技巧一:理解指针或引用的含义
1、指针和引用有什么关系

2、代码实现

技巧二:警惕指针丢失和内存泄漏
1、指针是如何弄丢的呢?
我拿单链表的插入操作为例来给你分析一下
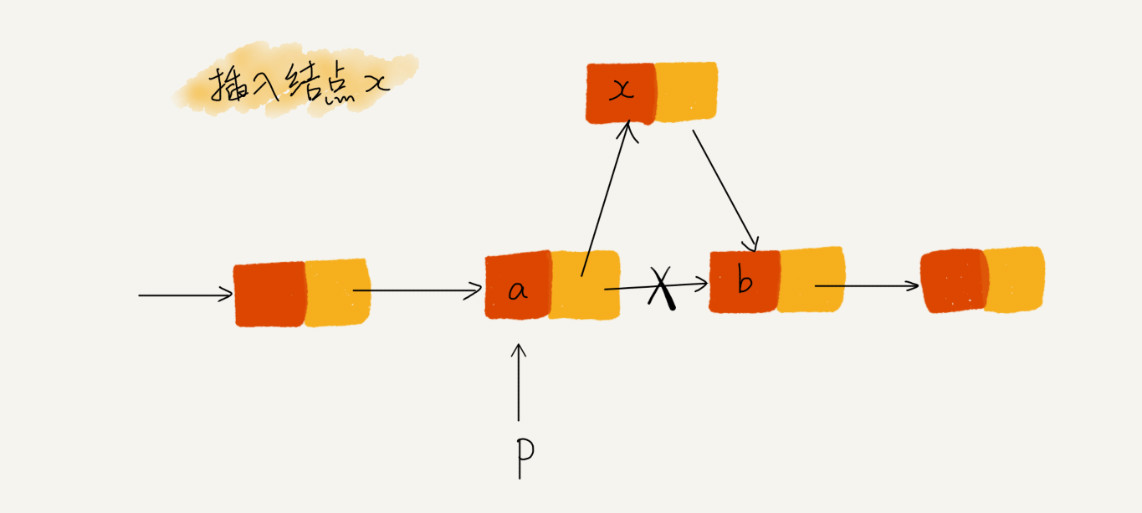
如图所示,我们希望在结点a和相邻的结点b之间插入结点x,假设当前指针p指向结点a。如果我们将代码实现变成下面这个样子,就会发⽣指针丢失和内存泄露。
p->next = x; // 将 p 的 next 指针指向 x 结点; x->next = p->next; // 将 x 的结点的 next 指针指向 b 结点;

2、插入结点时、一定要注意操作的顺序

3、删除链表结点时、一定要手动释放内存空间

技巧三:利用哨兵简化实现难度
1、发现问题
1、在结点P后面插入一个新的结点
new_node->next = p->next; p->next = new_node;
2、向一个空链表中插入第一个结点
刚刚的逻辑就不能用了、需要进行下面这样的特殊处理、其中head表示链表的头结点、对于单链表的插入操作,第一个结点和其他结点的插入逻辑是不一样
if (head == null) {
head = new_node;
}
3、单链表的结点删除操作
如果要删除结点P的后继结点,我们只需要一行代码就可以搞定
p->next = p->next->next;
4、删除链表中的最后一个结点
跟插入类似
if (head->next == null) {
head = null;
}
从前面的一步一步分析,我们可以看出,针对链表的插入、删除操作,需要对插入第一个结点和删除最后一个结点的情况进行特殊处理。这样代码实现起来就会很繁琐,不简洁,而且也容易因为考虑不全而出错。如何来解决这个问题呢?
2、解决问题
1、什么是哨兵

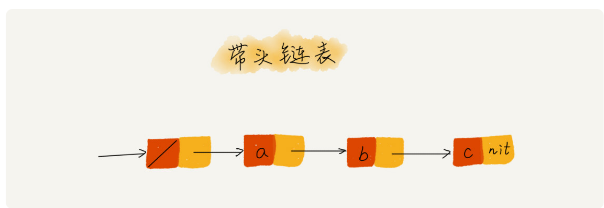
2、带头的链表和不带头的链表

我画了一个带头链表,你可以发现,哨兵结点是不存储数据的。因为哨兵结点一直存在,所以插入第一个结点和插入其他结点,删除最后一个结点和删除其他结点,都可以统一为相同的代码实现逻辑了。
3、哨兵简化了编程的难度

我再举一个非常简单的例子。代码我是用C语言语实现的,不涉及语言方面的高级语法、很容易看懂,你可以类比到你熟悉的语。
代码一
// 在数组 a 中,查找 key,返回 key 所在的位置
// 其中,n 表示数组 a 的长度
int find(char* a, int n, char key) {
// 边界条件处理,如果 a 为空,或者 n<=0,说明数组中没有数据,就不用 while 循环比较了
if(a == null || n <= 0) {
return -1;
}
int i = 0;
// 这里有两个比较操作:i<n 和 a[i]==key.
while (i < n) {
if (a[i] == key) {
return i;
}
++i;
}
return -1;
}
代码二
// 在数组 a 中,查找 key,返回 key 所在的位置
// 其中,n 表示数组 a 的长度
// 我举 2 个例子,你可以拿例子走一下代码
// a = {4, 2, 3, 5, 9, 6} n=6 key = 7
// a = {4, 2, 3, 5, 9, 6} n=6 key = 6
int find(char* a, int n, char key) {
if(a == null || n <= 0) {
return -1;
}
// 这里因为要将 a[n-1] 的值替换成 key,所以要特殊处理这个值
if (a[n-1] == key) {
return n-1;
}
// 把 a[n-1] 的值临时保存在变量 tmp 中,以便之后恢复。tmp=6。
// 之所以这样做的目的是:希望 find() 代码不要改变 a 数组中的内容
char tmp = a[n-1];
// 把 key 的值放到 a[n-1] 中,此时 a = {4, 2, 3, 5, 9, 7}
a[n-1] = key;
int i = 0;
// while 循环比起代码一,少了 i<n 这个比较操作
while (a[i] != key) {
++i;
}
// 恢复 a[n-1] 原来的值, 此时 a= {4, 2, 3, 5, 9, 6}
a[n-1] = tmp;
if (i == n-1) {
// 如果 i == n-1 说明,在 0...n-2 之间都没有 key,所以返回 -1
return -1;
} else {
// 否则,返回 i,就是等于 key 值的元素的下标
return i;
}
}
对比两段代码,在字符串a很⻓的时候,比如几万、几十万,你觉得哪段代码运行得更快点呢?答案是代码二,因为两段代码中执行次数最多就是while循环那一部分。第二段代码中,我们通过⼀个哨兵a[n-1] = key
,成功省掉了一个个⽐较语句i<n,不要小看这一条语句,当累积执行万次、几十万次时,累积的时间就很明显了。
当然,这只是为了举例说明哨兵的作用,你写代码的时候千万不要写第⼆段那样的代码,因为可读性太差了。大部分情况下,我们并不需要如此追求极致的性能。
技巧四:重点留意边界条件处理
1、我们经常用来检查链表代码是否正确的边界条件有这样几个

2、针对不同的场景

技巧五:举例画图、辅助思考
你可以找个个具体的例子,把它画在纸上,释放一些脑容量,留更多的给逻辑思考,这样就会感觉到思路清晰很多。比如往单链表中插入一个数据这样一个操作,我一般都是把各种情况都举一个例子,画
出插入前和插入后的链表变化,如图所示:
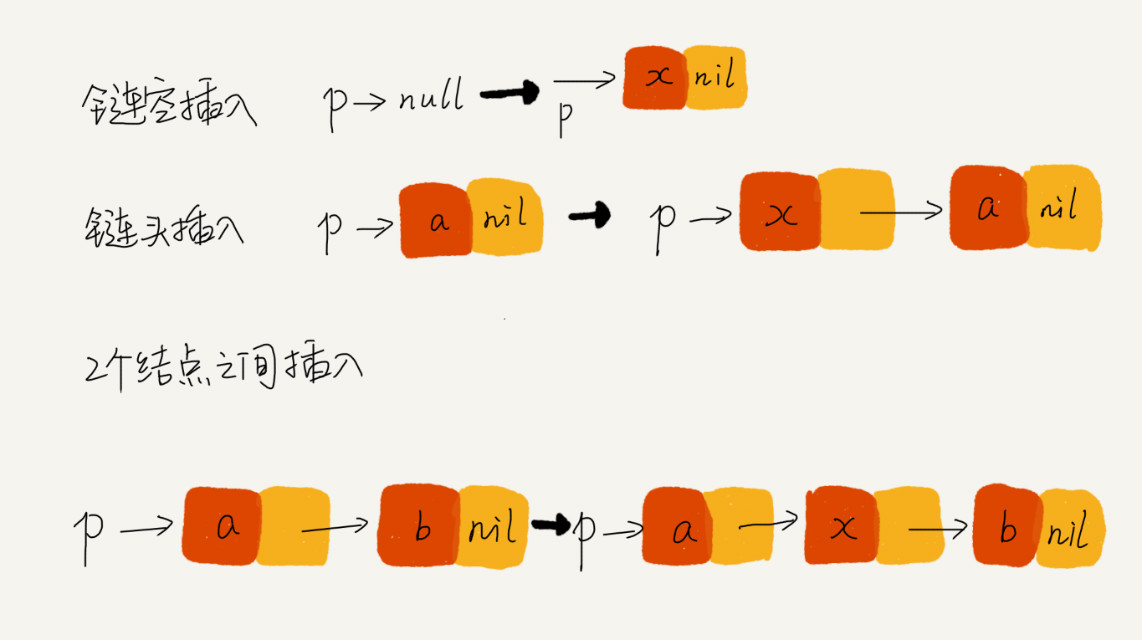
看图写代码,是不是就简单多啦,而且我们写完代码之后,也可以举几个例子、画在纸上,照着代码走一遍,很容易就能发现代码中的Bug
技巧六:多写多练,没有捷径
如果你已经理解并掌握了我前面所讲的方法法,但是手写链表代码还是会出现各种各样的错误,也不要着急。因为我最开始学的时候,这种状况也持续了一段时间。
现在我写这些代码,简直就和“玩儿”一样,其实也没有什么技巧,就是把常见的链表操作都自己多写几遍,出问题就一点一点调试,熟能生巧!
所以,我精选了5个常⻅的链表操作。你只要把这几个操作都能写熟练,不熟就多写几遍,我保证你之后再也不会害怕写链表代码。
- 单链表反转
- 链表中环的检测
- 两个有序的链表合并
- 删除链表倒数第n个结点
- 求链表的中间结点
我觉得写链表代码是最考验逻辑思维能力的,因为链表代码导出都是指针的操作、边界条件的处理,稍有不慎就容易产生Bug链表代码写的好坏,可以看出一个人写代码是否够细心,
考虑问题是否全面、思维是否缜密、所以,这也是很多面试官喜欢让人手写链表代码的原因,所以,这一节讲到的东西,你一定要自己写代码实现一下,才有效果