hadoop伪分布模式,只有一个节点,通常用来做测试。
一、环境准备
二、创建Hadoop用户(以后有关集群的操作都只用此用户);

三、配置SSH互相(免密登录);
![JLZW4]4DIQ9L0JA[OCX5R{O](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010406077-1596810186.png "JLZW4]4DIQ9L0JA[OCX5R{O")

@~44")
四、解压Hadoop安装包;

![[UBFP{]V$UQ{2UBK_[6D}X3](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010411818-1053344711.png "[UBFP{]V$UQ{2UBK_[6D}X3")
五、修改配置文件;
- 修改hadoop-env.sh,配置jdk位置;
9KRNZRC1PKSXD}JS2})0LL")
- 修改core-site.xml;
![00W1%5)RWY8J3C4E{@7])AH](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010414975-1849839402.png "00W1%5)RWY8J3C4E{@7])AH")
- hdfs-site.xml配置;
[T557AYS6UG3WRDA5WHI")
- 配置Mapreduce调用方式;
![4}C8]LA2S2]HA({I@3[0O00](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010418691-1996237572.png "4}C8]LA2S2]HA({I@3[0O00")
- yarn有关的配置;
![TR_V6N_YS3]I[S(8O4VVDSY](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010420476-1380650839.png "TR_V6N_YS3]I[S(8O4VVDSY")
9KRNZRC1PKSXD}JS2})0LL")
![Z2L2UOA(Z2WF0E]E5WB5ENQ](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010413905-1879041136.png "Z2L2UOA(Z2WF0E]E5WB5ENQ")
![00W1%5)RWY8J3C4E{@7])AH](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010414656-1857238341.png "00W1%5)RWY8J3C4E{@7])AH")
![~[AJ]%6UPM(Y$UZ6NS39CVB](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010415376-284332167.png "~[AJ]%6UPM(Y$UZ6NS39CVB")
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
<!—- hadoop01:主机名,9000:端口 -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<property>
<!-- 数据冗余一份 -->
<name>dfs.replication</name>
<value>1</value>
</property>![4}C8]LA2S2]HA({I@3[0O00](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010418256-1822441021.png "4}C8]LA2S2]HA({I@3[0O00")

<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
<!—hadoop01:主机名 -->
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>六、创建Hadoop数据目录(su到root用户下);
- su – root
![}VNGM`UE7HOX6]AERBAF4CW](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010422114-2001706295.png "}VNGM`UE7HOX6]AERBAF4CW")
七、配置系统环境变量;
![SN0RKLUO)0L2`X9]IXF0144](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010423555-970940672.png "SN0RKLUO)0L2`X9]IXF0144")
![)696N(_F]NUQ$CYIW]XIUHP](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010425023-719883048.png ")696N(_F]NUQ$CYIW]XIUHP")
八、格式化namenode节点(注意:只能格式化一次);
- 在hodoop用户下,格式化namenode(执行一次命令即可);
![DURA4H%J}TOC]D{JKE{3{)0](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010426850-595822124.png "DURA4H%J}TOC]D{JKE{3{)0")
![DURA4H%J}TOC]D{JKE{3{)0](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010426074-17088349.png "DURA4H%J}TOC]D{JKE{3{)0")

九、启动集群;
- 使用hadoop用户启动集群;
![A(QT{]TAXC~D[Z0OVR_S]NE](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010430306-1198868524.png "A(QT{]TAXC~D[Z0OVR_S]NE")
![A(QT{]TAXC~D[Z0OVR_S]NE](https://img2018.cnblogs.com/blog/1469176/201903/1469176-20190327010429586-633917774.png "A(QT{]TAXC~D[Z0OVR_S]NE")
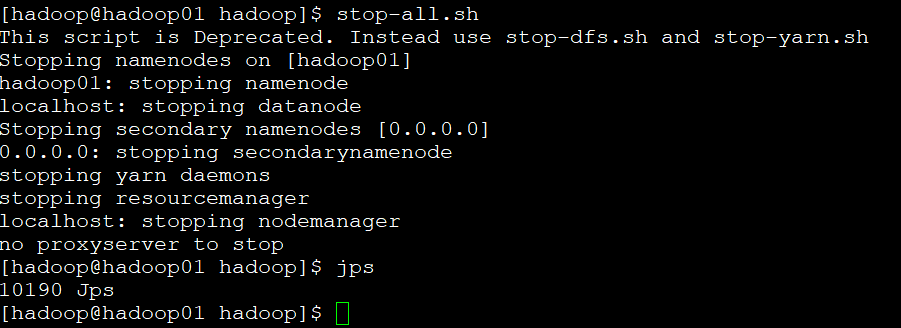
十、验证集群是否部署成功;


Q")
{kind=link}