一、隔离性与隔离级别
1、事务的特性
原子性
一致性
隔离性
持久性
2、不同事务隔离级别的区别
读未提交:别人改数据的事务尚未提交,我在我的事务中也能读到。
读已提交:别人改数据的事务已经提交,我在我的事务中才能读到。
可重复读:别人改数据的事务已经提交,我在我的事务中也不去读。
串行:我的事务尚未提交,别人就别想改数据。
这4种隔离级别,并行性能依次降低,安全性依次提高。
3、读提交”和“可重复读”
假设数据表T中只有一列,期中一行的值为1,下面是按照时间顺序执行两个事物的行为
mysql> create table T(c int) engine=InnoDB; insert into T(c) values(1);
实际测试代码如下:
mysql> create table T(c int) engine=InnoDB; Query OK, 0 rows affected (0.01 sec) mysql> insert into T(c) values(1); Query OK, 1 row affected (0.01 sec)

我们来看看在不同隔离级别下,事务A会有哪些不同的返回结果,也就是图里面V1、V2、V3的返回值分别是什么?
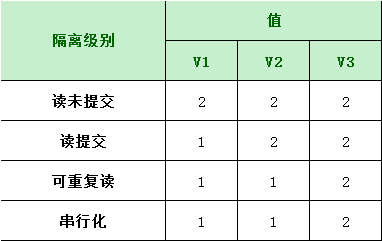
实际测试代码如下
查看隔离级别:
mysql> show variables like 'transaction_isolation'; +-----------------------+-----------------+ | Variable_name | Value | +-----------------------+-----------------+ | transaction_isolation | REPEATABLE-READ | +-----------------------+-----------------+
事务A实际测试代码:
mysql> use test; Database changed mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from T; +------+ | c | +------+ | 1 | +------+ 1 row in set (0.00 sec) mysql> select * from T; +------+ | c | +------+ | 1 | +------+ 1 row in set (0.00 sec) mysql> mysql> select * from T; +------+ | c | +------+ | 1 | +------+ 1 row in set (0.00 sec) mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> select * from T; +------+ | c | +------+ | 2 | +------+ 1 row in set (0.00 sec)
事务B实际测试代码:
mysql> use test; Database changed mysql> begin; Query OK, 0 rows affected (0.00 sec) mysql> select * from T; +------+ | c | +------+ | 1 | +------+ 1 row in set (0.00 sec) mysql> update T set c=5 where id=1; ERROR 1054 (42S22): Unknown column 'id' in 'where clause' mysql> update T set c=2 ; Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 mysql> commit; Query OK, 0 rows affected (0.00 sec)
4、隔离级别的配置方法
Oracle 数据库的默认隔离级别其实就是“读提交”,因此对对于一些从 Oracle 迁移到 MySQL 的应用,为保证数据库隔离级别的一致,你一定要记得将 MySQL 的隔离级别
设置为“读提交”
mysql> show variables like 'transaction_isolation'; +-----------------------+----------------+ | Variable_name | Value | +-----------------------+----------------+ | transaction_isolation | READ-COMMITTED | +-----------------------+----------------+
实际测试代码如下:
mysql> show variables like 'transaction_isolation'; +-----------------------+-----------------+ | Variable_name | Value | +-----------------------+-----------------+ | transaction_isolation | REPEATABLE-READ | +-----------------------+-----------------+ 1 row in set (0.01 sec)
5、可重复读的场景
假设你在管理一个个银行账户表,
1、一个表存了每个月月底的余额,一个表存了账单明细, 2、这时候你要做数据校对,也就是判断上个月的余额和当前余额的差额,是否与本月的账单明细一直 3、你一定希望在校对的过程中,即使有用户发生了一笔新的交易,也不影响你的校队结果
这时候"可重复读"隔离级别就很方便,事务启动时的视图可以认为是静态的,不受其他食物更新的影响
二、事务隔离的实现
1、事务隔离的实现
假设一个值1被按顺序改成2、3、4,在回滚日志里面就会有类似下面的记录
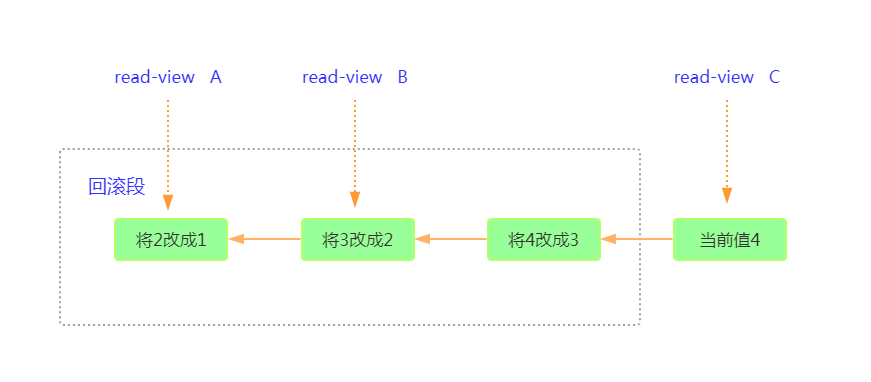
每条记录在更新的时候都会同时记录一条回滚操作。同一条记录在系统中可以存在多个版本,这就是数据库的多版本并发控制(MVCC)
对于read-view A ,要的到1就必须将当前值依次执行途中所有回滚操作的到
2、事务隔离的几个为什么?
1、回滚日志什么时候删除?
系统会判断当没有事务需要用到这些回滚日志的时候,回滚日志会被删除
2、什么时候不需要了?
当系统里没有比这个回滚日志更早的read-view的时候。
3、为什么尽量不要使用长事务
长事务意味着系统里面会存在很老的事务视图,在这个事务提交之前,回滚记录都要保留,这会导致大量占用存储空间。除此之外,长事务还占用锁资源,可能会拖垮库。
三、事务启动方式
1、启动方式
其实很多时候业务开发同学并不是有意使用长事务,挺长是由于误用所致,MySQL 的事务启动方式有以下几种
方式一
显式启动事务语句,begin或者start transaction,提交commit,回滚rollback;
方式一
set autocommit=0,该命令会把这个线程的自动提交关掉。这样只要执行一个select语句,事务就启动,
并不会自动提交,直到主动执行commit或rollback或断开连接
2、建议使用方式一
如果考虑多一次交互问题,可以使用commit work and chain语法。在autocommit=1的情况下用begin显式启动事务,
如果执行commit则提交事务。如果执行commit work and chain则提交事务并自动启动下一个事务。
3、如何查询长事务
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
实际测试代码如下:
mysql> select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60G;
*************************** 1. row ***************************
trx_id: 1806
trx_state: RUNNING
trx_started: 2019-10-15 03:34:50
trx_requested_lock_id: NULL
trx_wait_started: NULL
trx_weight: 2
trx_mysql_thread_id: 6
trx_query: NULL
trx_operation_state: NULL
trx_tables_in_use: 0
trx_tables_locked: 1
trx_lock_structs: 2
trx_lock_memory_bytes: 1136
trx_rows_locked: 1
trx_rows_modified: 0
trx_concurrency_tickets: 0
trx_isolation_level: REPEATABLE READ
trx_unique_checks: 1
trx_foreign_key_checks: 1
trx_last_foreign_key_error: NULL
trx_adaptive_hash_latched: 0
trx_adaptive_hash_timeout: 0
trx_is_read_only: 0
trx_autocommit_non_locking: 0
*************************** 2. row ***************************
trx_id: 421762016601952
trx_state: RUNNING
trx_started: 2019-10-15 03:34:11
trx_requested_lock_id: NULL
trx_wait_started: NULL
trx_weight: 2
trx_mysql_thread_id: 7
trx_query: NULL
trx_operation_state: NULL
trx_tables_in_use: 0
trx_tables_locked: 1
trx_lock_structs: 2
trx_lock_memory_bytes: 1136
trx_rows_locked: 1
trx_rows_modified: 0
trx_concurrency_tickets: 0
trx_isolation_level: REPEATABLE READ
trx_unique_checks: 1
trx_foreign_key_checks: 1
trx_last_foreign_key_error: NULL
trx_adaptive_hash_latched: 0
trx_adaptive_hash_timeout: 0
trx_is_read_only: 0
trx_autocommit_non_locking: 0
2 rows in set (0.00 sec)
ERROR:
No query specified
四、思考题(同学们的经典留言)
1、Gavin同学的形象实例
下面是我的自问自答,也是我的学习笔记,问下斌哥,这样理解准确吗?
在可重复读的隔离级别下,如何理解**当系统里没有比这个回滚日志更早的 read-view 的时候**,这个回滚日志就会被删除?
这也是**尽量不要使用长事务**的主要原因。
比如,在某个时刻(今天上午9:00)开启了一个事务A(对于可重复读隔离级别,此时一个视图read-view A也创建了),这是一个很长的事务……
事务A在今天上午9:20的时候,查询了一个记录R1的一个字段f1的值为1……
今天上午9:25的时候,一个事务B(随之而来的read-view B)也被开启了,它更新了R1.f1的值为2(同时也创建了一个由2到1的回滚日志),这是一个短事务,事务随后就被commit了。
今天上午9:30的时候,一个事务C(随之而来的read-view C)也被开启了,它更新了R1.f1的值为3(同时也创建了一个由3到2的回滚日志),这是一个短事务,事务随后就被commit了。
……
到了下午3:00了,长事务A还没有commit,为了保证事务在执行期间看到的数据在前后必须是一致的,那些老的事务视图、回滚日志就必须存在了,这就占用了大量的存储空间。
源于此,我们应该尽量不要使用长事务。
2、MySQL中undo的内容会被记录到redo中吗?(来自于* 晓 *同学)
作者回复: 对的,是你说的这个流程
3、脏读、幻读、不可重复读(来自于William同学)
1、脏读:
当数据库中一个事务A正在修改一个数据但是还未提交或者回滚,
另一个事务B 来读取了修改后的内容并且使用了,
之后事务A提交了,此时就引起了脏读。
此情况仅会发生在: 读未提交的的隔离级别.
2、不可重复读:
在一个事务A中多次操作数据,在事务操作过程中(未最终提交),
事务B也才做了处理,并且该值发生了改变,这时候就会导致A在事务操作
的时候,发现数据与第一次不一样了。 就是不可重复读。
此情况仅会发生在:读未提交、读提交的隔离级别.
3、幻读
一个事务按相同的查询条件重新读取以前检索过的数据,
却发现其他事务插入了满足其查询条件的新数据,这种现象就称为幻读。
幻读是指当事务不是独立执行时发生的一种现象,例如第一个事务对一个表中的数据进行了修改,比如这种修改涉及到表中的“全部数据行”。同时,第二个事务也修改这个表中的数据,这种修改是向表中插入“一行新数据”。那么,以后就会发生操作第一个事务的用户发现表中还存在没有修改的数据行,就好象发生了幻觉一样.
一般解决幻读的方法是增加范围锁RangeS,锁定检索范围为只读,这样就避免了幻读。
此情况会回发生在:读未提交、读提交、可重复读的隔离级别.
4、形象总结(来自null同学)
视图理解为数据副本,每次创建视图时,将当前『已持久化的数据』创建副本,后续直接从副本读取,从而达到数据隔离效果。
1、存在视图的 2 种隔离级别:
1. 读提交
2. 可重复读
读提交:在每一条 SQL 开始执行时创建视图,隔离作用域仅限该条 SQL 语句。
可重复读:事务启动时创建视图,因此,在事务任意时刻,对记录读取的值都是一样的。
2、其他 2 种无视图的隔离级别:
1. 读未提交
2. 串行化
读未提交:直接返回记录最新值。
串行化:通过读写锁来避免并行访问。
读-读:允许并发执行
读-写:只能串行
写-写:只能串行