读数据过程:
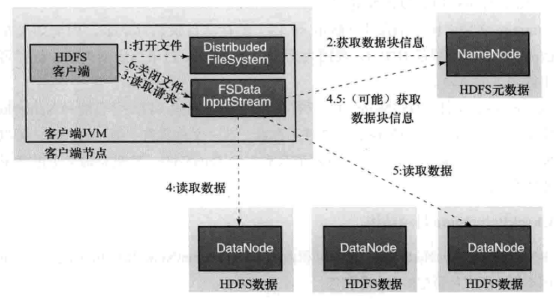
1.客户端调用FileSystem 实例的open 方法,获得这个文件对应的输入流InputStream
2.访问NameNode,获取文件对应数据块的保存位置,包括副本位置。
3.获得输入流之后,客户端便调用read()方法读取数据。选择最近的datanode进行连接并读取数据。
4.如果客户端与一个datanode位于用一台机架,那么直接从本地读取数据。
5.到达数据块末端,关闭与这个datanode的连接,然后重新检查找到下一个数据块。
6.不断执行2-5直到数据完全读完。
7.客户端调用close(),关闭FSDataInutStream。
写数据过程:
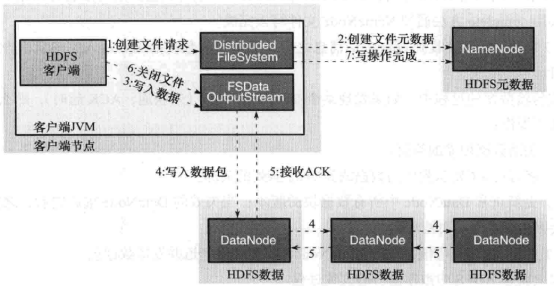
1.客户端调用FileSystem实例的create()方法,创建文件。NameNode 通过一些检查,比如文件是否存在,客户端是否拥有创建权限等;通过检查之后,在NameNode 添加文件信息。注意,因为此时文件没有数据,所以NameNode 上也没有文件数据块的信息。
2.创建结束之后, HDFS 会返回一个输出流DFSDataOutputStream 给客户端
3.客户端调用输出流DFSDataOutputStream 的write 方法向HDFS 中对应的文件写入数据。
4.数据首先会被分块,分块写入一个输出流的内部Data队列中,接受完数据分块,输出流DFSDataOutputStream 会向NameNode 申请保存文件和副本数据块的若干个DataNode , 这若干个DataNode 会形成一个数据传输管道。DFSDataOutputStream 将数据传输给距离上最短的DataNode ,这个DataNode 接收到数据包之后会传给下一个DataNode 。数据在各DataNode之间通过管道流动,而不是全部由输出流分发,以减少传输开销。
5.因为各DataNode 位于不同机器上,数据需要通过网络发送,所以,为了保证所有DataNode 的数据都是准确的,接收到数据的DataNode 要向发送者发送确认包(ACK Packet ) 。对于某个数据块,只有当DFSDataOutputStream 收到了所有DataNode 的正确ACK. 才能确认传输结束。DFSDataOutputStream 内部专门维护了一个等待ACK 队列,这一队列保存已经进入管道传输数据、但是并未被完全确认的数据包。
6.不断执行第3 - 5 步直到数据全部写完,客户端调用close 关闭文件。
7.DFSDataInputStream 继续等待直到所有数据写人完毕并被确认,调用complete 方法通知NameNode 文件写入完成。NameNode 接收到complete 消息之后,等待相应数量的副本写入完毕后,告知客户端。