一、分组与聚合
在数据分析中,我们有时需要将数据拆分,在每一个特定的组里进行运算
1、实验数据准备
a = pd.read_csv('601318.csv')
a
数据如下:
 实验数据
实验数据2、示例
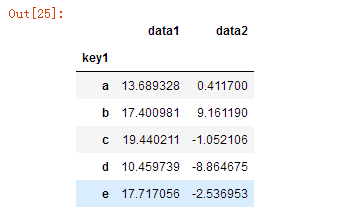
df.groupby('key1').mean()
3、分组与聚合的步骤
分组:拆分数据为若干组
聚合:组内应用某个函数
二、分组
1、按一列分组
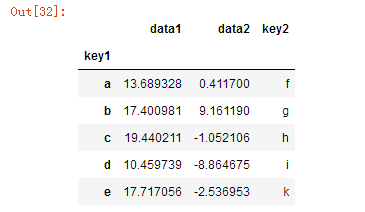
df.groupby('key1').mean()
2、按多列分组
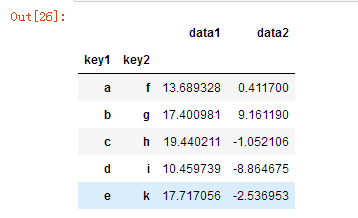
df.groupby(['key1','key2']).mean()
3、自定义分组
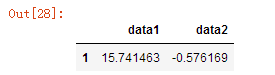
df.groupby(len).mean()

df.groupby(lambda x:len(x)).mean()
4、获取分组信息

df.groupby(lambda x:'zheng' if df.loc[x,'data2']>0 else 'fu').mean()

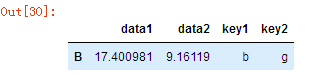
df.groupby('key1').get_group('b')
三、聚合
分组之后需要聚合函数来应用到每一组中
内置聚合函数

1、自定义聚合函数
df.groupby('key1').agg(lambda x:x.max())
2、多个聚合函数

3、不同列应用不同聚合函数
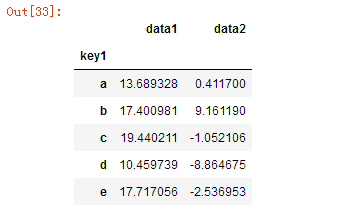
df.groupby('key1').agg({'data1':'min','data2':'max'})
四、数据合并
1、数据拼接
df2 = df.copy() df3 = df.copy()
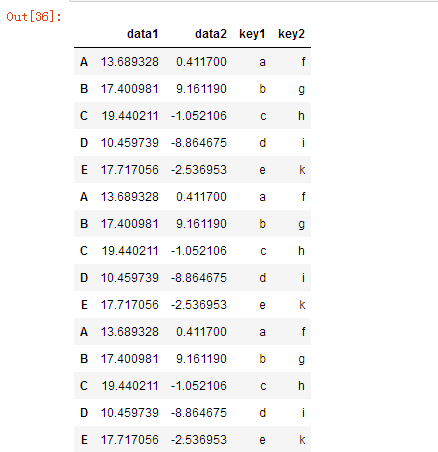
pd.concat([df,df2,df3])
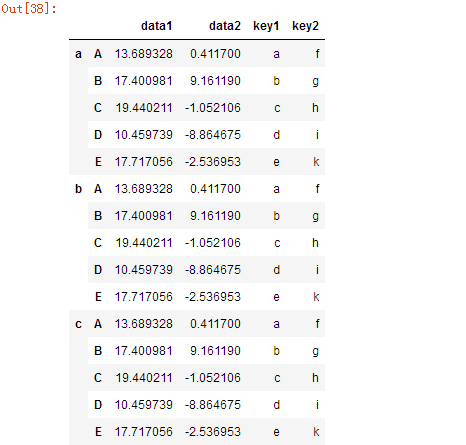
pd.concat([df,df2,df3],keys=list('abc'))
pd.concat([df,df2,df3],ignore_index=True)
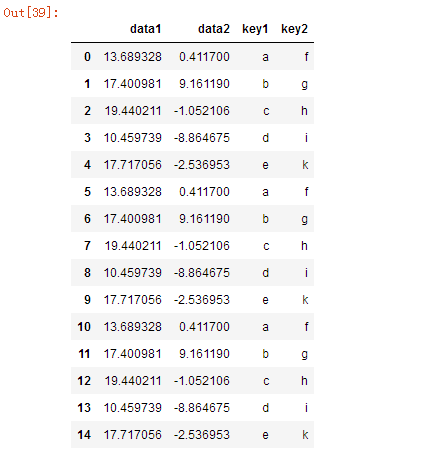
pd.concat([df,df2,df3],axis=1)
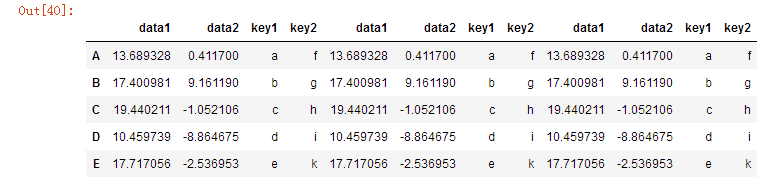
pd.concat([df,df2,df3],axis=1,ignore_index=True)

2、数据连接
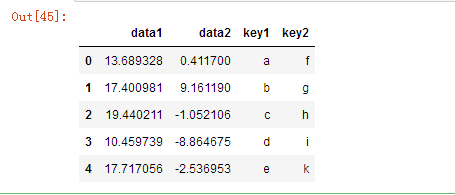
pd.merge(df,df2)

pd.merge(df,df2,on='key1')

pd.merge(df,df2)
pd.merge(df,df2,on=['key1','key2'])
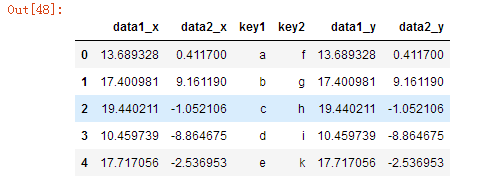
3、合并小结
