Django支持的数据库
- PostgreSQL
- SQLite 3
- MySQL
- Oracle
其中SQLite 3不需要安装,因为SQLite使用文件系统上的独立文件来存储数据
这里我们用SQLite 3测试,但如果是大型项目的话建议不要使用SQLite 3
安装sqllite3图形化工具
首先方便查看数据库的变化我们下载一个数据库图形化工具SQLiteStudio
链接:https://sqlitestudio.pl/index.rvt
打开DataBase->Add a database,填写sqllite3的文件路径
这时就能打开了,你会发现是空的,因为我们还没有添加任何数据
了解数据库的配置信息
我们查看一下Django的数据库配置文件setting.py下的DATABASES
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } }
- DATABASE_ENGINE 告诉Django使用哪个数据库引擎
- DATABASE_NAME 将数据库名称告知 Django,我们也可以自己设置路径,不用django自带的sqlite3
以下选项默认是没有的,因为sqlite3不需要配置,如果你更换了数据库那么你需要配置这些:
- DATABASE_USER 告诉 Django 用哪个用户连接数据库。 例如: 如果用SQLite,空白即可。
- DATABASE_PASSWORD 告诉Django连接用户的密码。 SQLite 用空密码即可。
- DATABASE_HOST 告诉 Django 连接哪一台主机的数据库服务器。 如果数据库与 Django 安装于同一台计算机(即本机),可将此项保留空白。 如果你使用SQLite,此项留空。
这里我们了解以下各个配置就行,因为不换数据库所以不需要做任何更改
如果你使用了其他数据库,那么你可以参考一下这个配置:
import pymysql # 一定要添加这两行!通过pip install pymysql! pymysql.install_as_MySQLdb() DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'mysite', 'HOST': '192.168.1.1', 'USER': 'root', 'PASSWORD': 'pwd', 'PORT': '3306', } }
输入下面这些命令来测试你的数据库配置:
>>> from django.db import connection >>> cursor = connection.cursor()
如果没有显示什么错误信息,那么你的数据库配置是正确的。 否则,你就得 查看错误信息来纠正错误。
| 错误信息 | 解决方法 |
|---|---|
| You haven’t set the DATABASE_ENGINE setting yet. | 不要以空字符串配置`` DATABASE_ENGINE`` 的值。 表格 5-1 列出可用的值。 |
| Environment variable DJANGO_SETTINGS_MODULE is undefined. | 使用`` python manager.py shell`` 命令启动交互解释器,不要以`` python`` 命令直接启动交互解释器。 |
| Error loading _____ module: No module named _____. | 未安装合适的数据库适配器 (例如, psycopg 或 MySQLdb )。Django并不自带适配器,所以你得自己下载安装。 |
| _____ isn’t an available database backend. | 把DATABASE_ENGINE 配置成前面提到的合法的数据库引擎。 也许是拼写错误? |
| database _____ does not exist | 设置`` DATABASE_NAME`` 指向存在的数据库,或者先在数据库客户端中执行合适的`` CREATE DATABASE`` 语句创建数据库。 |
| role _____ does not exist | 设置`` DATABASE_USER`` 指向存在的用户,或者先在数据库客户端中执创建用户。 |
| could not connect to server | 查看DATABASE_HOST和DATABASE_PORT是否已正确配置,并确认数据库服务器是否已正常运行。 |
系统对app有一个约定: 如果你使用了Django的数据库层(模型),你 必须创建一个Django app。 模型必须存放在apps中。 因此,为了开始建造 我们的模型,我们必须创建一个新的app。
这在我们day5已经将过了如何创建app和配置app的视图了。
模型的使用
我们来假定下面的这些概念、字段和关系:
-
一个作者有姓,有名及email地址。
-
出版商有名称,地址,所在城市、省,国家,网站。
-
书籍有书名和出版日期。 它有一个或多个作者(和作者是多对多的关联关系[many-to-many]), 只有一个出版商(和出版商是一对多的关联关系[one-to-many],也被称作外键[foreign key])
第一步是用Python代码来描述它们。 打开myapp/models.py 并输入下面的内容:
from django.db import models
class Publisher(models.Model): name = models.CharField(max_length=30) address = models.CharField(max_length=50) city = models.CharField(max_length=60) state_province = models.CharField(max_length=30) country = models.CharField(max_length=50) website = models.URLField() class Author(models.Model): first_name = models.CharField(max_length=30) last_name = models.CharField(max_length=40) email = models.EmailField(verbose_name='e-mail',blank=True)#为了指定email字段为可选,要设置blank为True,默认为False
class Book(models.Model):
title = models.CharField(max_length=100)
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher,models.CASCADE)
publication_date = models.DateField(blank=True,null=True)
注意的是每个数据模型都是 django.db.models.Model 的子类。它的父类 Model 包含了所有必要的和数据库交互的方法,并提供了一个简洁漂亮的定义数据库字段的语法。
如果你想允许一个日期型(DateField、TimeField、DateTimeField)或数字型(IntegerField、DecimalField、FloatField)字段为空,你需要使用null=True 和 blank=True。
verbose_name='e-mail'是指定属性名字(一般是以变量名作为属性名,但是如果遇到-等特殊符号就不能作为变量名,那么我们就需要以这种方式命名)
这里django1.x于django2.x有个区别,定义外键和一对一关系的时候需要加on_delete选项,此参数为了避免两个表里的数据不一致问题,否则报错。我们一般情况下使用CASCADE就可以了。
on_delete值的详细说明:
on_delete=None, # 删除关联表中的数据时,当前表与其关联的field的行为 on_delete=models.CASCADE, # 删除关联数据,与之关联也删除 on_delete=models.DO_NOTHING, # 删除关联数据,什么也不做 on_delete=models.PROTECT, # 删除关联数据,引发错误ProtectedError # models.ForeignKey('关联表', on_delete=models.SET_NULL, blank=True, null=True) on_delete=models.SET_NULL, # 删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空,一对一同理) # models.ForeignKey('关联表', on_delete=models.SET_DEFAULT, default='默认值') on_delete=models.SET_DEFAULT, # 删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值,一对一同理) on_delete=models.SET, # 删除关联数据, a. 与之关联的值设置为指定值,设置:models.SET(值) b. 与之关联的值设置为可执行对象的返回值,设置:models.SET(可执行对象)
在创建数据库表前需要把app在setting中设置一下,这在我们day5已经设置过了
现在我们可以创建数据库表了。 首先,用下面的命令验证模型的有效性:
#python manage.py validate#尝试运行,发现在django2.x中已失效
python manage.py check#正确的命令
如果一切正常,你会看到System check identified no issues (0 silenced)消息。如果出错,请检查你输入的模型代码。 错误输出会给出非常有用的错误信息来帮助你修正你的模型。
接着尝试运行以下命令查询数据库创建命令:
python manage.py sqlall myapp#报错
发现报错了,这个命令也被淘汰了。
现在虽然创建了模型,但是数据库还没有同步创建完成,我们需要用以下命令同步数据库和模型:
python manage.py makemigrations myapp #用来检测数据库变更和生成数据库迁移文件 python manage.py migrate #用来迁移数据库 python manage.py sqlmigrate myapp 0001 # 用来把数据库迁移文件转换成数据库语言
在命令行依次执行完这三个命令你就可以进行数据访问了。
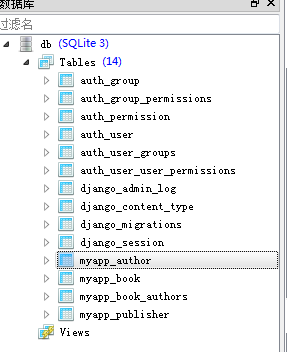
从图可以看出生成了四张表,myapp_author、myapp_book和myapp_publisher这三个表都是我们创建的,但是多出了一个myapp_book_authors表
myapp_book_authors表是我们用在模型下authors = models.ManyToManyField(Author)语句生成的
class Book(models.Model):
authors = models.ManyToManyField(Author)
myapp_book_authors表:

它是models中使用ManyToManyField进行多表关联产生的,里面有两个外键,这让两个实例关联起来才能顺利保存关联关系
基本数据访问
进入django交互式操作
我们先进行出版社的信息的添加
from myapp.models import Publisher
p1 = Publisher(name='Apress', address='2855 Telegraph Avenue',city='Berkeley', state_province='CA', country='U.S.A.',website='http://www.apress.com/')
p1.save()
刷新一下数据库发现值已经成功添加进数据库了

这也可以在交互式操作中体现出来
>>>from myapp.models import Publisher
>>> publisher_list = Publisher.objects.all() >>> publisher_list
<QuerySet [<Publisher: Publisher object (1)>]>
Publisher.objects.all()方法是获取数据库中 “Publisher” 类的所有对象。这个操作的幕后,Django执行了一条SQL “SELECT” 语句。
如果需要一步完成对象的创建与存储至数据库,就使用“objects.create()”方法。 下面的例子与之前的例子等价:
p1 = Publisher.objects.create(name='Apress', address='2855 Telegraph Avenue',city='Berkeley', state_province='CA', country='U.S.A.',website='http://www.apress.com/')
插入数据后,Publisher.objects.all()方法会取出Publisher类的对象,但是却没有得到有用信息
我们可以通过在我们的Publisher类中添加一个名为__str __()的方法来解决这个问题
添加模型字符串表示
分别在每个类下创建__str__()方法用来自定义返回一些你需要的信息
from django.db import models class Publisher(models.Model): name = models.CharField(max_length=30) address = models.CharField(max_length=50) city = models.CharField(max_length=60) state_province = models.CharField(max_length=30) country = models.CharField(max_length=50) website = models.URLField() def __str__(self): return self.name class Author(models.Model): first_name = models.CharField(max_length=30) last_name = models.CharField(max_length=40) email = models.EmailField() def __str__(self): return u'%s %s' % (self.first_name, self.last_name) class Book(models.Model): title = models.CharField(max_length=100) authors = models.ManyToManyField(Author) publisher = models.ForeignKey(Publisher,models.CASCADE) publication_date = models.DateField() def __str__(self): return self.title
TypeError: __str__ returned non-string (type int).
插入和更新数据
你已经知道怎么做了: 先使用一些关键参数创建对象实例,如下:
from myapp.models import Publisher
p = Publisher(name='Apress', address='2855 Telegraph Avenue',city='Berkeley', state_province='CA', country='U.S.A.',website='http://www.apress.com/')
这个对象实例并 没有 对数据库做修改。
在调用 save() 方法之前,记录并没有保存至数据库,像这样: >>> p.save() 在SQL里,这大致可以转换成这样:
INSERT INTO books_publisher (name, address, city, state_province, country, website) VALUES ('Apress', '2855 Telegraph Ave.', 'Berkeley', 'CA', 'U.S.A.', 'http://www.apress.com/');
因为 Publisher 模型有一个自动增加的主键 id ,所以第一次调用 save() 还多做了一件事:
计算这个主键的值并把它赋值给这个对象实例:
>>> p.id 52 # this will differ based on your own data
接下来再调用 save() 将不会创建新的记录,而只是修改记录内容(也就是 执行 UPDATE SQL语句,而不是 INSERT 语句):
>>> p.name = 'Apress Publishing'
>>> p.save() 前面执行的 save() 相当于下面的SQL语句: UPDATE books_publisher SET name = 'Apress Publishing', address = '2855 Telegraph Ave.', city = 'Berkeley', state_province = 'CA', country = 'U.S.A.', website = 'http://www.apress.com' WHERE id = 52;
数据过滤
使用 filter() 方法对数据进行过滤:
>>> Publisher.objects.filter(name='Apress') [<Publisher: Apress>]
filter() 根据关键字参数来转换成 WHERE SQL语句。 前面这个例子 相当于这样:
SELECT id, name, address, city, state_province, country, website FROM books_publisher WHERE name = 'Apress';
你可以传递多个参数到 filter() 来缩小选取范围:
>>> Publisher.objects.filter(country="U.S.A.", state_province="CA") [<Publisher: Apress>]
多个参数会被转换成 AND SQL从句, 因此上面的代码可以转化成这样:
SELECT id, name, address, city, state_province, country, website FROM books_publisher WHERE country = 'U.S.A.' AND state_province = 'CA';
模糊匹配
>>> Publisher.objects.filter(name__contains="press") [<Publisher: Apress>]
在 name 和 contains 之间有双下划线。和Python一样,Django也使用双下划线来表明会进行一些魔术般的操作。这里,contains部分会被Django翻译成LIKE语句:
SELECT id, name, address, city, state_province, country, website FROM books_publisher WHERE name LIKE '%press%';
获取单个对象
上面的例子中 filter() 函数返回一个记录集,这个记录集是一个列表。 相对列表来说,有些时候我们更需要获取单个的对象, get() 方法就是在此时使用的:
>>> Publisher.objects.get(name="Apress") <Publisher: Apress>
这样,就返回了单个对象,而不是列表(更准确的说,QuerySet)。 所以,如果结果是多个对象,会导致抛出异常:
>>> Publisher.objects.get(country="U.S.A.")
Traceback (most recent call last):
...
MultipleObjectsReturned: get() returned more than one Publisher --
it returned 2! Lookup parameters were {'country': 'U.S.A.'}
如果查询没有返回结果也会抛出异常:
Traceback (most recent call last):
...
myapp.models.Publisher.DoesNotExist: Publisher matching query does not exist.
这个 DoesNotExist 异常 是 Publisher 这个 model 类的一个属性,即 Publisher.DoesNotExist。在你的应用中,你可以捕获并处理这个异常,像这样:
try: p = Publisher.objects.get(name='Apress') except Publisher.DoesNotExist: print "Apress isn't in the database yet." else: print "Apress is in the database."
数据排序
在运行前面的例子中,你可能已经注意到返回的结果是无序的。 我们还没有告诉数据库 怎样对结果进行排序,所以我们返回的结果是无序的。
在你的 Django 应用中,你或许希望根据某字段的值对检索结果排序,比如说,按字母顺序。 那么,使用order_by() 这个方法就可以搞定了。
>>> Publisher.objects.order_by("name") [<Publisher: Apress>, <Publisher: O'Reilly>]
跟以前的 all() 例子差不多,SQL语句里多了指定排序的部分:
SELECT id, name, address, city, state_province, country, website FROM books_publisher ORDER BY name;
如果需要以多个字段为标准进行排序(第二个字段会在第一个字段的值相同的情况下被使用到),使用多个参数就可以了,如下:
>>> Publisher.objects.order_by("state_province", "address") [<Publisher: Apress>, <Publisher: O'Reilly>]
我们还可以指定逆向排序,在前面加一个减号 - 前缀:
>>> Publisher.objects.order_by("-name") [<Publisher: O'Reilly>, <Publisher: Apress>]
连锁查询
我们已经知道如何对数据进行过滤和排序。 当然,通常我们需要同时进行过滤和排序查询的操作。 因此,你可以简单地写成这种“链式”的形式:
>>> Publisher.objects.filter(country="U.S.A.").order_by("-name") [<Publisher: O'Reilly>, <Publisher: Apress>]
你应该没猜错,转换成SQL查询就是 WHERE 和 ORDER BY 的组合:
SELECT id, name, address, city, state_province, country, website FROM books_publisher WHERE country = 'U.S.A' ORDER BY name DESC;
限制返回的数据
另一个常用的需求就是取出固定数目的记录。 想象一下你有成千上万的出版商在你的数据库里, 但是你只想显示第一个。 你可以使用标准的Python列表裁剪语句:
>>> Publisher.objects.order_by('name')[0] <Publisher: Apress>
类似的,你可以用Python的range-slicing语法来取出数据的特定子集:
>>> Publisher.objects.order_by('name')[0:2]
注意,不支持Python的负索引(negative slicing)
更新多个对象
调用结果集(QuerySet)对象的update()方法: 示例如下:
>>> Publisher.objects.filter(id=52).update(name='Apress Publishing')
update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录。 以下示例演示如何将所有Publisher的country字段值由’U.S.A’更改为’USA’:
>>> Publisher.objects.all().update(country='USA') 2
update()方法会返回一个整型数值,表示受影响的记录条数。 在上面的例子中,这个值是2。
删除对象
删除数据库中的对象只需调用该对象的delete()方法即可:
>>> p = Publisher.objects.get(name="O'Reilly") >>> p.delete() >>> Publisher.objects.all() [<Publisher: Apress Publishing>]
同样我们可以在结果集上调用delete()方法同时删除多条记录。这一点与我们上一小节提到的update()方法相似:
>>> Publisher.objects.filter(country='USA').delete() >>> Publisher.objects.all().delete() >>> Publisher.objects.all() []
一旦使用all()方法,所有数据将会被删除
本文参考:
https://blog.csdn.net/yy_menghuanjie/article/details/51332075
http://docs.30c.org/djangobook2/chapter05/
https://www.jianshu.com/p/44dfdd6caa7b