副本机制
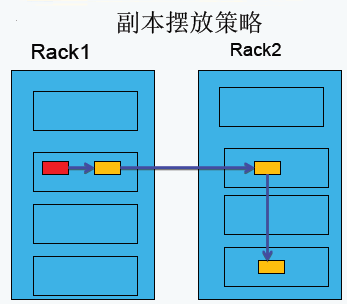
1、副本摆放策略
第一副本:放置在上传文件的DataNode上;如果是集群外提交,则随机挑选一台磁盘不太慢、CPU不太忙的节点上;
第二副本:放置在于第一个副本不同的机架的节点上;
第三副本:与第二个副本相同机架的不同节点上;
如果还有更多的副本:随机放在节点中;
2、副本系数
1)对于上传文件到HDFS时,当时hadoop的副本系数是几,那么这个文件的块副本数就有几份,无论以后怎么更改系统副本系数,这个文件的副本数都不会改变,也就是说上传到HDFS系统的文件副本数是由当时的系统副本数决定的,不会受副本系数修改而变;
2)在上传文件时可以指定副本系数,dfs.replication是客户端属性,不指定具体的replication时采用的默认副本数;文件上传后,备份数已经确定,修改dfs.replication是不会影响以前的文件,也不会影响后面指定备份数的文件,只会影响后面采用默认备份数的文件;
3)replication默认是由客户端决定的,如果客户端不设置才会去从配置文件中读取;
hadoop fs setrep 3 test/test.txt hadoop fs -ls test/test.txt
此时test.txt的副本系数就是3了, 但是重新put一个到hdfs系统中,备份块数还是1(假设默认dfs.replication的值为1)。
4)如果在hdfs-site.xml中设置了dfs.replication=1,这也并不一定就是块的备份数就是1,因为可能没把hdfs-site.xml加入到工程的classpath里,那么我们的程序运行时取的dfs.replication可能是hdfs-default.xml中的dfs.replication,默认是3;可能这个就是造成你为什么dfs.replication老是3的原因。
负载均衡
HFDS的数据并不是非常均匀的分布在各个DN上,一个常见的原因是在现有的集群上经常会新增一个DN节点,当新增一个数据块(一个文件的数据被保存在一系列的块中)时,NN在选择DN接收这个数据块之前,会考虑到很多因素:
1)将数据块的一个副本放在正在写这个数据块的节点上;
2)尽量将数据块的不同副本放在不同的机架上,这样集群可在完全失去某一个机架的情况下还能继续工作;
3)尽量均匀地将HDFS数据分布在集群的各个DN上;
负载均衡的作用:让数据均匀的分布在各个DataNode上,均衡IO性能;平衡IO、平均数据、平衡集群,防止热点的发生;
hadoop为什么会出现负载不均衡的情形?
hadoop只考虑分块的方式,而不考虑块的大小;
举个栗子:假设DataNode1上有10块数据,而DataNode2只有2块数据,可能就会导致DataNode1的IO会很高,导致集群负载不均衡;
hadoop如何做负载均衡?
hadoop balancer DataNode之间去相互拷贝数据,会占用比较大的带宽,默认采用1M的带宽去进行数据的拷贝,进而不会很大程度上影响到集群的带宽;集群在繁忙的时候不要去做负载均衡,负载均衡的执行时间可能会很长,而且没有时间提醒,直到做完为止;
机架感知
通常大型hadoop集群是以机架的形式来组织的,同一个机架上的不同节点间的网络状况比不同机架之间的更为理想;NameNode设法将数据块副本保存在不同的机架上以提高容错性;
HDFS不能够自动判断集群中各个DN的网络拓扑情况,Hadoop允许集群的管理员通过配置dfs.network.script参数来确定节点所处的机架,配置文件提供了ip到rackid的翻译。NN通过这个配置知道集群中各个DN机器的rackid。如果topology.script.file.name没有设定,则每个ip都会被翻译成/default-rack。
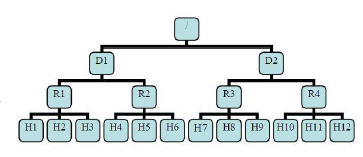
途中D和R是交换机,H是DN;
则H1的rackid=/D1/R1/H1,有了rackid信息(这些rackid信息可以通过topology.script.file.name 配置)就可以计算出任意两台DataNode之间的距离:
distance(/D1/R1/H1,/D1/R1/H1) = 0 相同的DataNode
distance(/D1/R1/H1,/D1/R1/H2) = 2 同rack下的不同DataNode
distance(/D1/R1/H1,/D1/R1/H4) = 4 同IDC下的不同DataNode
distance(/D1/R1/H1,/D1/R1/H7) = 6 不同IDC下的DataNode
HDFS访问方式
1)shell
2)java
3)WebUI
4)RESTFUL
HDFS文件删除恢复机制
当从HDFS中删除某个文件时,这个文件并不会立刻从HDFS中删除,而是将这个文件重命名转移到/trash目录;只要这个文件还在/trash目录下,该文件就可以迅速被恢复;
文件在/trash目录中存放的时间可以配置(默认为6小时),当超过这个时间时,NN就会将文件从名字空间中删除;
删除文件会使得该文件相关的数据块被释放;注意:从用户删除文件到HDFS空闲空间的增加之间会有一定时间的延迟;
配置回收站的时间:hdfs-site.xml
<property> <name>fs.trash.interval</name> <value>1440</value> </property>
时间单位是秒,回收站的位置:在HDFS上的/user/$USER/.Trash/Current/
HDFS系统缺点:不适合处理小文件
1)NN把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数目由NN的内存大小来决定;小文件越多,占用NN的内存空间就越大;
一般来说,每个文件/文件夹和BLOCK需要占据150字节左右的空间,所以,如果有100W个文件,每个占据一个block,那至少需要300M内存;
当前来说,数百万的文件还是可行的,当扩展到数十亿时,对于以前的硬件水平来说就比较难实现了;
2)Map任务数是由split来决定的,所以MapReduce处理大量小文件时,就会产生过多的Map任务,线程管理开销将会作业时间;
处理10000M的文件,如果每个split为1M,那就会有10000个Map任务,会有很大的线程开销;如果每个split为100M,那么就只有100个Map任务,每个任务处理更多的数据,线程的管理开销要降低很多;