在这一节内容开始之前,我们先来看一个3行的小程序。你可以猜一猜,这个程序里的循环1和循环2,运行所花费的时间会差多少?你可以先思考几分钟,然后再看我下面的解释
int[] arr = new int[64 * 1024 * 1024]; // 循环 1 for (int i = 0; i < arr.length; i++) arr[i] *= 3; // 循环 2 for (int i = 0; i < arr.length; i += 16) arr[i] *= 3
在这段Java程序中,我们首先构造了一个64×1024×1024大小的整型数组。在循环1里,我们遍历整个数组,将数组中每一项的值变成了原来的3倍;在循环2里,
我们每隔16个索引访问一个数组元素,将这一项的值变成了原来的3倍。
按道理来说,循环2只访问循环1中1/16的数组元素,只进行了循环1中1/16的乘法计算,那循环2花费的时间应该是循环1的1/16左右。
但是实际上,循环1在我的电脑上运行需要50毫秒,循环2只需要46毫秒。这两个循环花费时间之差在15%之内。
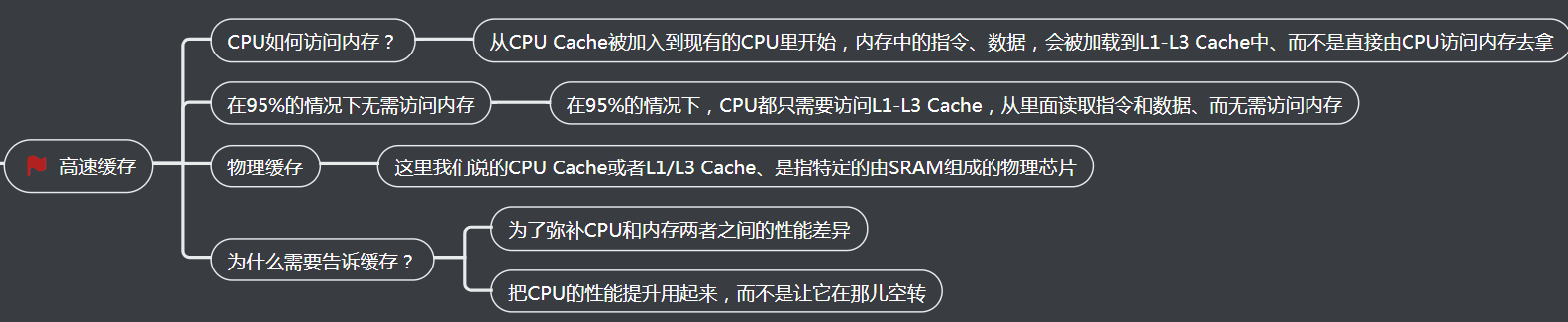
为什么会有这15%的差异呢?这和我们今天要讲的CPU Cache有关。之前我们看到了内存和硬盘之间存在的巨大性能差异。在CPU眼里,内存也慢得不行。
于是,聪明的工程师们就在CPU里面嵌入了CPU Cache(高速缓存),来解决这一问题。
一、我们为什么需要高速缓存?
1、CPU和内存的访问速度
1、已经有了120倍的差距

2、现实生活打个比方

2、高速缓存
3、为什么程序花费了这么多的时间
1、从原理方面

2、日常使用InterlCPU方面

二、Cache的读取过程
1、CPU始终会首先访问Cache

2、CPU等待内存的时间大大变短了
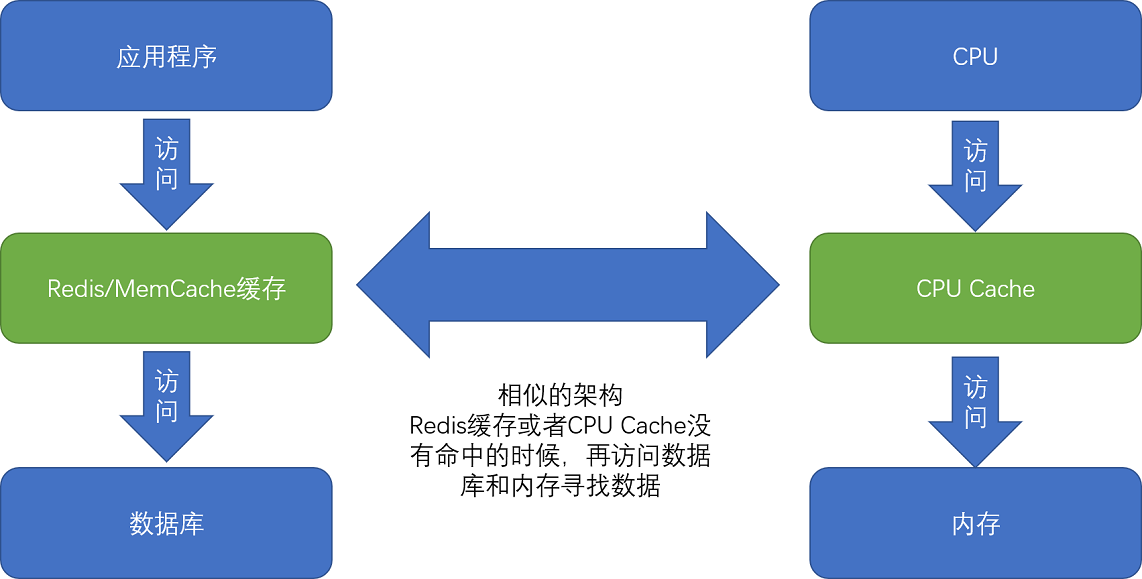

3、CPU如何知道要访问的内存数据

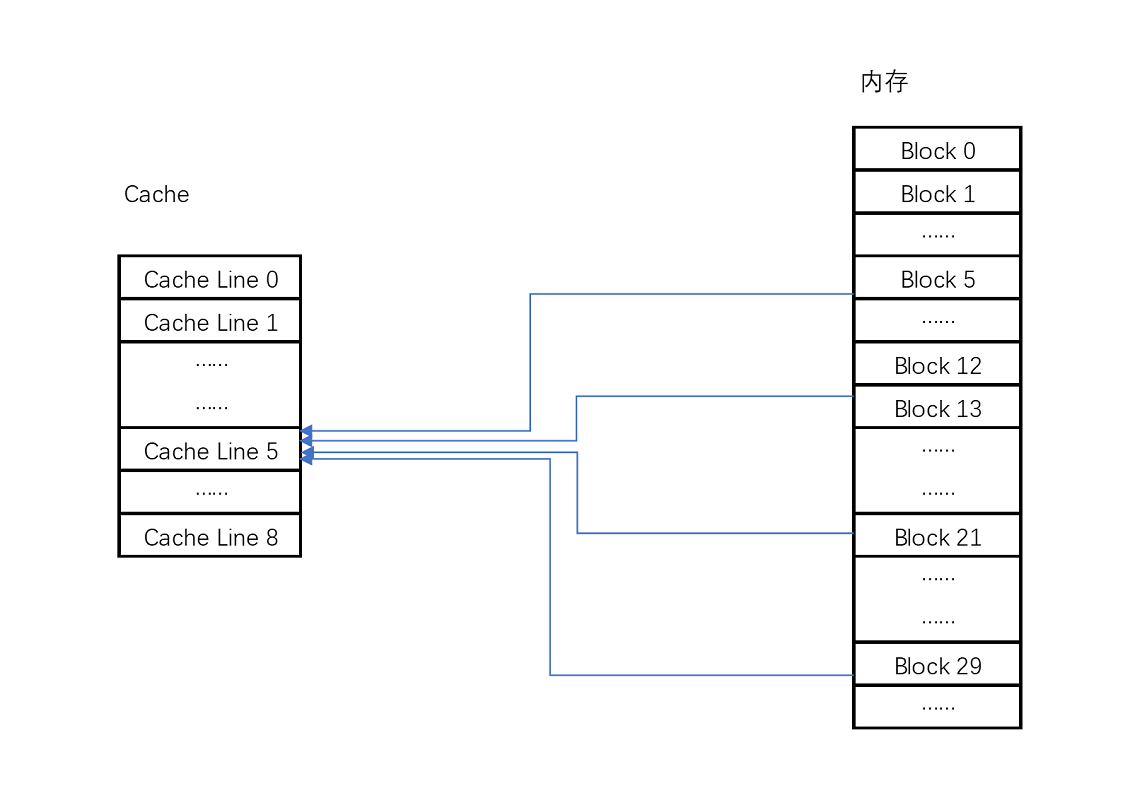
4、映射关系
1、实际计算中
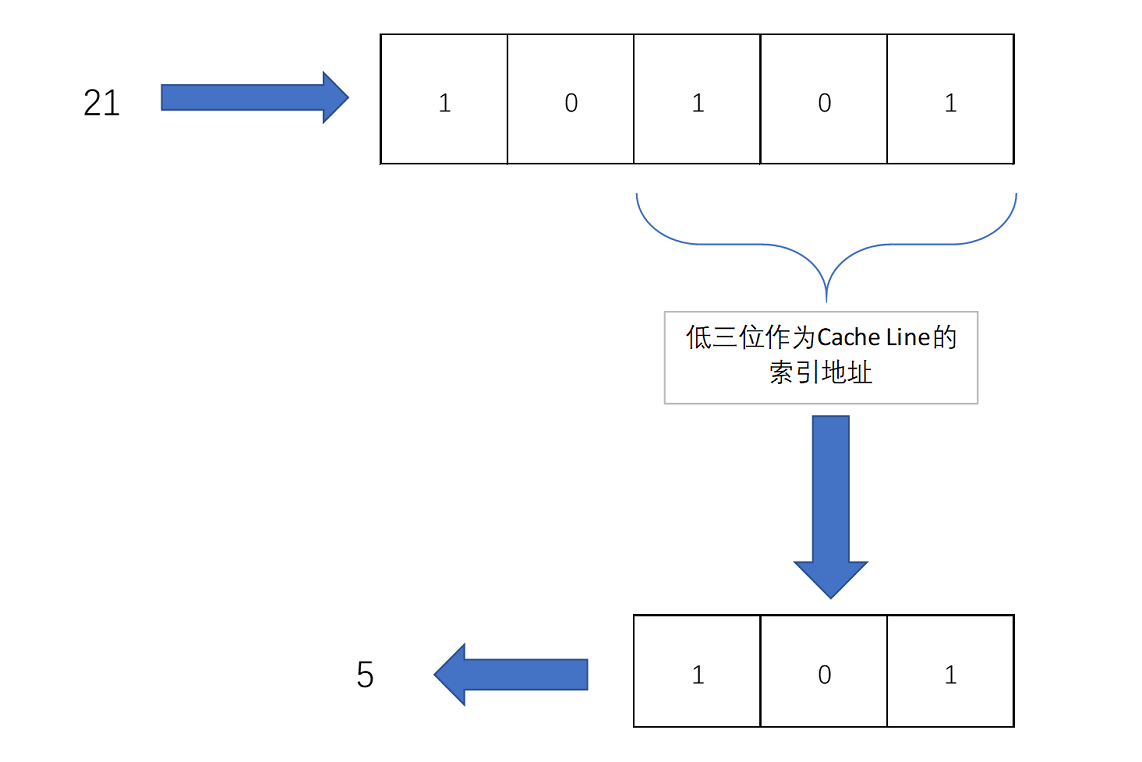
比如说,我们的主内存被分成0~31号这样32个块、我们一共有8个缓存块。用户想要访问第21号内存块
如果21号内存块内容在缓存块中的话,它一定在5号缓存块(21 mod 8 = 5)中
2、举例说明

3、存在的问题

三、Cache的数据结构
1、组标记

2、有效位

3、偏移量

4、一个内存的访问地址

5、内存地址对应到Cache里的数据结构

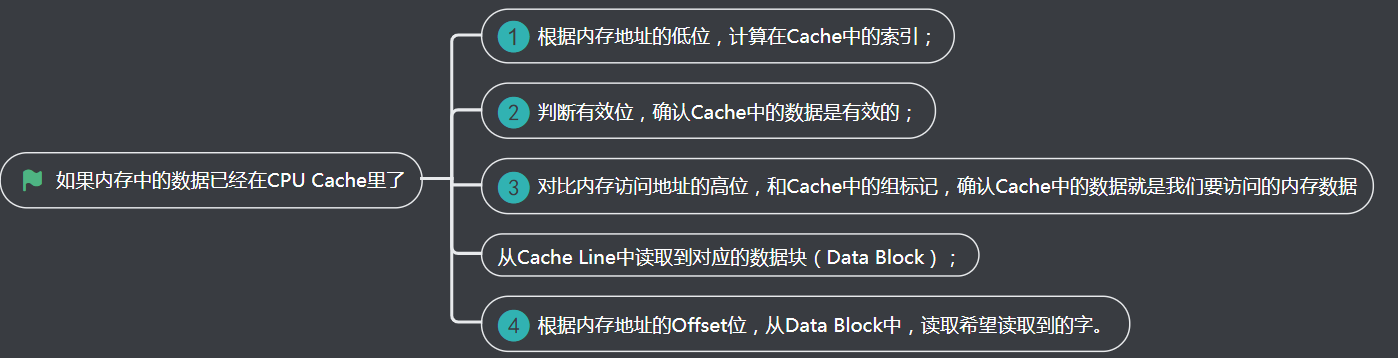
6、如果内存中的数据已经在CPU Cache里了
四、减少4毫秒,公司挣了多少钱?
刚才我花了很多篇幅,讲了CPU和内存之间的性能差异,以及我们如何通过CPU Cache来尽可能解决这两者之间的性能鸿沟。
你可能要问了,这样做的意义和价值究竟是什么?毕竟,一次内存的访问,只不过需要100纳秒而已。1秒钟时间内,足有1000万个100纳秒。
别着急,我们先来看一个故事。
2008年,一家叫作Spread Networks的通信公司花费3亿美元,做了一个光缆建设项目。目标是建设一条从芝加哥到新泽西总长1331公里的光缆线路。建设这条线路的目的,
其实是为了将两地之间原有的网络访问延时,从17毫秒降低到13毫秒。
你可能会说,仅仅缩短了4毫秒时间啊,却花费3个亿,真的值吗?为这4毫秒时间买单的,其实是一批高频交易公司。它们以5年1400万美元的价格,使用这条线路。利用这短短的4毫秒的时间优势,这些公司通过高性能的计算机程序,在芝加哥和新泽西两地的交易所进行高频套利,以获得每年以10亿美元计的利润。现在你还觉得这个不值得吗?
其实,只要350微秒的差异,就足够高频交易公司用来进行无风险套利了。而350微秒,如果用来进行100纳秒一次的内存访问,大约只够进行3500次。
而引入CPU Cache之后,我们可以进行的数据访问次数,提升了数十倍,使得各种交易策略成为可能。
五、总结延伸
很多时候,程序的性能瓶颈,来自使用DRAM芯片的内存访问速度。
根据摩尔定律,自上世纪80年代以来,CPU和内存的性能鸿沟越拉越大。于是,现代CPU的设计者们,直接在CPU中嵌入了使用更高性能的SRAM芯片的Cache,
来弥补这一性能差异。通过巧妙地将内存地址,拆分成“索引+组标记+偏移量”的方式,使得我们可以将很大的内存地址,映射到很小的CPU Cache地址里。
而CPU Cache带来的毫秒乃至微秒级别的性能差异,又能带来巨大的商业利益,十多年前的高频交易行业就是最好的例子。
在搞清楚从内存加载数据到Cache,以及从Cache里读取到想要的数据之后,我们又要面临一个新的挑战了。CPU不仅要读数据,还需要写数据,
我们不能只把数据写入到Cache里面就结束了。下一讲,我们就来仔细讲讲,CPU要写入数据的时候,怎么既不牺牲性能,又能保证数据的一致性。