opencv 提供了全景图像拼接的所有实现,包括:
1)stitching 模块提供了图像拼接过程中所需要的基本元素,该模块主要依赖于 features2d 模块;
2)提供了 stitching_detailed.cpp,本示例给出了如何运用 stitching 模块的详细说明;
同时,opencv 也提供了一个更高层次的封装类 cv::Stitcher,但为了详细理解图像拼接具体实现,这里不讨论该封装类。
1 特征点提取与匹配
Ptr<FeaturesFinder> finder;
if (features_type == "surf") { #if defined(HAVE_OPENCV_NONFREE) && defined(HAVE_OPENCV_GPU) if (try_gpu && gpu::getCudaEnabledDeviceCount() > 0)
finder = new SurfFeaturesFinderGpu(); else #endif finder = new SurfFeaturesFinder(150);
} else if (features_type == "orb") {
finder = new OrbFeaturesFinder(); }
FeaturesFinder 类定义在 mathers.hpp 中,mathers.hpp 封装了特征点提取,特征点描述,特征点匹配等相关功能,
FeaturesFinder 类有两个继承类,SurfFeaturesFinder 和 OrbFeaturesFinder,分别使用 SURF 特征 和 ORB 特征,当然也可以添加更多继承类,如 SIFTFeaturesFinder 等,
SURF 特征继承了 SIFT 特征良好的特性同时降低了运算时间,但 SURF 在 nonfree 模块中,所以,ORB 可能是另一种较好的选择。
由于特征计算需要耗费较多时间,所以会在小图像上进行特征提取,全局变量参数 work_megapix = 0.6 设定了特征提取的图像尺寸,表示使用 0.6M 大小图像进行特征提取,
代码 work_scale = min(1.0, sqrt(work_megapix * 1e6 / full_img.size().area())) 根据 work_megapix 计算出缩放比例。
对每幅图像,其特征点被提取到 ImageFeatures 结构体中,组成了向量 vector<ImageFeatures> features(num_images)。
struct CV_EXPORTS MatchesInfo
{
MatchesInfo();
MatchesInfo(const MatchesInfo &other);
const MatchesInfo& operator =(const MatchesInfo &other);
int src_img_idx, dst_img_idx; // Images indices (optional)
std::vector<DMatch> matches;
std::vector<uchar> inliers_mask; // Geometrically consistent matches mask
int num_inliers; // Number of geometrically consistent matches
Mat H; // Estimated homography
double confidence; // Confidence two images are from the same panorama
};
vector<MatchesInfo> pairwise_matches;
BestOf2NearestMatcher matcher(try_gpu, match_conf);
matcher(features, pairwise_matches);
matcher.collectGarbage();
结构体 MatchesInfo 包含了所有图像之间进行两两匹配的相关结构,Mat H 记录了两幅图像间的仿射变换矩阵,该矩阵是全景图像拼接的基础信息,特征点间匹配信息记录在 pairwise_mathes 中。
2 认出全景图
// Leave only images we are sure are from the same panorama vector<int> indices = leaveBiggestComponent(features, pairwise_matches, conf_thresh); vector<Mat> img_subset; vector<string> img_names_subset; vector<Size> full_img_sizes_subset; for (size_t i = 0; i < indices.size(); ++i) { img_names_subset.push_back(img_names[indices[i]]); img_subset.push_back(images[indices[i]]); full_img_sizes_subset.push_back(full_img_sizes[indices[i]]); } images = img_subset; img_names = img_names_subset; full_img_sizes = full_img_sizes_subset;
函数 leaveBiggestComponent 评估图像间特征点匹配程度,当匹配程度过低时,则认为该图像不是全景图像组成部分。
3 3D到2D映射矩阵
在特征提取与匹配中, 结构体 MatchesInfo 中 Mat H 记录了两幅图像间的仿射变换矩阵,该变换表示的二维点间的变换关系。
motion_estimators.hpp 封装了 HomographyBasedEstimator 类,用于计算3D到2D映射相关信息,这里使用旋转全景模型,通过放射变换矩阵可以首先估计出相机焦距,代码如下:
void HomographyBasedEstimator::estimate(const vector<ImageFeatures> &features, const vector<MatchesInfo> &pairwise_matches, vector<CameraParams> &cameras) { LOGLN("Estimating rotations..."); const int num_images = static_cast<int>(features.size()); if (!is_focals_estimated_) { // Estimate focal length and set it for all cameras vector<double> focals; estimateFocal(features, pairwise_matches, focals); cameras.assign(num_images, CameraParams()); for (int i = 0; i < num_images; ++i) cameras[i].focal = focals[i]; } else { for (int i = 0; i < num_images; ++i) { cameras[i].ppx -= 0.5 * features[i].img_size.width; cameras[i].ppy -= 0.5 * features[i].img_size.height; } } // Restore global motion Graph span_tree; vector<int> span_tree_centers; findMaxSpanningTree(num_images, pairwise_matches, span_tree, span_tree_centers); span_tree.walkBreadthFirst(span_tree_centers[0], CalcRotation(num_images, pairwise_matches, cameras)); // As calculations were performed under assumption that p.p. is in image center for (int i = 0; i < num_images; ++i) { cameras[i].ppx += 0.5 * features[i].img_size.width; cameras[i].ppy += 0.5 * features[i].img_size.height; } }
以上代码首先估计相机焦距,在 “全景图像拼接” 一文中,给出了根据仿射变换估计相机焦距的方法,主要是利用旋转矩阵的正交特性来实现的。
然后在估计焦距基础上计算出旋转矩阵,同时假设图像中心即为光轴,假设像元长宽比为1,vector<CameraParams> cameras 保存了每张图像上的相对于 3D 空间的映射信息。
4 全局配准
到目前为止,任意 3D 点到任意图像上的映射关系已经确定。同一个 3D 点,在多幅图像上存在对应点,使用对应的映射关系将其分别映射到 3D 空间上,理论上来说应该得到同一个 3D 点。
但实际情况可能并不理想,基于 vector<CameraParams> cameras 提供的映射关系,使用光束平差法可以消除误差。主要包括两种方法:
1)最小化重映射误差法(BundleAdjusterReproj)
首先将第 i 张图像上特征点映射到三维空间,然后再将三维空间点映射到第 j 张图像中,注意,两次映射使用了不同的映射矩阵!!!
计算第 j 张图像上的映射点于特征匹配点之间的误差,最小化所有映射点误差即完成了全局配准。
2)最小化 3D 投影方向上误差法(BundleAdjusterRay)
对第 i 张与第 j 张图像上的匹配点对分别使用映射矩阵映射到三维空间中,最小化两条射线间的距离即完成了全局配准。
完成全局配准后,可以通过 waveCorrect 消除扰动,如果图像扰动较小,有时也可以忽略他。
5 图像融合
在图像融合前,首先使用 SeamFinder 找到不同图像间的缝隙,由于缝隙寻找不需要特别精确,故使用了更小的分辨率 seam_megapix = 0.1。
由于可能存在曝光不均匀详细,使用 ExposureCompensator 类实现曝光补偿相关工作,最后使用 Blender 完成图像融合。
关于图像融合还有很多需要详细理解的内容,但该部分没有太多参数需要调整,所以暂时不深入了解。下面给出拼接效果:
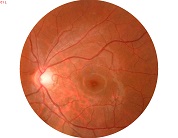
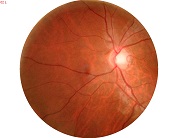
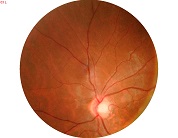
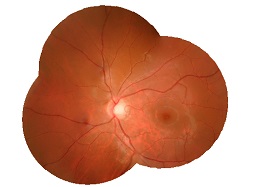
参考资料 opencv-2.4.10modulesstitching && stitching_detailed.cpp