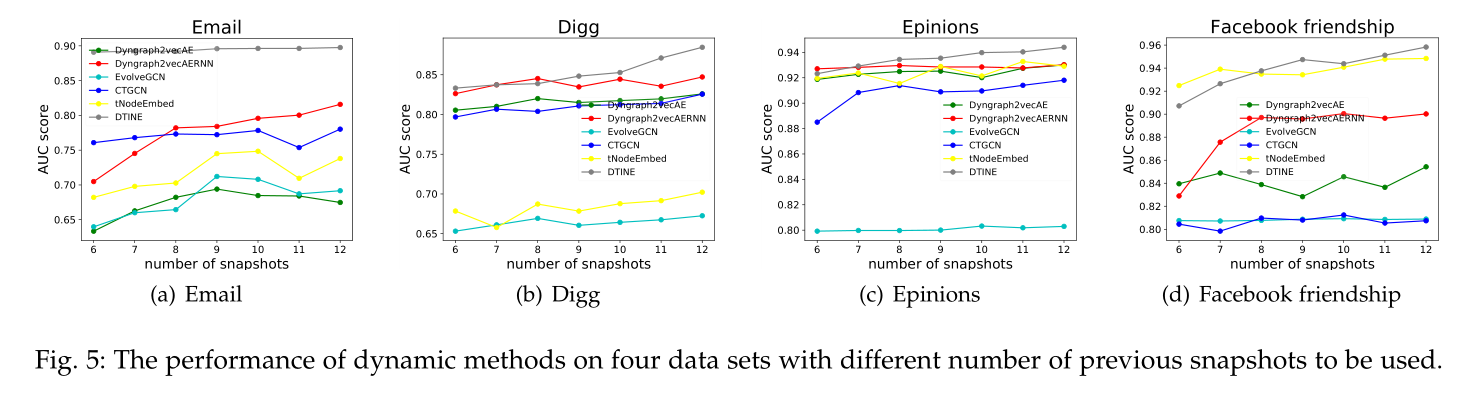
图5 不同快照数量对于各模型和各数据集的影响
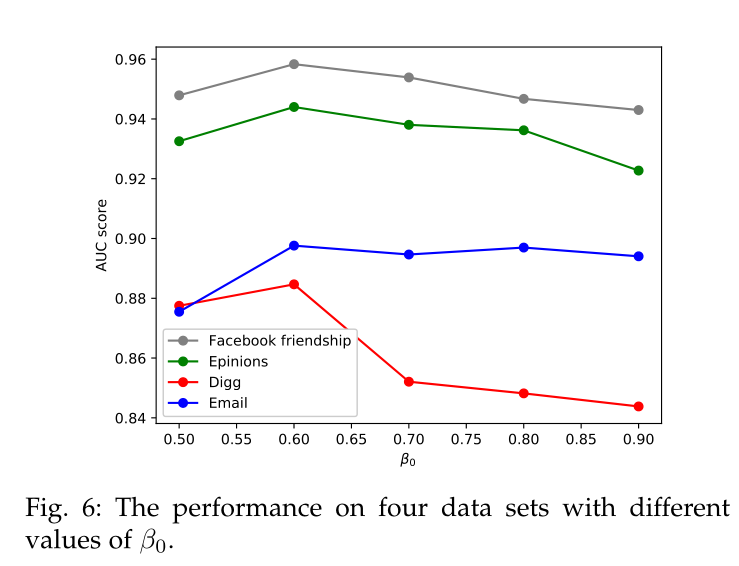
图5 \(\beta_0\)在不同数据集上对于本文模型的影响
Introduction
在现实世界中,网络本质上是动态的,其结构是随着时间的推移而演变的。描述动态网络的方法有两种,如图1(a)和图1(b)所示。第一种方法将所有链接合并成一个大型网络,在Continuous-time dynamic network embeddings中称为连续时间网络,其中每条边都拥有一个时间戳。第二种方法是分割动态图对的几个快照出来。每个快照包含链接的一小部分。正如CTDNE中所讨论的那样,由于聚合粒度较粗和边缘流的中断,后一种方法可能会导致信息丢失。离散时间间隔也需要谨慎选择。而将动态网络分解为快照是一种有效的表达网络结构性质变化的方法。该方法可以方便地捕捉网络的演化过程。如图1(b)所示,在t时刻,\(v_1\)与其他一些用户进行通信。假设\(v_2、v_3、v_4\)喜欢运动,而\(v_5、v_6、v_7\)喜欢看电影。他们可以根据自己的兴趣分成不同的群体。在\(t + 1\)时刻,\(v_1\)喜欢和\(v_2\)一起运动,\(v_2\)随后给他介绍了一些新朋友。随着时间的推移,他被一些电影所吸引,并把精力转移到电影社区的其他人身上,比如\(v_5, v_6, v_7\)。用户的变化模式可以反映网络随着时间的推移是如何发展的。探索这些时间信息使我们能够有效地发现用户的社交策略,并更准确地预测链接。
以往的工作只考虑结构信息,将静态方法在每个快照上使用,然后跨时间步对齐嵌入结果。但是在网络独立运行时可能会产生不稳定的后果。即使网络是相似的,嵌入的结果可能完全不同,这使得很难捕捉到变化过程。此外,这些工作不能扩展到大型网络,因为在每个快照上执行node2vec[28]和GCN[9]等方法需要大量的参数学习,时间消耗较大。其他方法生成时间随机游动来捕捉网络演化。然而,这也会导致上面提到的空间不连续的问题,如果网络中变化的部分很大,行走就会非常复杂。
本文贡献如下
提出了一种名为DTINE的无监督方法,利用动态拓扑来学习网络表示。
提出了两种特殊的注意力机制分别用于特征提取和网络训练,可以进一步探索历史信息。
大量的实验结果表明,DTINE实现了几个最先进的基线的显著改善。
Method
3 PROBLEM DEFINITION
Definition 1 (Dynamic network):给定一个时序网络\(\mathcal{G}=<\mathcal{V,E,T}>\) ,其中V是所有的节点集,E是所有的边集,T是一个将每条边映射到时间戳的函数。G可以是有向图或者无向图。基于时间戳,动态网络将被分割为一系列等间隔快照\({G_1, G_2,…, G_T}\)。\(T\)为时间步,\(G^t=<V^t, E^t, A^t>\)表示为一个在时间t的图的一个快照。\(E^t\)包含固定时间区间\([t, t + τ]\)内的边。注意,在\(E^t\)中,节点\(v_i\)和\(v_j\)之间可能存在多条边。将在\(E^t\)中相同节点存在多条边表示为\(A_{i j}^{t}=L^{t}(i, j)\),其中\(L^{t}(i, j)\)是节点\(v_i\)和\(v_j\)在时间\(t\)的链接频率。本文假定所有快照的节点数量保持不变。不可见或删除的节点\(i\)将被视为一个孤立的节点,并使\(A^t[i,:] = 0\)。
Definition 2 (Temporal network embedding):假设最后一个快照\(G^t\)是一个静态网络,模型旨在学习一个映射函数\(f:v_i→ \mathbb{R}^d , d << N\)使得经过\(\{ G^1, G^2, ..., G^{t−1} \}\)的快照训练后,节点\(v\)有合适的嵌入表示,其中\(d\)为每个节点表示的维数,\(N\)为节点个数。本文目标是保存结构信息(最近的节点有类似的表示)和时间信息(节点能够在未来探索潜在的关系)。
4 PROPOSED METHOD
模型由两个部分组成
第一个组件是基于图卷积网络,它通过聚集来自邻居的特征来学习节点表示。不同的是,在本文的工作中,会用历史信息来更新边的权值。
第二个组件通过快照探索时间属性。我们通过向LSTM层添加注意机制来对每个快照的贡献进行建模。
DTINE的框架如图2所示。在每个快照中提取从上一个时间步获得的特征,这些特征将被串联起来并输入到LSTM层。最后的节点表示是根据特定的规则从LSTM的隐藏状态聚合而来的。
4.1 Feature Initialization
在大多数网络中,节点之间的连接非常稀疏。导致邻接矩阵中存在大量的零元素。在没有任何额外特征的情况下直接对稀疏矩阵进行操作,可能会增加时间和空间的复杂度,并造成模型中的信息冗余。所以作者在初始化特征时应用静态算法来提取结构特征,比如node2vec。
4.2 Feature Extraction
对于时序图建模,作者认为就是在对不同时间下的图快照\(\{ G^1, G^2, ..., G^{t} \}\)中的链路变化建模。假设网络的演化可以看作是每个节点的邻域的变化(增加或删除的链接),这最终反映在信息聚合的变化上。
然而,同一个节点可能会在快照中关注不同的点。例如在图1(b)中,在\(t + 1\)时刻,\(v1\)与\(v_2\)、\(v_3\)、\(v_4\)在运动中有相同的兴趣,它们之间的连接强度高于其他。然后在\(t + 2\)的时候,\(v_1\)更喜欢看电影,并且和\(v_5\)、\(v_6\)、\(v_7\)分享他的感受,导致他们之间的权重变大。注意,在\(v2\)和它的邻居之间没有添加或删除链接,但是它们的权值发生了变化。因此,如果我们想要对网络演化建模并捕获时间信息,就不应该对每个邻居一视同仁。换句话说,应该评估每个邻居的贡献,而不是训练平均聚集器来收集信息。
在本文中,提出了一种新的权值策略,该策略可以随着网络的发展估计节点之间的链路权值。其中,特定快照t中两个连通节点\(i\)和\(j\)的强度函数可以表示为:
其中
在等式(1)中,同时考虑结构和时间的影响。
第一项可以看作是源节点\(i\)和目标节点\(j\)之间的结构连接强度。\(D(i)\)是节点\(i\)的度,\(D_\text{common}(i, j)\)表示快照中\(i\)和\(j\)的共同邻居的数量。注意,如果两个节点有很多共同的邻居,那么它们彼此相似。如果一个节点度较大,则会将注意力转移到其他节点上,导致权值小。
第二项考虑了当前和之前的时间步长,可以看作是节点\(i\)和\(j\)的时间连接强度。\(λ_{i,j}\)表示节点\(i\)对节点\(j\)的影响程度。\(L(i, j)\)是\([t−τ, t]\)中两个节点之间的链接数,因为它们可能在一个时间间隔内相互接触多次。\(C(i, j)\)表示节点\(i\)和节点\(j\)有链接的之前快照的数量。\(C(i, j)\)的值应该在\(0\)到\(t\)之间。时间连接强度表明,节点\(i\)和\(j\)在时间t之前的连接越多,权值越大。具体来说,如果一个节点与其他节点保持连接,它们的关系应该非常稳定,导致它们之间更大的亲和力。
为了保证权重系数的可比性,建议使用softmax函数对权重系数进行归一化处理:
其中\(\mathcal{N}(i)\)表示\(i\)的邻居。采用与其他模型相似的注意机制,利用\(\alpha_{i, j}\)和1跳邻居提取信息。因此,节点\(i\)的邻居影响可以表示为:
其中
\(U^{t-1}(i)\)为\(i\)在前一个快照中的表示
\(N (i)\)表示\(i\)的邻居。
二阶相似是一个非常重要的度量,它可以模拟节点间的相似性,并保持全局结构。所以引入了二跳邻居的信息聚合,这里没有用注意力权重,而是用的均值聚合
其中\(N^2(i)\) 为\(i\)的2跳邻居,\(|N^2(i)|\)为2跳邻居的数量。
下面是时间平滑假定:作者认为,在真实的世界里,边的变化都是平滑的,换句话说,只会有少量边在两个连续时间快照里增加或者删除。
因此,嵌入应该随着时间平滑地变化,这意味着如果一个节点及其邻域在两个快照中相似,那么它的表示应该保持相似。
假设我们没有对平滑变化进行建模,由于失去节点表示之间的规律性,可能很难捕捉网络的演化。为了实现这个目标,我们将第t个快照中的节点i表示为:
其中\(β_0 + β_1 = 1\),且\(β_0 > β_1\),这两个系数被用来衡量一阶和二阶邻近的贡献。上式确保节点表示平滑地变化,因为随着时间的推移,它们在嵌入空间中的变换是线性的(增量加减)。
4.3 Sampling Strategy
随着网络的扩大,邻居的数量也会增加,导致聚合信息时消耗更多的内存和计算量。于是提出了一种有效地抽取邻居信息并去除冗余信息的方法。其中,节点\(i\)的邻居\(j\)被采样的概率表示为
其中\(\varphi_{0} \in\left[0,1-\frac{1}{[\mathcal{N}(i)}\right], \varphi_{1} \in\left[0, \frac{1}{\mid \mathcal{N}(i)}\right]\),这种抽样策略加强了由新更新的边连接的节点应该得到更多的权重
在第4.2节中,该策略将对邻居集进行抽样,并在聚合信息时用\(\mathcal{N}_\text{sample}(i)\)替换\(\mathcal{N} (i)\)。对于2跳邻居\(\mathcal{N}^2(i)\),我们只使用随机抽样。
4.4 Temporal Node Embedding
作者解释为为什么可以使用LSTM:
假设我们聚合了所有快照中每个节点的信息。关键的一点是如何结合这些离散表示并获得最终的嵌入结果,因为节点交互在快照之间是独立的。受机器翻译、文本分类等的启发,在自然语言处理中,时间轴中的每个节点都可以看作是句子中的一个单词。
因此,可以使用LSTM[42]学习隐含层节点表示。将LSTM层定义为如下表示
\(h_t(i)\)包含所有的时间步下的信息,然而,每个快照对最后一个节点表示的贡献是不同的,即,前一个时间步骤中的事件可以在不同程度上影响当前表示。
例如图1(b)中,\(v_1\)一开始倾向于与喜欢运动的人交流。随着时间的推移,他被其他事情所吸引,比如看电影和画画。但是当他回到运动的兴趣下时,时间为\(n + t\),我们可以发现许多朋友在时间\(t\)重新出现在他的交流列表。因此,第\(t\)个快照的邻域信息对当前节点表示的影响最为显著。其数学表达式为
为了有效地模拟历史信息的贡献,我们在LSTM网络中加入了注意机制。设\(H(i)\)是\([h_0(i), h_1(i),…,h_T (i)]\),\(H(i) ∈ R^{T ×d}\),式中\(T\)为快照个数,\(d\)为LSTM层的隐藏维数。则有下式
其中
\(w_{1} \in \mathbb{R}^{1 \times d}, w_{2} \in \mathbb{R}^{T \times d}\)为学习参数,分别对\(H(i)\)和\(h_T (i)\)进行转换。
\(h^s(i) \in \mathbb{R}^{1 \times d}\)为节点\(i\)在最终快照\(G^t\)中的表示,它可以保存时间信息。
损失的目标为约束相似性最高的节点嵌入最接近的潜在空间。同时,离散或相距较远的节点将受到惩罚。损失如下:
其中
\(N_{walk}(i)\)是随机游走中节点\(i\)附近出现的节点的集合。
\(p_n\)是负抽样分布,\(Q\)是采样的负节点数
\(\nu\)是衰减系数,\(W\)是模型的学习参数。权重衰减项可以防止训练阶段的过拟合。
\(h^s (i),h^s (j)\)为计算节点间接近度的内积。采用随机梯度下降法对损失函数进行优化。
该模型的计算过程见算法1。
第2-9行为从邻域中提取特征,并确保节点嵌入在时间步中平滑变化。
第10-14行迭代\(G^T\)节点训练LSTM,捕捉网络演化。

Experiment
5 EXPERIMENTS
5.1 Data Sets
数据集及其参数见表1
5.2 Baselines
Node2Vec
SDNE
Dyngraph2vecAE ,Dyngraph2vecAERNN
EvolveGCN
CTGCN
tNodeEmbed
5.3 Experimental Setup
采用AUC作为指标,
嵌入维数设为128
权重衰减系数\(\nu\)为0.001
对于Facebookand Digg, 学习率是 0.001,而在Email中学习率将是0.0003。设置快照数量为12个。
5.4 Experimental Results
5.4.1 Link Prediction
Link reconstruction 见表2
Changed link prediction 见表3表4
Removing temporal part见表5
5.5 Parameter Sensitivity
Embedding dimension 见图4
Number of snapshots 见图5
Summary
在这篇文章里学到了用node2vec来做图嵌入的初始化,整篇文章读下来总结一下就是DTDG用时间平滑来尽可能的模拟CTDG,然后用了类GCN的信息聚合,用了随机采样减少计算量,用了注意力权重来控制邻居的影响,用LSTM保存时序信息,整体上没看出来有啥新意,又是一篇搭积木