1. 浮点数的表示
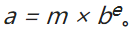
m 是尾数, 为±d.dddddd 其中 第一位必须非0
b 是基数,

下面,让我们回到一开始的问题:为什么0x00000009还原成浮点数,就成了0.000000?
首先,将0x00000009拆分,得到第一位符号位s=0,后面8位的指数E=00000000,最后23位的有效数字M=000 0000 0000 0000 0000 1001。
由于指数E全为0,所以符合上一节的第二种情况。因此,浮点数V就写成:
V=(-1)^0×0.00000000000000000001001×2^(-126)=1.001×2^(-146)
结论
通用规则:
- 整数和(和
AND/OR/XOR)与乘积花费的时间相同,除法(和取模)的速度慢三倍。 - 浮点数的乘积比求和的乘积慢两倍,除法的乘积甚至更慢。
- 在相同数据大小下,浮点运算始终比整数运算慢。
- 越小越快。
- 64位整数精度确实很慢。
- 浮点数32位总和比64位快,但在乘积和除法上却不是。
- 80和128位精度仅在绝对必要时才应使用,它们非常慢。
特别案例:
- 在x86-64 AVX上,浮点乘积在64位数据上比在32位上更快。
- 在POWER8 AltiVec上,浮点乘积以各种精度达到求和的速度。对8位,16位,32位或64位整数以相同的速度执行整数运算。
- 在ARM1176上,按位整数运算符比加法运算要快。
示例代码:
#include <stdio.h> #include <math.h> #include <stdlib.h> #include <cv/cv_tools.h> #include <picture/cv_picture.h> #include "libyuv.h" using namespace cv; using namespace std; using namespace oop; int main() { const int N= 10000; int sum = 0; float sumf = 0; float nf = 734.0f; int n = 734; timeInit; timeMark("int"); for(int j=0;j!=100000;++j) { sum = 0; for (int i = 0; i != N; ++i) { sum += n; } } timeMark("float"); for (int j = 0; j != 100000; ++j) { sumf = 0; for (int i = 0; i != N; ++i) { sumf += nf; } } timeMark(")"); timePrint; printf("sum=%d sumf=%.2f ",sum,sumf); getchar(); }
输出:
( int,float ) : 2107 ms
( float,) ) : 3951 ms
sum=7340000
sumf=7340000.00
Release:
( int,float ) : 0 ms
( float,) ) : 1814 ms
sum=7340000
sumf=7340000.00
实际上: Debug模式下, 两者时间差不了多少,两倍的关系
但是Release模式下, int 几乎很快就完成了!! 说明int型被优化得很好了,float型运算不容易被编译器优化!!!
我们在Release模式下, 优化设置为O2, 连接器设置为-优化以便于调试
查看int 乘法汇编指令:xmm0 表示128位的SSE寄存器,可见我们的代码都被优化为SSE指令了!!

查看float 汇编代码:
感觉里面也有xmm 等SSE指令集, 至于为啥int型乘法比float乘法快很多, 还是有点搞不明白, 需要详细分析里面的汇编指令才能搞明白
网上关于这方面的资料太少了, 哎~~
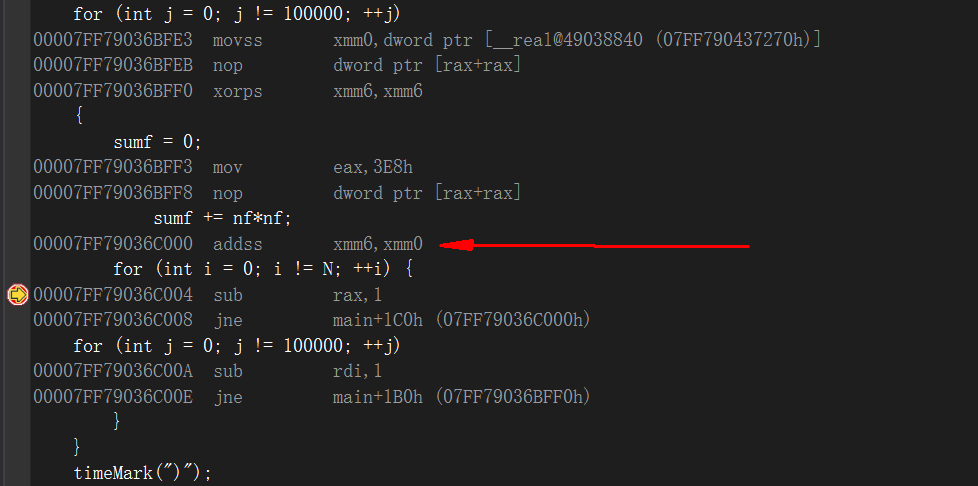
我们再看看float 和 int乘法对图像进行处理的例子:
我们把BGR 3个通道分别乘以2 3 4 、 2.0f, 3.0f, 4.0f 然后输出, 这里我们不考虑溢出的问题, 仅仅对乘法的效率进行测试
设置为Release模式,O2
int main() { cv::Mat src = imread("D:/pic/nlm.jpg"); //cvtColor(src,src,CV_BGR2GRAY); resize(src,src,Size(3840*2,2160*2)); cv::Mat dst0(src.size(), src.type()); cv::Mat dst1(src.size(), src.type()); int w = src.cols; int h = src.rows; int of3=0; timeInit; timeMark("int"); for (int j = 0; j != h; ++j) { for (int i = 0; i != w; ++i) { //int of3 = (j*w + i) * 3; dst0.data[of3 ] = src.data[of3] * 2; dst0.data[of3 + 1] = src.data[of3 + 1] * 3; dst0.data[of3 + 2] = src.data[of3 + 2] * 4; of3+=3; } } timeMark("float"); of3=0; for (int j = 0; j != h; ++j) { for (int i = 0; i != w; ++i) { //int of3 = (j*w + i)*3; dst1.data[of3] = src.data[of3] * 2.0f; dst1.data[of3+1] = src.data[of3+1] * 3.0f; dst1.data[of3+2] = src.data[of3+2] * 4.0f; of3 += 3; } } timeMark("end"); timePrint; myShow(dst0); myShow(dst1); waitKey(0); }
输出:
( int,float ) : 149 ms
( float,end ) : 173 ms
输出图像(分别为原图,dst0,dst1)(截取了一部分)
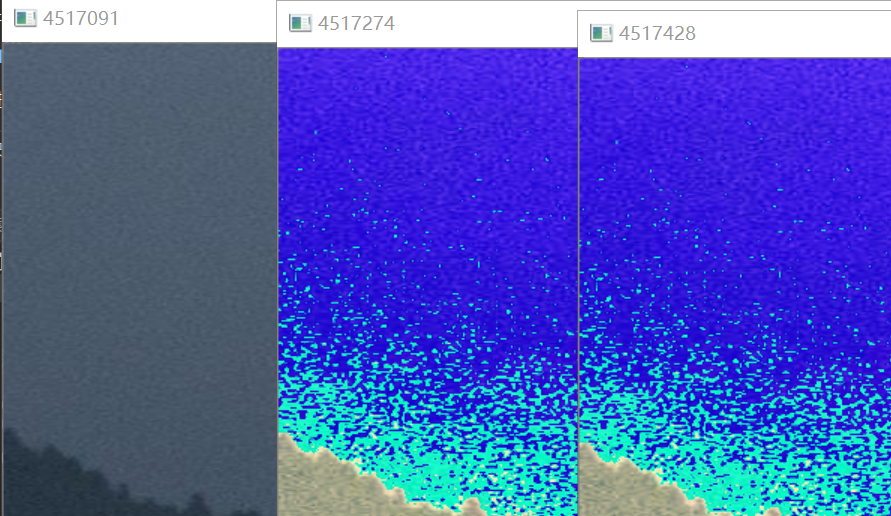
可见,时间并差不了多少,但int还是要快一点!!
这是我看到的另外一个帖子,里面讲的float乘法确实比较复杂 , 这可能是它比较慢的原因之一吧
https://blog.csdn.net/u014298090/article/details/21867187
总结一下: float运算更慢的原因:
1. float运算不容易被编译器优化
2. float运算本身就慢(但并不比int型运算慢多少,大约1.3-2倍的样子)